Datainnsamling fra nettsider
Datainnsamling, også kjent som nettskraping, omfatter prosessen med å hente ut spesifikk informasjon fra nettsider. Dette kan inkludere tekst, bilder, videoer, brukeranmeldelser, produktinformasjon og mer. Slik innsamlet data kan være verdifull for en rekke formål, som markedsundersøkelser, sentimentanalyse, konkurrentovervåkning og datamengdeanalyse.
For mindre datamengder kan manuell datainnsamling være tilstrekkelig. Dette innebærer å kopiere og lime inn ønsket informasjon fra nettsider direkte inn i et regneark eller et annet dokumentformat. For eksempel, hvis en kunde ønsker å sjekke nettbaserte anmeldelser før et kjøp, kan denne prosessen være hensiktsmessig.
Når det gjelder store datamengder, er en automatisert tilnærming nødvendig. Her kan man enten utvikle en intern løsning for datainnsamling eller bruke et Proxy API eller Scraping API. Disse metodene har imidlertid sine begrensninger. Nettsider kan være beskyttet med CAPTCHA-er og kreve avansert håndtering av roboter og proxy-servere. Dette kan føre til et betydelig tidsforbruk og begrense mengden data man kan hente ut.
Scraping Browser: En effektiv løsning
Bright Datas Scraping Browser tilbyr en løsning på disse utfordringene. Denne nettleseren er spesielt utviklet for å håndtere komplekse nettskrapingssituasjoner. Den bruker et grafisk brukergrensesnitt (GUI) og er styrt av Puppeteer eller Playwright API-er, som gjør den vanskelig å oppdage for anti-robot-systemer.
Scraping Browser har integrerte funksjoner for å automatisk håndtere blokkeringer, CAPTCHA-er, fingeravtrykk og gjentatte forsøk. Den opererer på Bright Datas servere, noe som eliminerer behovet for kostbar infrastruktur for å håndtere større prosjekter.
Nøkkelegenskaper ved Bright Data Scraping Browser
- Automatisk opplåsing: Nettleseren tilpasser seg automatisk for å håndtere CAPTCHA-løsning, nye blokkeringer, fingeravtrykk og gjentatte forsøk, og etterligner en ekte bruker.
- Omfattende proxy-nettverk: Tilgang til over 72 millioner IP-adresser, som gir muligheten til å målrette mot spesifikke land, byer eller nettverksleverandører.
- Skalerbarhet: Håndterer tusenvis av samtidige økter gjennom Bright Data sin infrastruktur.
- Kompatibilitet: Fungerer sømløst med Puppeteer (Python) og Playwright (Node.js) for API-integrasjon og henting av et stort antall nettleserøkter.
- Tids- og ressursbesparende: Eliminerer behovet for manuell proxy-konfigurasjon og intern infrastruktur.
Hvordan sette opp Scraping Browser
- Gå til Bright Data sin nettside og velg «Scraping Browser» under «Scraping Solutions».
- Opprett en konto. Du kan velge mellom «Start gratis prøveversjon» eller «Start gratis med Google». Velg «Start gratis prøveversjon» for denne gjennomgangen.
- Når kontoen er opprettet, velg «Fullmakter og skrapingsinfrastruktur» fra dashbordet.
- I det nye vinduet velger du Scraping Browser og klikker på «Kom i gang».
- Lagre og aktiver konfigurasjonene.
