I denne artikkelen skal vi utforske vektorisering, en sentral teknikk innenfor feltet naturlig språkbehandling (NLP). Vi vil også belyse viktigheten av vektorisering gjennom en omfattende guide til ulike typer vektoriseringsteknikker.
Tidligere har vi gått gjennom grunnleggende NLP-konsepter og tekstforbehandling. Vi har sett på det fundamentale i NLP, dets varierte bruksområder, og teknikker som tokenisering, normalisering, standardisering, og tekstrensing.

Før vi dykker ned i vektorisering, la oss repetere hva tokenisering er, og hvordan det skiller seg fra vektorisering.
Hva er tokenisering?
Tokenisering er prosessen med å dele opp tekst i mindre enheter, kjent som tokens. Disse tokens hjelper datamaskiner med å analysere og jobbe med tekst på en enklere måte.
Eksempel: «Denne artikkelen er bra»
Tokens: [«Denne», «artikkelen», «er», «bra»]
Hva er vektorisering?
Maskinlæringsmodeller og algoritmer jobber med numerisk data. Vektorisering er en metode for å omforme tekstbasert eller kategorisk informasjon til numeriske vektorer. Denne transformasjonen gjør det mulig å trene modeller mer presist.
Hvorfor trenger vi vektorisering?
Tokenisering og vektorisering har forskjellige roller i NLP. Tokenisering deler setninger i tokens, mens vektorisering konverterer disse tokens til numerisk format, noe som gjør det forståelig for datamaskiner og maskinlæringsmodeller.
Vektorisering er ikke bare nyttig for konvertering til tall, men også for å fange opp semantisk mening.
Vektorisering kan redusere dataens dimensjonalitet, noe som resulterer i mer effektive prosesser. Dette er spesielt nyttig ved håndtering av store datasett.
Mange maskinlæringsalgoritmer, inkludert nevrale nettverk, krever numerisk input. Her spiller vektorisering en viktig rolle.
Det finnes flere vektoriseringsteknikker, som vi skal se nærmere på i denne artikkelen.
Pose med ord
Hvis du har en stor mengde dokumenter eller setninger som skal analyseres, forenkler «pose med ord»-metoden analysen ved å behandle hvert dokument som en beholder fylt med ord.
Denne tilnærmingen er nyttig for tekstklassifisering, sentimentanalyse og informasjonsgjenfinning.
Tenk deg at du jobber med omfattende tekstmateriale. En «pose med ord» vil hjelpe deg med å representere tekstdata ved å lage et vokabular av alle unike ord i teksten. Etter å ha skapt vokabularet, vil hvert ord kodes som en vektor basert på dets frekvens (hvor ofte det forekommer i teksten).
Disse vektorene består av ikke-negative tall (0, 1, 2…), som reflekterer antall forekomster av hvert ord i dokumentet.
Prosessen med «pose med ord» involverer tre trinn:
Trinn 1: Tokenisering
Teksten deles inn i tokens.
Eksempel: (Setning: «Jeg elsker pizza og jeg elsker burgere»)
Trinn 2: Separasjon av unike ord/vokabular
En liste over alle unike ord i setningene lages.
[«Jeg», «elsker», «pizza», «og», «burgere»]
Trinn 3: Telling av ordforekomst/vektoroppretting
Hvert ord fra vokabularet telles, og antall forekomster lagres i en sparsom matrise. Hver rad representerer en setningsvektor, og dens lengde (antall kolonner i matrisen) tilsvarer størrelsen på vokabularet.
Importer CountVectorizer
Vi importerer CountVectorizer for å trene vår «pose med ord»-modell:
from sklearn.feature_extraction.text import CountVectorizer
Lag Vectorizer
Her oppretter vi modellen vår ved hjelp av CountVectorizer og trener den med våre eksempeltekstdokumenter:
# Eksempel tekstdokumenter
documents = [
"Dette er det første dokumentet.",
"Dette dokumentet er det andre dokumentet.",
"Og dette er det tredje.",
"Er dette det første dokumentet?",
]
# Lag en CountVectorizer
cv = CountVectorizer()
# Tilpass og transformer X = cv.fit_transform(documents)
Konverter til en tett matrise
Nå konverterer vi representasjonene våre til en tett matrise. Vi får også funksjonsnavn eller ord.
