
Hvis du har brukt Linux en stund, vet du allerede om grep — Global Regular Expression Print, et tekstbehandlingsverktøy som du kan bruke til å søke i filer og kataloger. Det er veldig nyttig i hendene på en Linux-kraftbruker. Men å bruke den uten regulært uttrykk kan begrense mulighetene.
Men hva er Regex?
Regex er regulære uttrykk som du kan bruke til å forbedre grep-søkefunksjonaliteten. Regex, per definisjon, er et avansert utgangsfiltreringsmønster. Med praksis kan du bruke regex effektivt, siden du også kan bruke det med andre Linux-kommandoer.
I opplæringen vår lærer vi hvordan du bruker Grep og Regex effektivt.
Innholdsfortegnelse
Forutsetning
Å bruke grep med regex krever god Linux-kunnskap. Hvis du er nybegynner, så sjekk ut våre Linux-guider.
Du trenger også tilgang til en bærbar PC eller datamaskin som kjører Linux-operativsystemet. Du kan bruke hvilken som helst Linux-distro du ønsker. Og hvis du har en Windows-maskin, kan du fortsatt bruke Linux med WSL2. Sjekk ut vår detaljerte oppfatning av det her.
Tilgang til kommandolinjen/terminalen lar deg kjøre alle kommandoene gitt i vår grep/regex-opplæring.
Videre trenger du også tilgang til en tekstfil(er) som du trenger for å kjøre eksemplene. Jeg brukte ChatGPT til å generere en tekstvegg, og ba den skrive om teknologi. Spørringen jeg brukte er som nedenfor.
«Generer 400 ord om teknologi. Det bør inkludere det meste av teknologi. Pass også på at du gjentar teknologinavn i teksten.»
Når den genererte teksten, kopierte jeg den og lagret den i tech.txt-filen, som vi vil bruke gjennom veiledningen.
Til slutt er en grunnleggende forståelse av grep-kommandoen et must. Du kan sjekke ut 16 eksempler på grep-kommandoer for å oppdatere kunnskapen din. Vi introduserer også grep-kommandoen kort for å komme i gang.
Syntaks og eksempler på grep-kommando
Syntaksen for grep-kommandoen er enkel.
$ grep -options [regex/pattern] [files]
Som du kan legge merke til, forventer den et mønster og listen over filer du vil kjøre kommandoen.
Det er mange tilgjengelige grep-alternativer som endrer funksjonaliteten. Disse inkluderer:
- – i: ignorere tilfeller
- -r: gjør rekursivt søk
- -w: utfør et søk for kun å finne hele ord
- -v: viser alle linjene som ikke samsvarer
- -n: Vis alle samsvarende linjenumre
- -l: skriv ut filnavnene
- –farge: farget resultatutgang
- -c: viser antall kamper for mønsteret som brukes
#1. Søk etter et helt ord
Du må bruke -w-argumentet med grep for et helt ordsøk. Ved å bruke den omgår du alle strenger som samsvarer med det gitte mønsteret.
$ grep -w ‘tech\|5G’ tech.txt
Som du kan se, resulterer kommandoen i en utgang der den søker etter to ord, «5G» og «tech», gjennom hele teksten. Den merker dem deretter med rød farge.
Her er | pipesymbolet escapes slik at grep ikke behandler det som et metategn.
#2. søk uten store og små bokstaver
For å gjøre et søk som ikke skiller mellom store og små bokstaver, bruk grep med -i-argumentet.
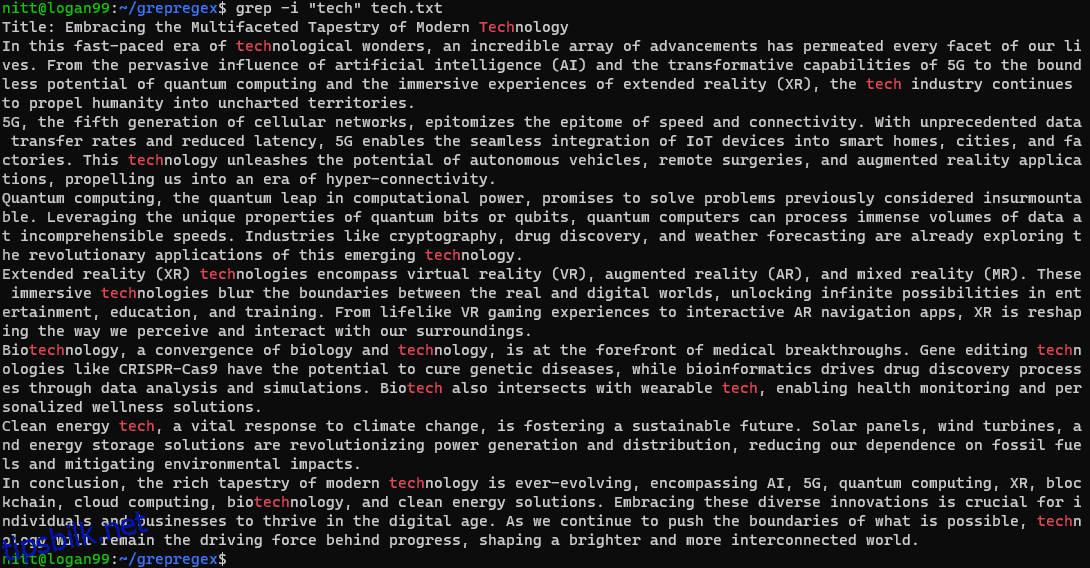
$ grep -i ‘tech’ tech.txt
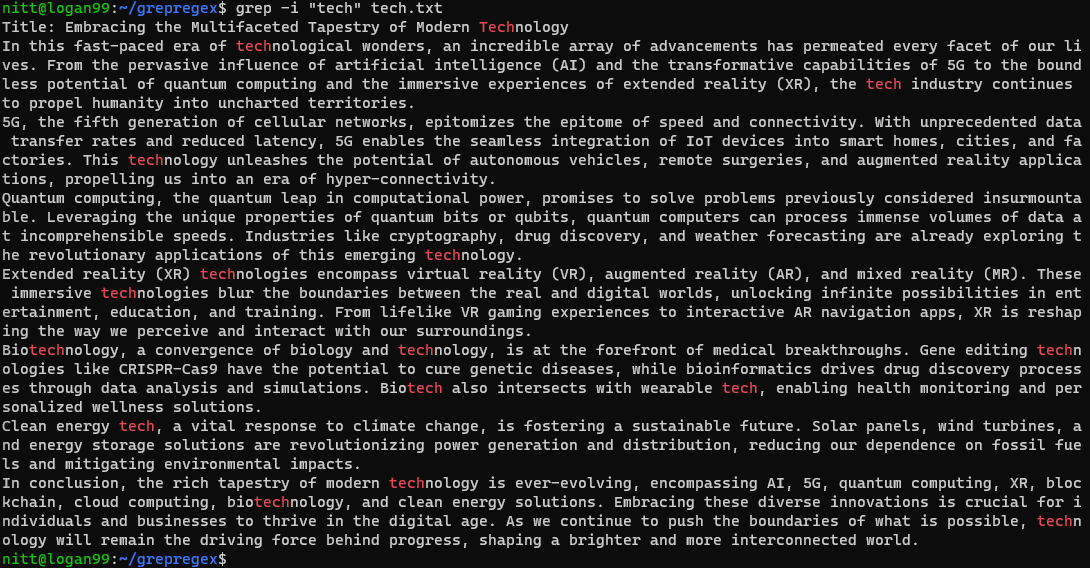
Kommandoen søker etter alle små og store forekomster av «tech»-strengen, enten det er et helt ord eller en del av det.
#3. Gjør et linjesøk som ikke samsvarer
For å vise alle linjene som ikke inneholder et gitt mønster, må du bruke -v-argumentet.
$ grep -v ‘tech’ tech.txt

