Bruken av Python innen dataanalyse har vokst formidabelt over tid og fortsetter å ekspandere dag for dag.
Dataanalyse er et omfattende fagfelt med mange underområder. Blant disse er dataanalyse et av de viktigste, og uavhengig av ens ekspertisenivå innen datavitenskap, har det blitt stadig mer relevant å forstå, eller i det minste ha grunnleggende kjennskap til, dette feltet.
Hva innebærer dataanalyse?
Dataanalyse handler om å rense og omforme store mengder ustrukturerte eller uorganiserte data. Målet er å generere sentral innsikt og informasjon som kan bidra til å ta velinformerte avgjørelser.
Det eksisterer forskjellige verktøy for dataanalyse, som Python, Microsoft Excel, Tableau og SaS. I denne artikkelen fokuserer vi imidlertid på hvordan dataanalyse utføres i Python, spesielt ved hjelp av et Python-bibliotek kalt Pandas.
Hva er Pandas?
Pandas er et åpen kildekode Python-bibliotek som brukes for datamanipulering og bearbeiding. Det er hurtig og svært effektivt, og inneholder verktøy for å laste inn forskjellige typer data i minnet. Det kan brukes til å transformere, segmentere, indeksere eller til og med gruppere ulike former for data.
Datastrukturer i Pandas
Pandas opererer med tre hoveddatastrukturer:
| Serie | DataFrame | Panel |
En enkel måte å forstå forskjellen på er å tenke at en struktur inneholder flere «stabler» av den foregående. En DataFrame består altså av en stabel av serier, og et panel er en stabel av DataFrames.
En serie er en endimensjonal matrise.
En stabel av flere serier skaper en todimensjonal DataFrame.
En stabel med flere DataFrames utgjør et tredimensjonalt panel.
I hovedsak vil vi jobbe mest med den todimensjonale DataFrame-strukturen, som også er standardrepresentasjonen for mange datasett.
Dataanalyse med Pandas
For denne artikkelen kreves ingen installasjon. Vi vil bruke et verktøy kalt Colab, utviklet av Google. Dette er et online Python-miljø for dataanalyse, maskinlæring og kunstig intelligens. Det er i bunn og grunn en skybasert Jupyter Notebook som leveres forhåndsinstallert med nesten alle Python-pakker en dataforsker trenger.
Gå nå til https://colab.research.google.com/notebooks/intro.ipynb. Du skal se noe som ligner på dette:
Klikk på «Fil»-alternativet øverst til venstre og velg «Ny notatbok». Du vil se en ny Jupyter Notebook-side lastet inn i nettleseren din. Først må vi importere Pandas til vårt arbeidsmiljø. Dette kan gjøres ved å kjøre følgende kode:
import pandas as pdI denne artikkelen vil vi bruke et datasett med boligpriser for vår dataanalyse. Datasettet vi bruker, finnes her. Det første vi vil gjøre, er å laste inn dette datasettet i vårt miljø.
Dette kan gjøres med følgende kode i en ny celle:
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media &token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0 ', sep=',')`.read_csv` brukes når vi skal lese en CSV-fil. `sep`-egenskapen angir at CSV-filen er kommadelt.
Vi noterer oss også at den nedlastede CSV-filen er lagret i en variabel kalt `df`.
Vi trenger ikke å bruke `print()`-funksjonen i Jupyter Notebook. Vi kan bare skrive et variabelnavn i cellen, og Jupyter Notebook vil skrive det ut for oss.
Vi kan prøve dette ved å skrive `df` i en ny celle og kjøre den. Dette vil skrive ut alle dataene i datasettet vårt som en DataFrame.
Noen ganger vil vi ikke se alle dataene, men bare de første dataene og kolonnenavnene. Vi kan bruke funksjonen `df.head()` til å skrive ut de fem første kolonnene og `df.tail()` for å skrive ut de fem siste. Utgangen fra en av disse funksjonene vil se slik ut:
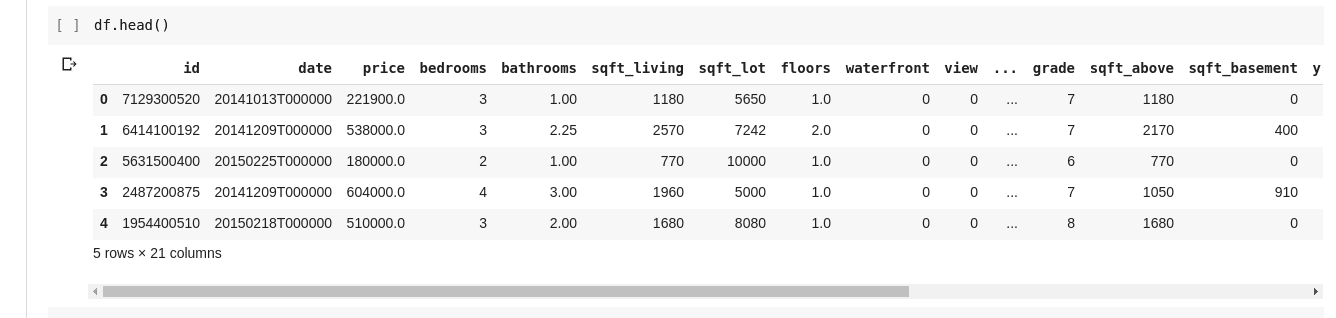
Vi ønsker å utforske relasjoner mellom de mange radene og kolonnene med data. Funksjonen `.describe()` gjør nettopp dette for oss.