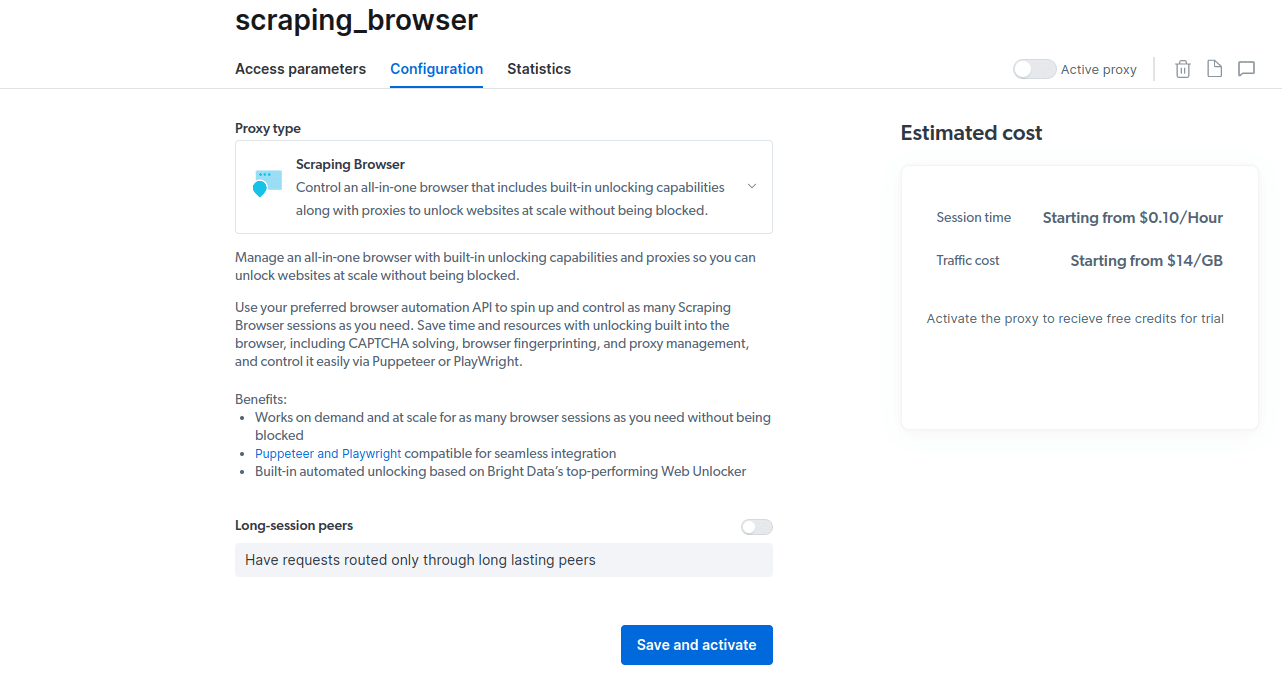
- Aktiver din gratis prøveperiode. Du får en kreditt på $5 for proxy-bruk. Du kan også velge et alternativ med $50 i gratis kreditt dersom du lader kontoen med $50 eller mer.
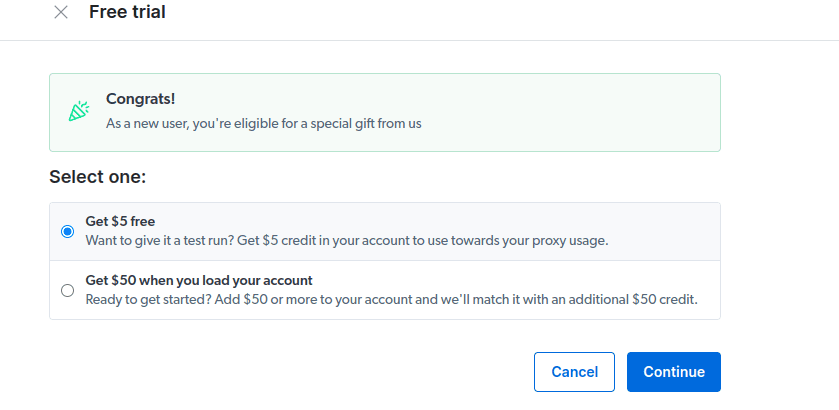
- Fyll inn faktureringsinformasjon. Plattformen vil ikke belaste deg, informasjonen er kun for å verifisere at du er en ny bruker.