Utdataene viser alle linjene som ikke inneholder ordet «tech.» Du vil også se tomme linjer. Disse linjene er linjene som er etter et avsnitt.
#4. Gjør et rekursivt søk
For å gjøre et rekursivt søk, bruk -r-argumentet med grep.
$ grep -R ‘error\|warning’ /var/log/*.log
#output /var/log/bootstrap.log:2023-01-03 21:40:18 URL:http://ftpmaster.internal/ubuntu/pool/main/libg/libgpg-error/libgpg-erro 0_1.43-3_amd64.deb [69684/69684] -> "/build/chroot//var/cache/apt/archives/partial/libgpg-error0_1.43-3_amd64.deb" [1] /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: ignoring pre-dependency problem!
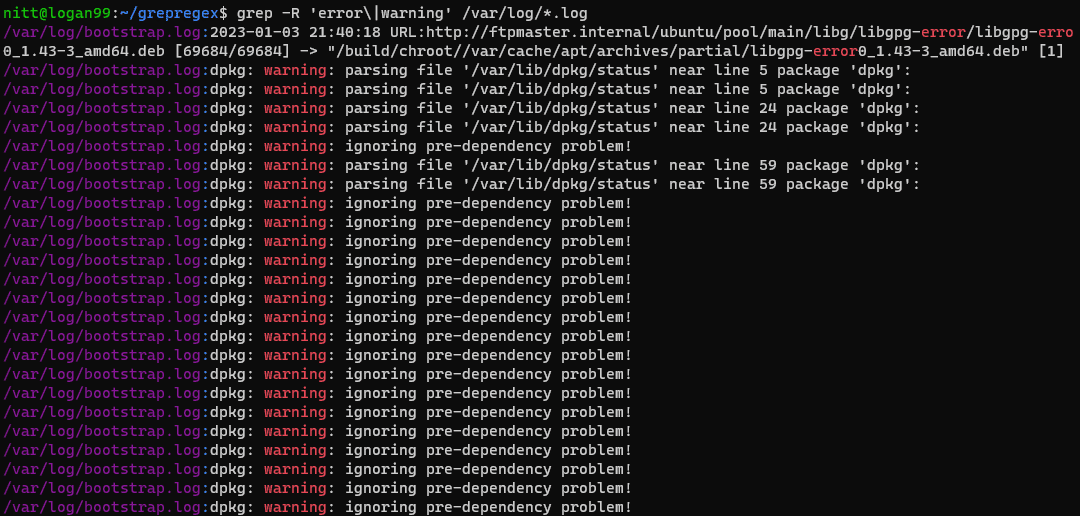
grep-kommandoen søker rekursivt etter to ord, «feil» og «advarsel,» i /var/log-katalogen. Dette er en praktisk kommando for å lære om eventuelle advarsler og feil i loggfilene.
Grep og Regex: Hva det er og eksempler
Når vi jobber med regex, må du vite at regex tilbyr tre syntaksalternativer. Disse inkluderer:
- Grunnleggende regulære uttrykk (BRE)
- Utvidede regulære uttrykk (ERE)
- Pearl-kompatible regulære uttrykk (PCRE)
grep-kommandoen bruker BRE som standardalternativ. Så hvis du vil bruke andre regex-moduser, må du nevne dem. grep-kommandoen behandler også metategn som de er. Så hvis du bruker metategn som ?, +, ), må du unnslippe dem med omvendt skråstrek (\)-kommandoen.
Syntaksen til grep med regex er som nedenfor.
$ grep [regex] [filenames]
La oss se grep og regex i aksjon med eksemplene nedenfor.
#1. Bokstavelige ord samsvarer
For å gjøre en bokstavelig ordmatch, må du oppgi en streng som regulært uttrykk. Tross alt er et ord også et regulært uttrykk.
$ grep "technologies" tech.txt