Ved å kjøre `df.describe()`, får vi følgende utgang:
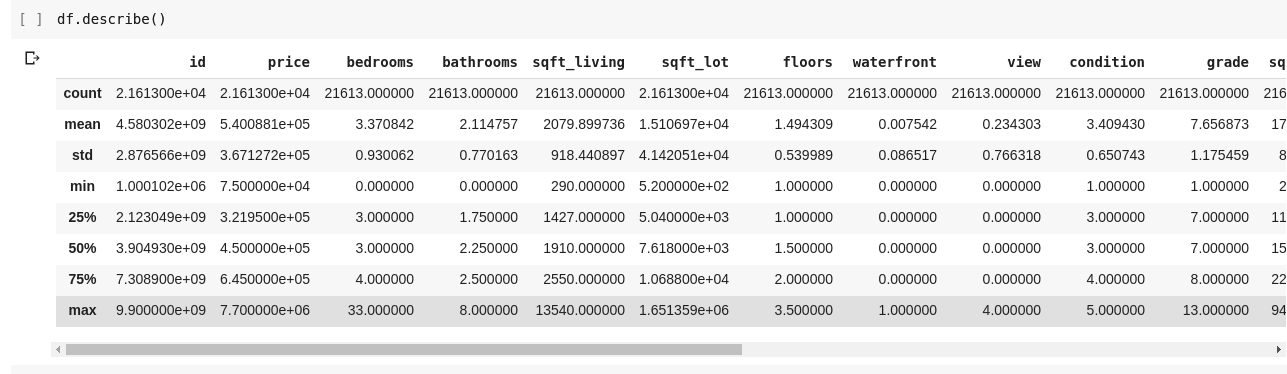
Vi ser umiddelbart at `.describe()` gir oss gjennomsnitt, standardavvik, minimums- og maksimumsverdier og persentiler for hver kolonne i DataFrame. Dette er svært nyttig.
Vi kan også sjekke formen på vår todimensjonale DataFrame for å finne ut hvor mange rader og kolonner den inneholder. Dette kan vi gjøre ved å bruke `df.shape`, som returnerer en tuppel i formatet `(rader, kolonner)`.
Vi kan også undersøke navnene på alle kolonnene i vår DataFrame ved å bruke `df.columns`.
Hva om vi bare ønsker å velge én kolonne og returnere alle dataene i den? Dette gjøres på samme måte som å hente informasjon fra en ordbok. Skriv inn følgende kode i en ny celle og kjør den:
df['price ']Koden over returnerer priskolonnen. Vi kan lagre den i en ny variabel som dette:
price = df['price']Nå kan vi utføre alle de samme operasjonene som kan utføres på en DataFrame på vår `price`-variabel, siden den er en delmengde av en faktisk DataFrame. Vi kan bruke funksjoner som `df.head()`, `df.shape` osv.
Vi kan også velge flere kolonner ved å sende en liste med kolonnenavn til `df`, slik som:
data = df[['price ', 'bedrooms']]Ovenstående velger kolonnene med navnene «price» og «bedrooms». Hvis vi skriver `data.head()` i en ny celle, får vi følgende:
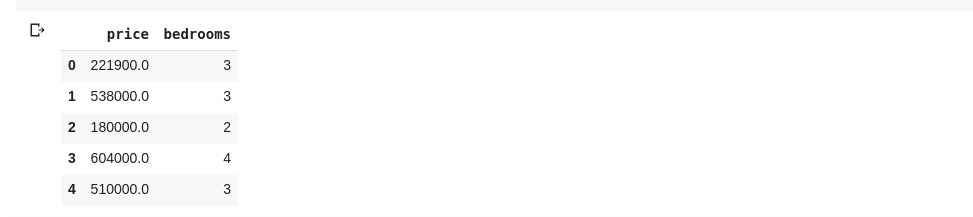
Metoden ovenfor returnerer alle radelementene i kolonnen. Hva om vi ønsker å returnere et utvalg av rader og et utvalg av kolonner fra datasettet vårt? Dette kan gjøres ved å bruke `.iloc`, som indekseres på samme måte som Python-lister. Vi kan gjøre noe slikt som:
df.iloc[50: , 3]Dette returnerer den tredje kolonnen fra den 50. raden til slutten. Dette er i prinsippet identisk med hvordan man skiver lister i Python.