# Hent funksjonsnavn/ord feature_names = vectorizer.get_feature_names_out() # Konverter til tett matrise X_dense = X.toarray()
La oss skrive ut dokument-term matrisen og funksjonsordene:
# Skriv ut DTM og funksjonsnavn
print("Dokument-Term Matrise (DTM):")
print(X_dense)
print("\nFunksjonsnavn:")
print(feature_names)
Dokument-Term Matrise (DTM):

Funksjonsnavn:

Som du ser, består vektorene av ikke-negative tall (0, 1, 2…), som representerer frekvensen av ord i dokumentet.
Vi har fire eksempeltekstdokumenter, og vi har identifisert ni unike ord fra disse dokumentene. Disse unike ordene er lagret i vokabularet vårt, tilordnet «funksjonsnavn».
Deretter undersøker «pose med ord»-modellen vår om det første unike ordet finnes i vårt første dokument. Hvis det er tilstede, tildeles verdien 1, ellers 0.
Hvis et ord vises flere ganger (for eksempel 2), tildeles en tilsvarende verdi.
I det andre dokumentet gjentas ordet «dokument» to ganger, så verdien i matrisen vil være 2.
Hvis vi vil ha et enkelt ord som en funksjon i vokabularnøkkelen – Unigram representasjon.
n – gram = Unigram, bigram, osv.
Det er mange biblioteker som scikit-learn for å implementere «pose med ord»: Keras, Gensim og andre. Denne teknikken er enkel og kan være nyttig i flere tilfeller.
Men selv om «pose med ord» er raskere, har den sine begrensninger:
- Den tildeler samme vekt til hvert ord, uavhengig av dets betydning. I mange tilfeller er noen ord viktigere enn andre.
- «Pose med ord» teller kun forekomsten av ord. Dette kan føre til en skjevhet mot vanlige ord som «den», «og», «er», som kanskje ikke har mye semantisk verdi.
- Lengre dokumenter kan ha flere ord, som kan skape større vektorer. Dette kan vanskeliggjøre sammenligninger. Det kan skape en sparsom matrise, som ikke er optimal for komplekse NLP-prosjekter.
For å løse disse problemene kan vi vurdere bedre metoder. En av disse er TF-IDF. La oss se nærmere på det.
TF-IDF
TF-IDF, eller Term Frequency – Inverse Document Frequency, er en numerisk representasjon som bestemmer betydningen av ord i et dokument.
Hvorfor trenger vi TF-IDF fremfor «pose med ord»?
En «pose med ord» behandler alle ord likt og fokuserer kun på frekvensen av unike ord i setninger. TF-IDF fremhever ord i et dokument ved å vurdere både frekvens og unikhet.
Ord som forekommer for ofte, overskygger ikke de sjeldnere og mer signifikante ordene.
TF: Term Frequency måler hvor viktig et ord er i en enkelt setning.
IDF: Invers dokumentfrekvens måler hvor viktig et ord er i hele dokumentsamlingen.
TF = Antall ganger ordet forekommer i et dokument / Totalt antall ord i det dokumentet
DF = Antall dokumenter som inneholder ordet m / Totalt antall dokumenter
IDF = log(Totalt antall dokumenter / Antall dokumenter som inneholder ordet w)
IDF er invers av DF. Dette er fordi jo vanligere et ord er i alle dokumentene, desto mindre betydning har det i det spesifikke dokumentet.
Endelig TF-IDF poengsum: TF-IDF = TF * IDF
Dette er en måte å finne ord som er vanlige i et enkelt dokument og unike på tvers av alle dokumenter. Disse ordene kan være nyttige for å finne hovedtemaet i dokumentet.