På samme måte kan du også bruke bokstavelige treff for å finne nåværende brukere. For å gjøre det, løp,
$ grep bash /etc/passwd
#output root:x:0:0:root:/root:/bin/bash nitt:x:1000:1000:,,,:/home/nitt:/bin/bash
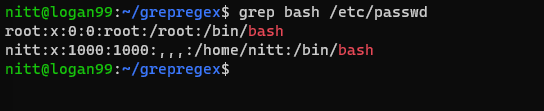
Dette viser brukerne som har tilgang til bashen.
#2. Ankermatching
Ankermatching er en nyttig teknikk for avanserte søk med spesialtegn. I regulært uttrykk er det forskjellige ankertegn som du kan bruke til å representere bestemte posisjoner i en tekst. Disse inkluderer:
- «^»-kart-symbol: Cart-symbolet samsvarer med starten på inndatastrengen eller linjen og ser etter en tom streng.
- «$» dollarsymbol: Dollarsymbolet samsvarer med slutten av inndatastrengen eller linjen og ser etter en tom streng.
De to andre ankermatchende tegnene inkluderer «\ b»-ordgrensen og «\ B» ikke-ordgrense.
- «\ b» ordgrense: Med \b kan du hevde posisjonen mellom et ord og et ikke-ordtegn. Med enkle ord lar den deg matche hele ord. På denne måten kan du unngå delvise kamper. Du kan også bruke den til å erstatte ord eller telle ordforekomster i en streng.
- \B ikke-ordgrense: Det er det motsatte av \b ordgrense i regulært uttrykk da det hevder en posisjon som ikke er mellom to-ord eller ikke-ord tegn.
La oss gå gjennom eksempler for å få en klar idé.
$ grep ‘^From’ tech.txt