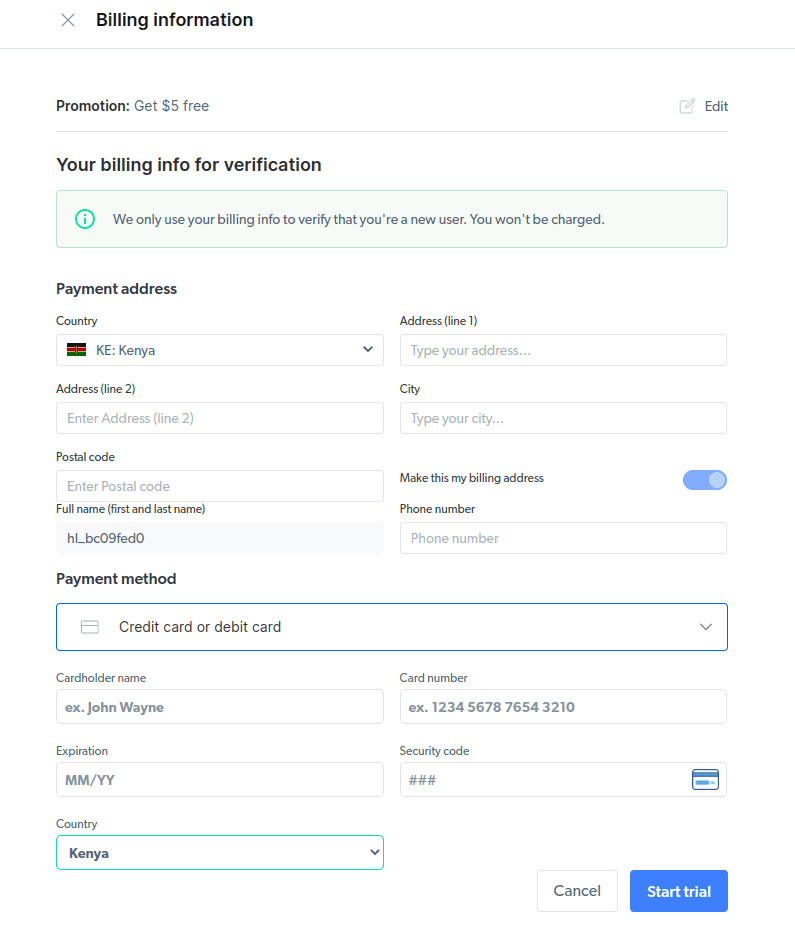
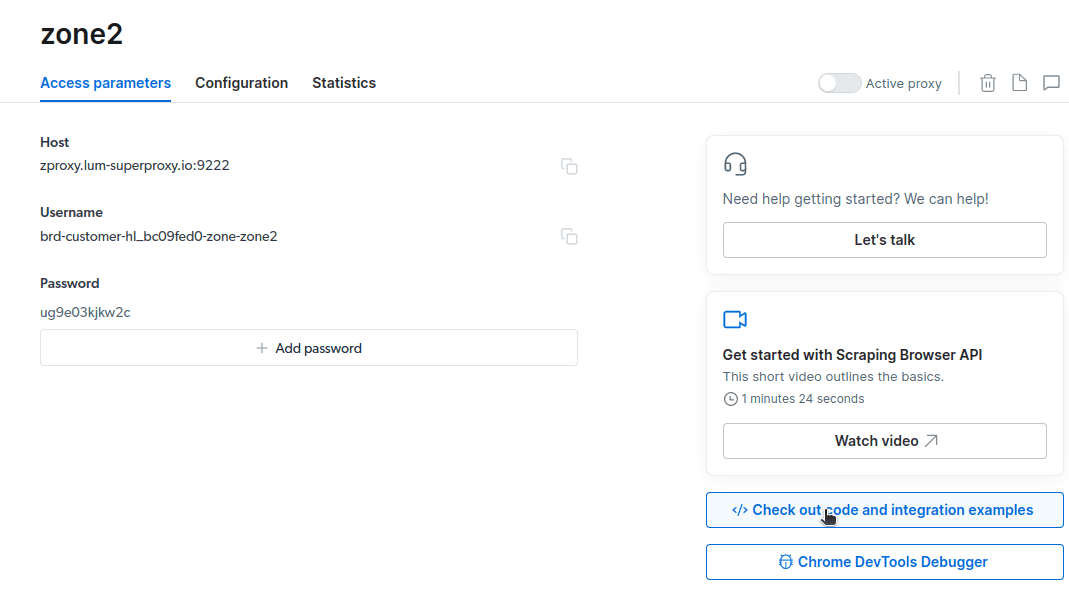
- Opprett en ny proxy. Velg «Legg til» og velg Scraping Browser som «Proxy-type».