For eksempel:
Doc1 = «Jeg elsker maskinlæring»
Doc2 = «Jeg elsker tipsbilk.net»
Vi må finne TF-IDF matrisen for dokumentene våre.
Først lager vi et vokabular med unike ord.
Vokabular = [«Jeg», «elsker», «maskin», «læring», «tipsbilk.net»]
Vi har 5 ord. La oss finne TF og IDF for disse ordene.
TF = Antall ganger ordet forekommer i et dokument / Totalt antall ord i det dokumentet
TF:
- For «Jeg» = TF for Doc1: 1/4 = 0.25 og for Doc2: 1/3 ≈ 0.33
- For «elsker»: TF for Doc1: 1/4 = 0.25 og for Doc2: 1/3 ≈ 0.33
- For «maskin»: TF for Doc1: 1/4 = 0.25 og for Doc2: 0/3 ≈ 0
- For «læring»: TF for Doc1: 1/4 = 0.25 og for Doc2: 0/3 ≈ 0
- For «tipsbilk.net»: TF for Doc1: 0/4 = 0 og for Doc2: 1/3 ≈ 0.33
La oss beregne IDF.
IDF = log(Totalt antall dokumenter / Antall dokumenter som inneholder ordet w)
IDF:
- For «Jeg»: IDF er log(2/2) = 0
- For «elsker»: IDF er log(2/2) = 0
- For «maskin»: IDF er log(2/1) = log(2) ≈ 0.69
- For «læring»: IDF er log(2/1) = log(2) ≈ 0.69
- For «tipsbilk.net»: IDF er log(2/1) = log(2) ≈ 0.69
La oss beregne sluttresultatet for TF-IDF:
- For «Jeg»: TF-IDF for Doc1: 0.25 * 0 = 0 og TF-IDF for Doc2: 0.33 * 0 = 0
- For «elsker»: TF-IDF for Doc1: 0.25 * 0 = 0 og TF-IDF for Doc2: 0.33 * 0 = 0
- For «maskin»: TF-IDF for Doc1: 0.25 * 0.69 ≈ 0.17 og TF-IDF for Doc2: 0 * 0.69 = 0
- For «læring»: TF-IDF for Doc1: 0.25 * 0.69 ≈ 0.17 og TF-IDF for Doc2: 0 * 0.69 = 0
- For «tipsbilk.net»: TF-IDF for Doc1: 0 * 0.69 = 0 og TF-IDF for Doc2: 0.33 * 0.69 ≈ 0.23
TF-IDF matrise ser slik ut:
I elsker maskin læring tipsbilk.net
Doc1 0.0 0.0 0.17 0.17 0.0
Doc2 0.0 0.0 0.0 0.0 0.23
Verdier i en TF-IDF matrise forteller hvor viktig hvert begrep er i hvert dokument. Høye verdier indikerer at et begrep er viktig i et bestemt dokument, mens lave verdier antyder at begrepet er mindre viktig eller vanlig i den sammenhengen.
TF-IDF brukes mest i tekstklassifisering, bygging av chatbot, informasjonsgjenfinning og tekstoppsummering.
Importer TfidfVectorizer
La oss importere TfidfVectorizer fra sklearn:
from sklearn.feature_extraction.text import TfidfVectorizer
Lag Vectorizer
Vi lager vår TF-IDF modell ved å bruke TfidfVectorizer.
# Eksempeltekstdokumenter
text = [
"Dette er det første dokumentet.",
"Dette dokumentet er det andre dokumentet.",
"Og dette er det tredje.",
"Er dette det første dokumentet?",
]
# Lag en TfidfVectorizer
cv = TfidfVectorizer()
Lag TF-IDF Matrise
Vi trener modellen vår ved å gi tekst. Deretter konverterer vi den representative matrisen til en tett matrise.