Bruk av caret krever at ordet eller mønsteret skrives inn med riktig bokstav. Det er fordi det skiller mellom store og små bokstaver. Så hvis du kjører følgende kommando, vil den ikke returnere noe.
$ grep ‘^from’ tech.txt
På samme måte kan du bruke $-symbolet for å finne setningen som samsvarer med et gitt mønster, streng eller ord.
$ grep ‘technology.$' tech.txt

Du kan kombinere både ^- og $-symboler også. La oss se på eksemplet nedenfor.
$ grep “^From \| technology.$” tech.txt
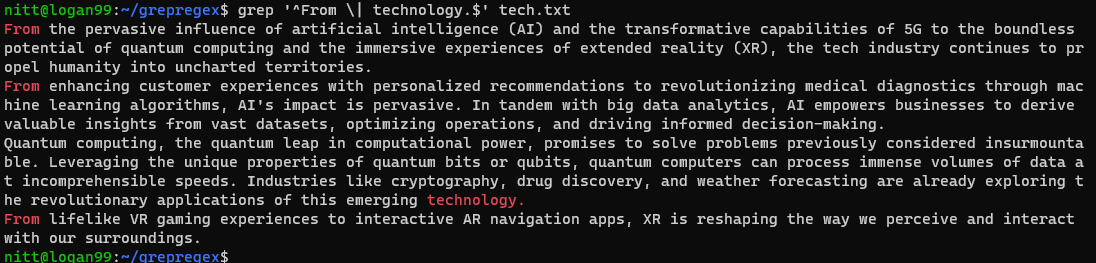
Som du kan se, inneholder utgangen setninger som begynner med «Fra» og setninger som slutter med «teknologi.»
#3. Gruppering
Hvis du ønsker å søke i flere mønstre samtidig, må du bruke gruppering. Det hjelper deg med å lage små grupper av karakterer og mønstre som du kan behandle som en enkelt enhet. Du kan for eksempel opprette en gruppe (tech) som inkluderer termen «t», «e»,» c»,» h.»
For å få en klar idé, la oss ta en titt på et eksempel.
$ grep 'technol\(ogy\)\?' tech.txt

Med gruppering kan du matche gjentatte mønstre, fange grupper og søke etter alternativer.
Alternativt søk med gruppering
La oss se et eksempel på et alternativt søk.
$ grep "\(tech\|technology\)" tech.txt
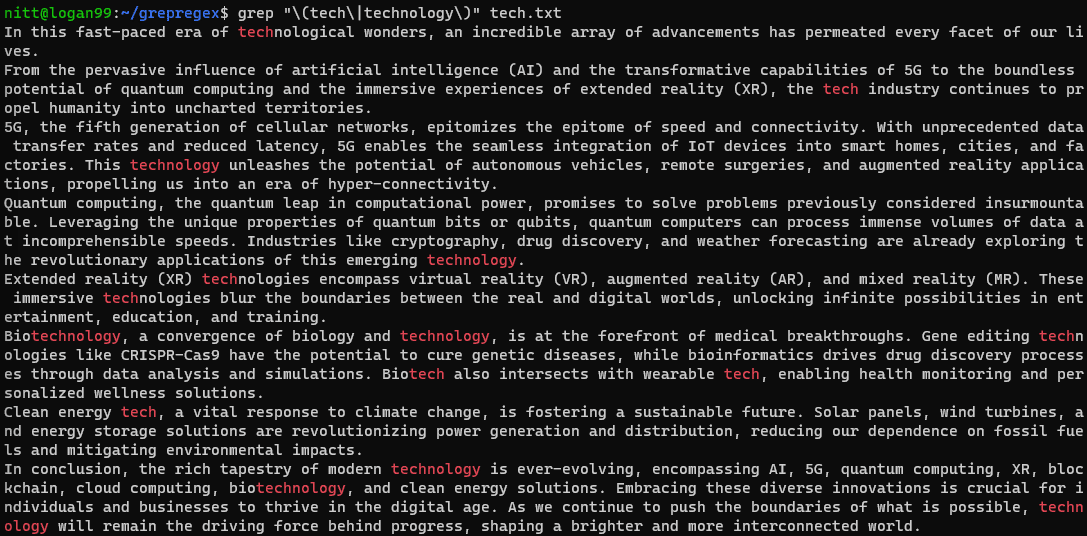
Hvis du vil utføre et søk på en streng, må du sende den med pipesymbolet. La oss se det i eksemplet nedenfor.
$ echo “tech technological technologies technical” | grep "\(tech\|technology\)"
#output “tech technological technologies technical”