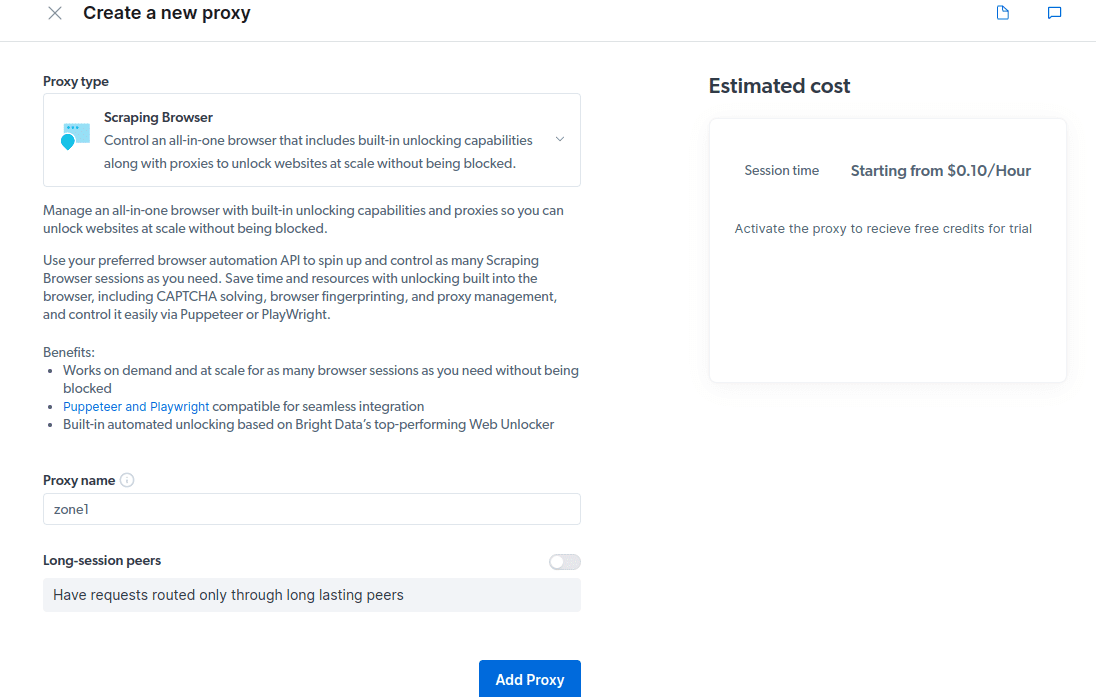
- Opprett en ny «sone» når popup-vinduet vises.
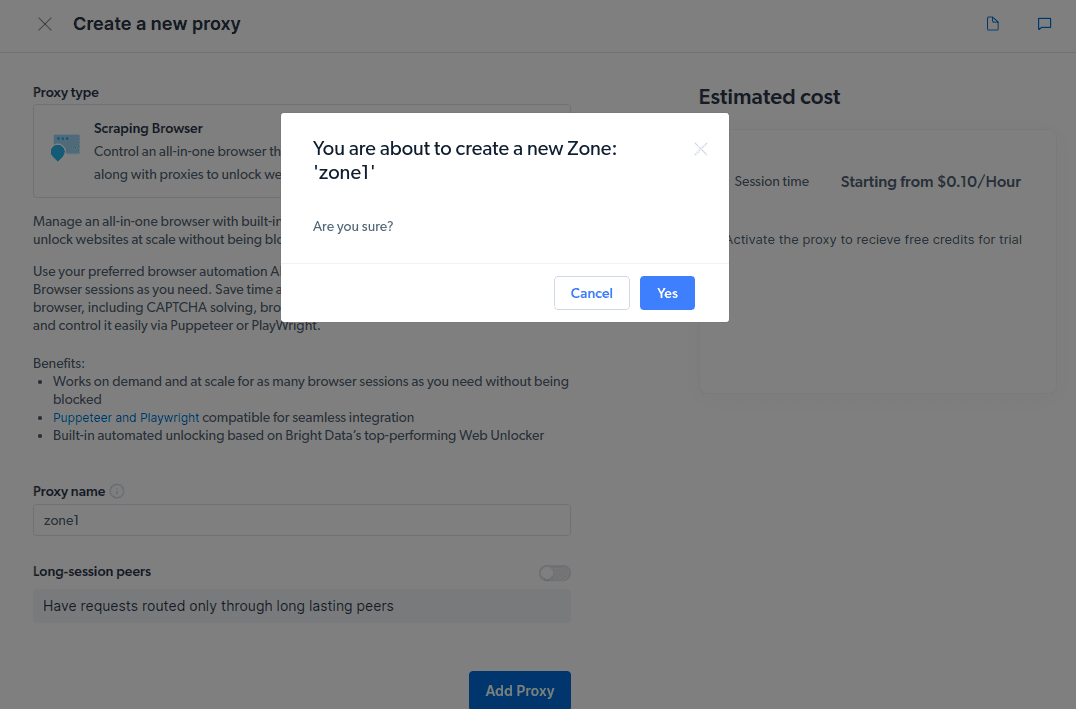
- Klikk på «Sjekk kode og integrasjonseksempler». Her finner du eksempler på proxy-integrering for å hente data fra nettsiden du ønsker. Du kan bruke Node.js eller Python.