# Tilpass og transformer for å lage TF-IDF matrise X = cv.fit_transform(text)
# Hent funksjonsnavn/ord feature_names = vectorizer.get_feature_names_out() # Konverter TF-IDF matrisen til en tett matrise X_dense = X.toarray()
Skriv ut TF-IDF matrisen og funksjonsordene:
# Skriv ut TF-IDF matrisen og funksjonsord
print("TF-IDF Matrise:")
print(X_dense)
print("\nFunksjonsnavn:")
print(feature_names)
TF-IDF matrise:
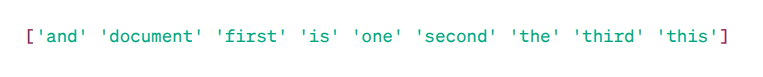
Funksjonsord:
Som du ser, indikerer disse desimaltallene viktigheten av ord i spesifikke dokumenter.
Du kan også kombinere ord i grupper på 2, 3, 4, og så videre ved å bruke n-gram.
Det finnes andre parametere som min_df, max_feature og sublinear_tf.
Hittil har vi utforsket grunnleggende frekvensbaserte teknikker.
Men TF-IDF kan ikke gi semantisk mening og kontekstuell forståelse av tekst.
La oss forstå mer avanserte teknikker som har endret verden av ordinnbygging, og som er bedre for semantisk mening og kontekstuell forståelse.
Word2Vec
Word2vec er en populær teknikk for ordinnbygging (en type ordvektor, nyttig for å fange opp semantisk og syntaktisk likhet) i NLP. Den ble utviklet av Tomas Mikolov og teamet hans hos Google i 2013. Word2vec representerer ord som kontinuerlige vektorer i et flerdimensjonalt rom.
Word2vec har som mål å representere ord på en måte som fanger opp deres semantiske betydning. Ordvektorer generert av Word2vec er plassert i et kontinuerlig vektorrom.
Eksempel: Vektorene for «Katt» og «Hund» vil være nærmere hverandre enn vektorene for «katt» og «jente».
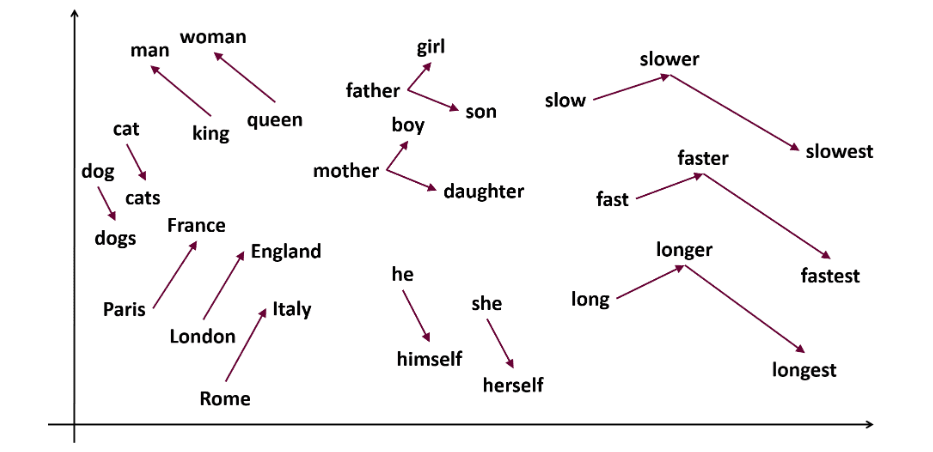
Kilde: usna.edu
To modellarkitekturer kan brukes av Word2vec for å skape ordinnbygginger.
CBOW: Continuous Bag of Words, eller CBOW, prøver å forutsi et ord ved å beregne gjennomsnittet av betydningen av nærliggende ord. Den tar et fast antall eller et vindu med ord rundt målordet, konverterer det til numerisk form (innbygging), beregner gjennomsnittet av alle, og bruker dette gjennomsnittet til å forutsi målordet med et nevralt nettverk.