Fange grupper, ikke-fangende grupper og gjentatte mønstre
Og hva med å fange og ikke-fange grupper?
Du må opprette en gruppe i regex og sende den til strengen eller en fil for å fange grupper.
$ echo 'tech655 tech655nical technologies655 tech655-oriented 655' | grep "\(tech\)\(655\)"
#output tech655 tech655nical technologies655 tech655-oriented 655

Og for grupper som ikke fanges opp, må du bruke ?: innenfor parentes.
Til slutt har vi gjentatte mønstre. Du må endre regex for å se etter gjentatte mønstre.
$ echo ‘teach tech ttrial tttechno attest’ | grep '\(t\+\)'
#output ‘teach tech ttrial tttechno attest’
Her ser det regulære uttrykket etter en eller flere forekomster av «t»-tegnet.
#4. Karakterklasser
Med karakterklasser kan du enkelt skrive regex-uttrykk. Disse tegnklassene bruker firkantede parenteser. Noen av de kjente karakterklassene inkluderer:
- [:digit:] – 0 til 9 sifre
- [:alpha:] – alfabetiske tegn
- [:alnum:] – alfanumeriske tegn
- [:lower:] – små bokstaver
- [:upper:] – store bokstaver
- [:xdigit:] – heksadesimale sifre, inkludert 0-9, AF, af
- [:blank:] – tomme tegn som tabulator eller mellomrom
Og så videre!
La oss sjekke noen av dem i aksjon.
$ grep [[:digit]] tech.txt

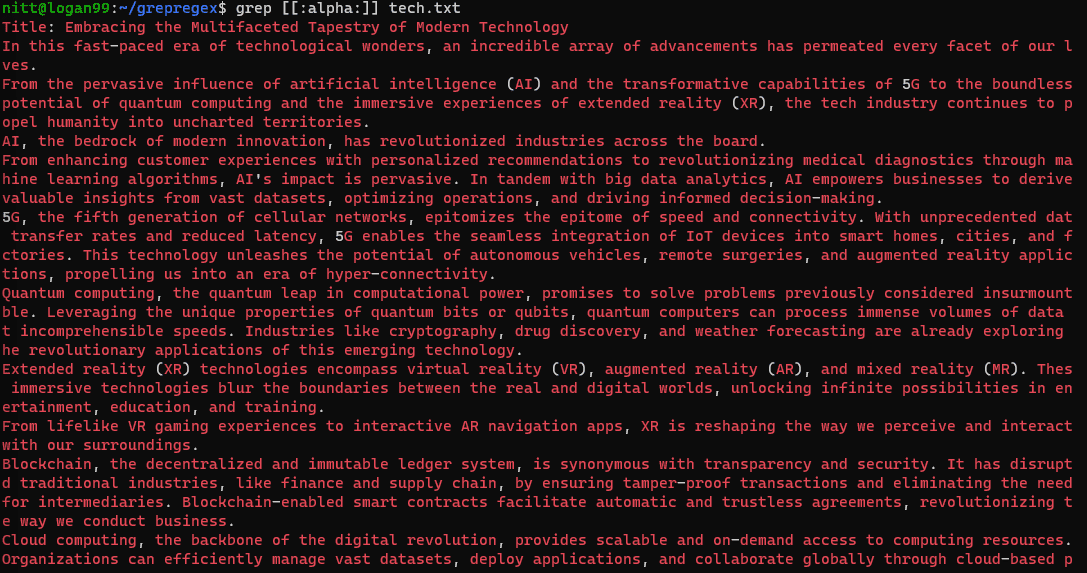
$ grep [[:alpha:]] tech.txt
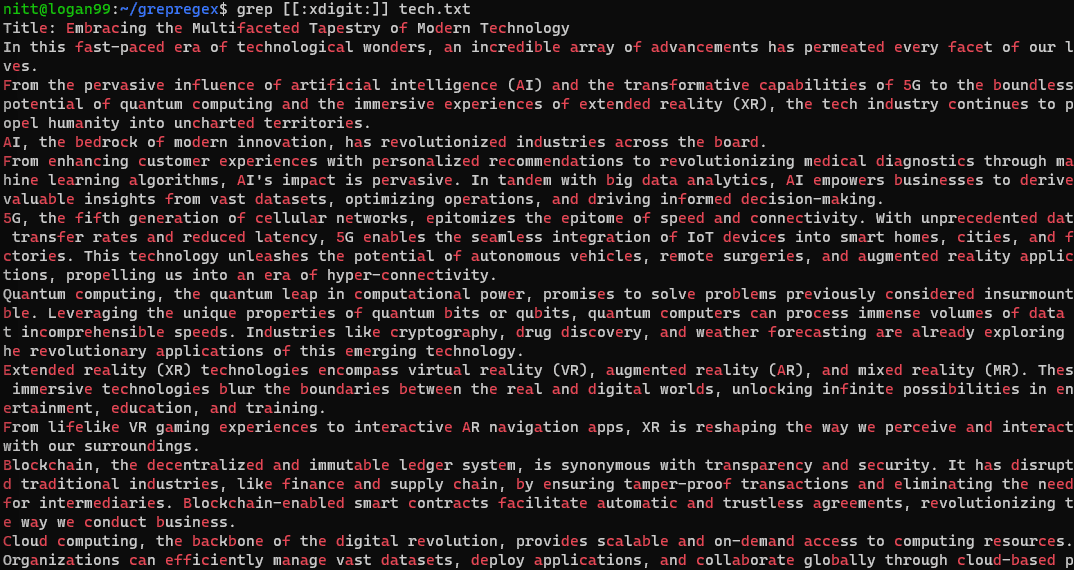
$ grep [[:xdigit:]] tech.txt
#5. Kvantifiserere
Kvantifiserere er metategn og er kjernen i regex. Disse lar deg matche eksakt utseende. La oss se på dem nedenfor.
- * → Null eller flere treff
- + → en eller flere treff
- ? → Null eller ett treff
- {x} → x samsvarer
- {x, } → x eller flere treff
- {x,z} → fra x til z samsvarer
- {, z} → opptil z treff
$ echo ‘teach tech ttrial tttechno attest’ | grep -E 't+'
#output ‘teach tech ttrial tttechno attest’
Her søker den etter «t»-tegnforekomstene for ett eller flere treff. Her står -E for utvidet regex (som vi skal diskutere senere.)