Nå er du klar for å begynne å hente data fra nettsider. For demonstrasjonsformål skal vi bruke nettstedet tipsbilk.net.com og Node.js.
Følg disse trinnene:
- Opprett et nytt prosjekt på din lokale maskin. Naviger til mappen og lag en ny fil kalt script.js.
- Åpne prosjektet i din favoritt koderedigerer (f.eks. VsCode).
- Installer Puppeteer ved å kjøre kommandoen: npm i puppeteer-core
- Legg til følgende kode i script.js-filen:
const puppeteer = require('puppeteer-core'); // should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>' const auth="USERNAME:PASSWORD"; async function run(){ let browser; try { browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`}); const page = await browser.newPage(); page.setDefaultNavigationTimeout(2*60*1000); await page.goto('https://example.com'); const html = await page.evaluate(() => document.documentElement.outerHTML); console.log(html); } catch(e) { console.error('run failed', e); } finally { await browser?.close(); } } if (require.main==module) run(); - Endre innholdet i
const auth=’BRUKERNAVN:PASSORD’;med dine kontoopplysninger. Brukernavn, sonenavn og passord finnes under fanen «Tilgangsparametere». - Endre mål-URL. For dette eksemplet skal vi hente data om alle forfatterne på tipsbilk.net.com, som finnes på https://tipsbilk.net.com/authors/. Endre koden i linje 10 til:
await page.goto('https://tipsbilk.net.com/authors/'); - Den endelige koden vil se slik ut:
const puppeteer = require('puppeteer-core'); // should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>' const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c"; async function run(){ let browser; try { browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`}); const page = await browser.newPage(); page.setDefaultNavigationTimeout(2*60*1000); await page.goto('https://tipsbilk.net.com/authors/'); const html = await page.evaluate(() => document.documentElement.outerHTML); console.log(html); } catch(e) { console.error('run failed', e); } finally { await browser?.close(); } } if (require.main==module) run(); - Kjør koden med kommandoen: node script.js
Du vil se HTML-koden i terminalen.
Hvordan eksportere data
Det er flere måter å eksportere data, avhengig av bruksområdet. For dette eksemplet vil vi eksportere dataen til en HTML-fil ved å endre skriptet slik at det oppretter en ny fil kalt data.html i stedet for å skrive ut resultatet til konsollen.