Eksempel: Forutsi mål: «Rev»
Setningsord: «den», «rask», «brun», «hopper», «over», «den»
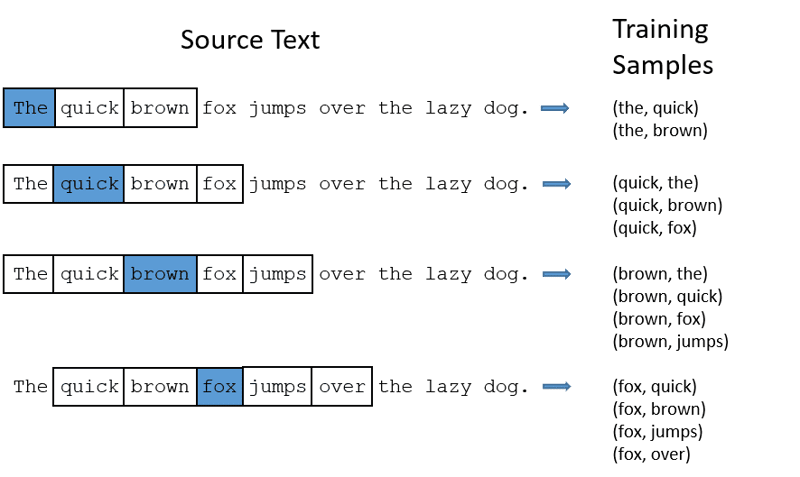
Word2Vec
- CBOW tar et vindu (antall) av ord av fast størrelse, som 2 (2 til venstre og 2 til høyre).
- Konverterer til ordinnbygginger.
- CBOW er gjennomsnittet av ordinnbyggingene.
- CBOW gir et gjennomsnitt av ordinnbyggingen i kontekstordene.
- Den gjennomsnittlige vektoren brukes til å forutsi målordet ved hjelp av et nevralt nettverk.
La oss nå se hvordan skip-gram skiller seg fra CBOW.
Skip-gram: Dette er en ordinnbyggingsmodell, men den fungerer annerledes. I stedet for å forutsi målordet, forutsier skip-gram kontekstordene gitt målordet.
Skip-gram er bedre til å fange de semantiske relasjonene mellom ord.
Eksempel: «Konge – Menn + Kvinner = Dronning»
Hvis du vil jobbe med Word2Vec, har du to alternativer: enten kan du trene din egen modell, eller bruke en forhåndstrent modell. Vi skal bruke en forhåndstrent modell.
Importer gensim
Du kan installere gensim med pip install:
pip install gensim
Tokeniser setningen ved hjelp av word_tokenize:
Først konverterer vi setningene til små bokstaver. Deretter tokeniserer vi setningene ved hjelp av word_tokenize.
# Importer nødvendige biblioteker
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# Eksempelsetninger
sentences = [
"Jeg elsker Thor",
"Hulk er et viktig medlem av Avengers",
"Ironman hjelper Spiderman",
"Spiderman er et av de populære medlemmene av Avengers",
]
# Tokeniser setningene
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]
La oss trene modellen vår:
Vi trener modellen vår ved å gi tokeniserte setninger. Vi bruker et vindu på 5 for denne treningsmodellen, men dette kan tilpasses dine behov.
# Tren en Word2Vec modell
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, sg=0)
# Finn lignende ord
similar_words = model.wv.most_similar("avengers")
# Skriv ut lignende ord
print("Lignende ord til 'avengers':")
for word, score in similar_words:
print(f"{word}: {score}")
Ord som ligner på «avengers»:

Word2Vec likhet
Dette er noen av ordene som ligner på «avengers» basert på Word2Vec-modellen, sammen med deres likhetspoeng.
Modellen beregner en likhetspoeng (for det meste cosinuslikhet) mellom ordvektorene til «avengers» og andre ord i vokabularet. Likhetsskåren indikerer hvor nært beslektede to ord er i vektorrommet.
Eksempel:
Her hjelper ordet «hjelp» med en cosinuslikhet på -0.005911458611011982 med ordet «avengers». Den negative verdien antyder at de kan være forskjellige fra hverandre.