#6. Utvidet regulært uttrykk
Hvis du ikke liker å legge til escape-tegn i regex-mønsteret, må du bruke utvidet regex. Det fjerner behovet for å legge til escape-tegn. For å gjøre det, må du bruke -E-flagget.
$ grep -E 'in+ovation' tech.txt

#7. Bruke PCRE til å gjøre komplekse søk
PCRE (Perl Compatible Regular Expression) lar deg gjøre mye mer enn å skrive grunnleggende uttrykk. For eksempel kan du skrive «\d» som angir [0-9].
Du kan for eksempel bruke PCRE til å søke etter e-postadresser.
echo "Contact me at [email protected]" | grep -P "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"
#output Contact me at [email protected]

Her sørger PCRE for at mønsteret er matchet. På samme måte kan du også bruke et PCRE-mønster for å se etter datomønstre.
$ echo "The Sparkain site launched on 2023-07-29" | grep -P "\b\d{4}-\d{2}-\d{2}\b"
#output The Sparkain site launched on 2023-07-29

Kommandoen finner datoen i formatet ÅÅÅÅ-MM-DD. Du kan endre den for å matche andre datoformater også.
#8. Veksling
Hvis du vil ha alternative treff, kan du bruke de escaped pipe-tegnene (\|).
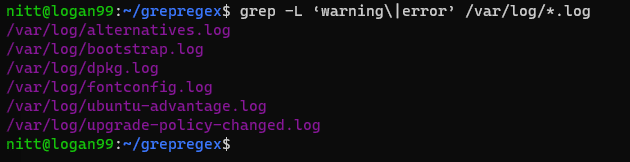
$ grep -L ‘warning\|error’ /var/log/*.log
#output /var/log/alternatives.log /var/log/bootstrap.log /var/log/dpkg.log /var/log/fontconfig.log /var/log/ubuntu-advantage.log /var/log/upgrade-policy-changed.log
Utdataene viser filnavnene som inneholder «advarsel» eller «feil».
Siste ord
Dette fører oss til slutten av vår grep- og regex-guide. Du kan bruke grep med regulært uttrykk mye for å avgrense søk. Med riktig bruk kan du spare mye tid og hjelpe til med å automatisere mange oppgaver, spesielt hvis du bruker dem til å skrive skript eller bruke regulært uttrykk til å søke gjennom teksten.
Deretter kan du sjekke ut ofte stilte Linux-intervjuspørsmål og svar.