Endre koden din som følger:
const puppeteer = require('puppeteer-core');
const fs = require('fs');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://tipsbilk.net.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
// Write HTML content to a file
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
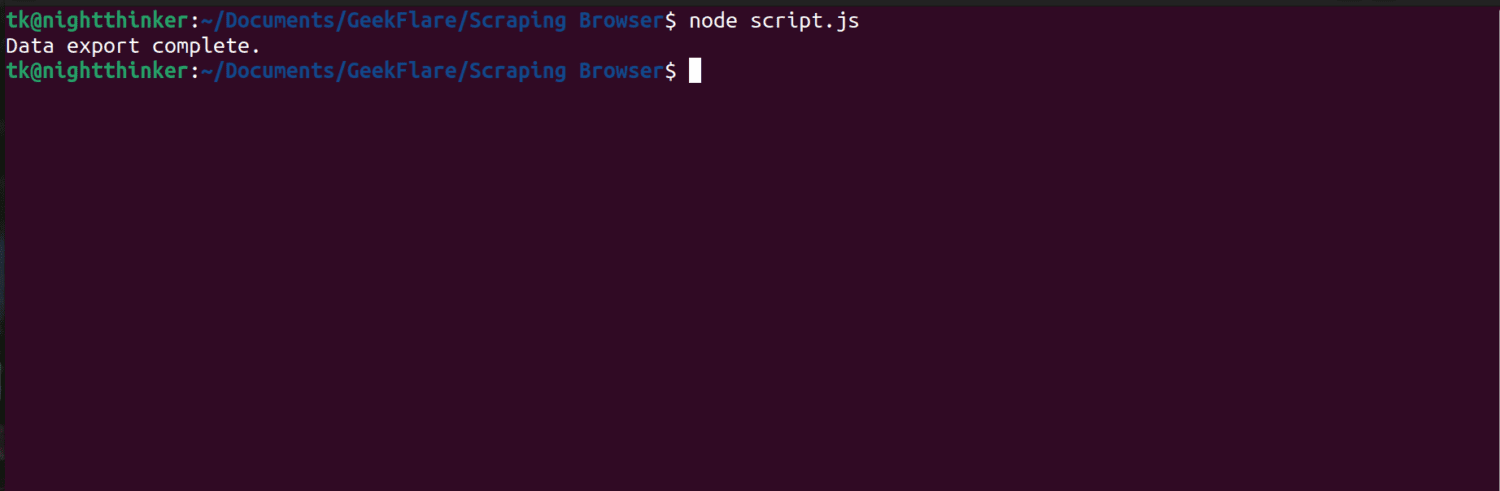
Kjør koden med kommandoen: node script.js
Terminalen vil vise en melding som sier «dataeksport fullført».
Du vil nå se en fil kalt data.html i prosjektmappen din med den hentede HTML-koden.
Dette er bare en innføring i hvordan du kan bruke Scraping Browser for å hente ut data. Du kan tilpasse koden for å hente ut spesifikk informasjon, som f.eks. forfatternavn og beskrivelser.
For å bruke Scraping Browser effektivt, identifiser de spesifikke dataene du trenger og modifiser koden. Du kan hente ut tekst, bilder, videoer, metadata og lenker, avhengig av nettsiden og dens struktur.
Ofte stilte spørsmål
Er datainnsamling og nettskraping lovlig?
Nettskraping er et omdiskutert tema, med delte meninger om hvorvidt det er moralsk akseptabelt. Lovligheten avhenger av innholdet som skal skrapes og retningslinjene på den aktuelle nettsiden. Generelt anses skraping av personlig informasjon, som adresser og økonomiske detaljer, som ulovlig. Sjekk alltid retningslinjene til nettsiden før du starter skrapingen, og sørg for at du ikke henter ut data som ikke er offentlig tilgjengelig.
Er Scraping Browser et gratis verktøy?
Nei, Scraping Browser er en betalt tjeneste. En gratis prøveperiode inkluderer en kreditt på $5. Betalte abonnementer starter fra $15/GB + $0,1/time. Du kan også velge «Pay As You Go»-alternativet, som starter fra $20/GB + $0,1/time.
Hva er forskjellen mellom Scraping-nettlesere og hodeløse nettlesere?
Scraping Browser er en fullverdig nettleser med et grafisk brukergrensesnitt (GUI). Hodeløse nettlesere, som Selenium, mangler GUI og brukes for å automatisere nettskraping. Hodeløse nettlesere kan støte på begrensninger når de håndterer CAPTCHA-er og botdeteksjon.
Konklusjon
Scraping Browser forenkler uthenting av data fra nettsider og er enklere å bruke enn verktøy som Selenium. Selv brukere uten teknisk bakgrunn kan enkelt bruke nettleseren takket være det intuitive grensesnittet og god dokumentasjon. Scraping Browser tilbyr avanserte funksjoner som automatisk håndtering av blokkeringer og CAPTCHA-er, noe som gjør den til et effektivt verktøy for automatisering av slike prosesser.
Det er også verdt å utforske hvordan du kan stoppe ChatGPT-plugins fra å skrape innholdet på ditt eget nettsted.