Cosinuslikhetsverdier varierer fra -1 til 1, hvor:
- 1 indikerer at de to vektorene er identiske og har en positiv likhet.
- Verdier nær 1 indikerer høy positiv likhet.
- Verdier nær 0 indikerer at vektorene ikke er sterkt beslektet.
- Verdier nær -1 indikerer høy ulikhet.
- -1 indikerer at de to vektorene er fullstendig motsatte og har en perfekt negativ likhet.
Besøk denne linken hvis du vil ha en bedre forståelse av Word2Vec-modeller og en visuell representasjon av hvordan de fungerer. Det er et veldig nyttig verktøy for å se CBOW og skip-gram i aksjon.
I likhet med Word2Vec har vi GloVe. GloVe kan produsere innbygginger som krever mindre minne sammenlignet med Word2Vec. La oss forstå mer om GloVe.
GloVe
Globale vektorer for ordrepresentasjon (GloVe) er en teknikk i likhet med Word2vec. Den brukes til å representere ord som vektorer i et kontinuerlig rom. Konseptet bak GloVe er det samme som Word2vecs, og produserer kontekstuelle ordinnbygginger samtidig som man tar hensyn til Word2vecs overlegne ytelse.
Hvorfor trenger vi GloVe?
Word2vec er en vindusbasert metode, og den bruker nærliggende ord for å forstå ord. Dette betyr at den semantiske betydningen av målordet kun påvirkes av de omkringliggende ordene i setninger, som er en ineffektiv bruk av statistikk.
GloVe fanger opp både global og lokal statistikk for å lage ordinnbygginger.
Når skal man bruke GloVe?
Bruk GloVe når du vil ha ordinnbygginger som fanger bredere semantiske relasjoner og global ordassosiasjon.
GloVe er bedre enn andre modeller for oppgaver som navngitt enhetsgjenkjenning, ordanalogi og ordlikhet.
Først må vi installere Gensim:
pip install gensim
Trinn 1: Vi installerer viktige biblioteker:
# Importer de nødvendige bibliotekene import numpy as np import matplotlib.pyplot as plt from sklearn.manifold import TSNE import gensim.downloader as api
Trinn 2: Importer GloVe-modellen
import gensim.downloader as api
glove_model = api.load('glove-wiki-gigaword-300')
Trinn 3: Hent vektorordrepresentasjon for ordet «søt»
glove_model["søt"]
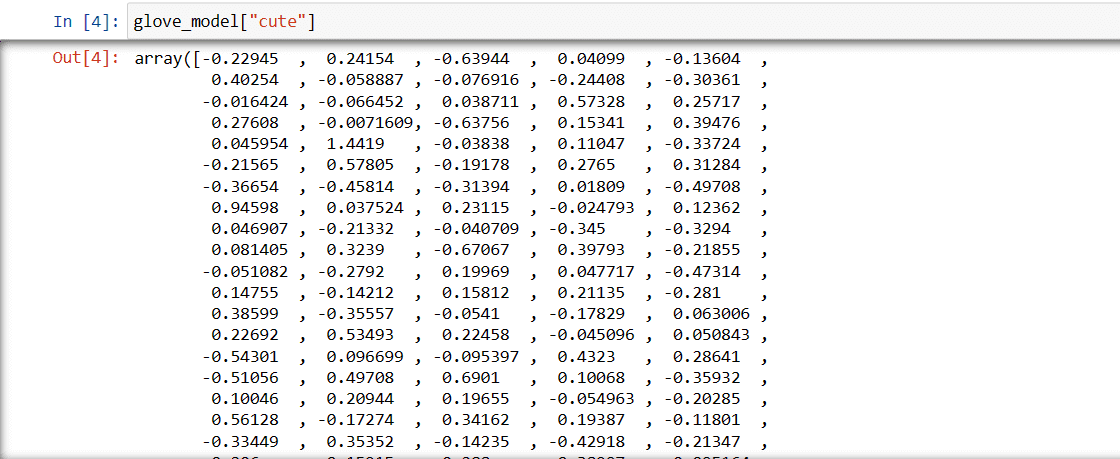
Vektor for ordet «søt»
Disse verdiene fanger opp ordets betydning og forhold til andre ord. Positive verdier indikerer positive assosiasjoner til visse konsepter, mens negative verdier indikerer negative assosiasjoner til andre konsepter.
I en GloVe-modell representerer hver dimensjon i ordvektoren et bestemt aspekt av ordets betydning eller kontekst.
De negative og positive verdiene i disse dimensjonene bidrar til hvor semantisk relatert «søt» er til andre ord i modellens vokabular.
Verdiene kan være forskjellige for ulike modeller. La oss finne noen ord som ligner på ordet «gutt».
Topp 10 lignende ord som modellen mener ligner mest på ordet «gutt».
# Finn lignende ord
glove_model.most_similar("gutt")
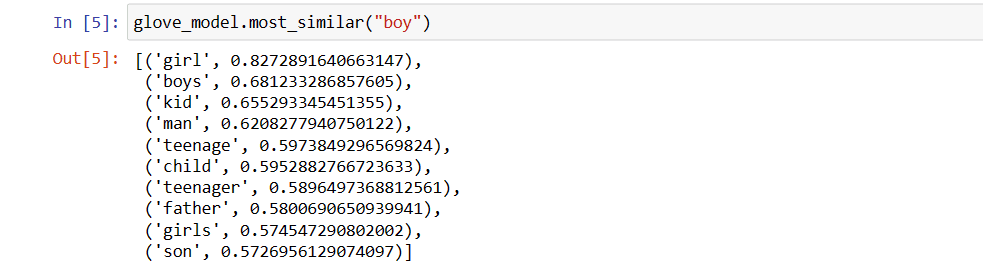
Topp 10 lignende ord som «gutt»
Som du ser, er det mest lignende ordet til «gutt» «jente».
Nå prøver vi å finne ut hvor nøyaktig modellen vil fange den semantiske betydningen av de gitte ordene.
glove_model.most_similar(positive=['gutt', 'dronning'], negative=['jente'], topn=1)

Det mest relevante ordet for «dronning»
Modellen vår klarer å finne et perfekt forhold mellom ord.
Definer ordliste:
La oss nå prøve å forstå den semantiske betydningen eller forholdet mellom ord ved hjelp av et plott. Definer listen over ord du vil visualisere.
# Definer listen over ord du vil visualisere vocab = ["gutt", "jente", "mann", "kvinne", "konge", "dronning", "banan", "eple", "mango", "ku", "kokosnøtt", "appelsin", "katt", "hund"]
Opprett innbyggingsmatrise:
La oss skrive kode for å lage innbyggingsmatrisen.
# Kode for å lage innbyggingsmatrisen
EMBEDDING_DIM = glove_model.vectors.shape[1]
word_index = {word: index for index, word in enumerate(vocab)}
num_words = len(vocab)
embedding_matrix = np.zeros((num_words, EMBEDDING_DIM))
for word, i in word_index.items():
embedding_vector = glove_model[word]
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
Definer en funksjon for t-SNE-visualisering:
Fra denne koden vil vi definere en funksjon for visualiseringsplottet.
def tsne_plot(embedding_matrix, words):
tsne_model = TSNE(perplexity=3, n_components=2, init="pca", random_state=42)
coordinates = tsne_model.fit_transform(embedding_matrix)
x, y = coordinates[:, 0], coordinates[:, 1]
plt.figure(figsize=(14, 8))
for i, word in enumerate(words):
plt.scatter(x[i], y[i])
plt.annotate(word,
xy=(x[i], y[i]),
xytext=(2, 2),
textcoords="offset points",
ha="right",
va="bottom")
plt.show()
La oss se hvordan plottet vårt ser ut:
# Kall tsne_plot-funksjonen med innbyggingsmatris