La oss nå gjøre noen virkelig interessante ting. Vårt boligprisdatasett har en kolonne som angir prisen på et hus, og en annen kolonne som angir antall soverom. Boligprisen er en kontinuerlig verdi, så det er mulig at vi ikke har to hus med nøyaktig samme pris. Men antall soverom er en diskret verdi, så det er sannsynlig at flere hus har to, tre, fire soverom osv.
Hva om vi ønsker å finne alle hus med samme antall soverom og finne gjennomsnittsprisen for hvert diskrete antall soverom? Dette er relativt enkelt å gjøre i Pandas, slik:
df.groupby('bedrooms ')['price '].mean()Ovenstående grupperer først DataFrame etter datasett med identisk antall soverom ved hjelp av funksjonen `df.groupby()`. Deretter ber vi den om å returnere bare priskolonnen og bruker `.mean()`-funksjonen for å finne gjennomsnittet for hvert antall soverom i datasettet.
Hva om vi ønsker å visualisere dette? Vi ønsker å sjekke hvordan gjennomsnittsprisen varierer for hvert enkelt antall soverom. Vi trenger bare å lenke den forrige koden til en `.plot()`-funksjon, slik:
df.groupby('bedrooms ')['price '].mean().plot()Vi vil få en utgang som ser slik ut:
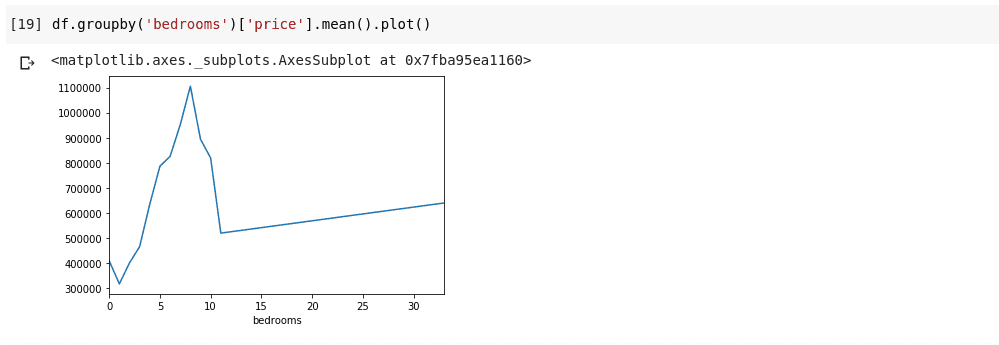
Ovenstående viser oss noen trender i dataene. På den horisontale aksen har vi antall soverom (merk at mer enn ett hus kan ha X antall soverom). På den vertikale aksen har vi gjennomsnittet av prisene for det tilsvarende antall soverom på den horisontale aksen. Vi kan nå se at hus med mellom 5 og 10 soverom koster mye mer enn hus med 3 soverom. Det blir også tydelig at hus med rundt 7 eller 8 soverom koster mye mer enn hus med 15, 20 eller til og med 30 rom.
Informasjon som dette er grunnen til at dataanalyse er så viktig. Vi kan trekke ut verdifull innsikt fra dataene som ellers ikke ville vært synlig uten analyse.
Manglende data
La oss tenke oss at jeg gjennomfører en spørreundersøkelse med mange spørsmål. Jeg deler en lenke til undersøkelsen med tusenvis av mennesker slik at de kan gi tilbakemeldinger. Mitt endelige mål er å utføre dataanalyse på disse dataene for å få nyttig innsikt.
Mye kan gå galt. Noen respondenter kan føle seg ukomfortable med å svare på noen av spørsmålene og la de stå tomme. Andre kan gjøre det samme for flere deler av undersøkelsen. Dette kan virke som et lite problem, men tenk om jeg samler inn numeriske data i undersøkelsen, og en del av analysen krever at jeg finner enten summen, gjennomsnittet eller utfører andre aritmetiske operasjoner? Flere manglende verdier ville føre til mange unøyaktigheter i min analyse. Jeg må finne en måte å oppdage og erstatte disse manglende verdiene med verdier som kan være en nær erstatning.
Pandas gir oss en funksjon for å finne manglende verdier i en DataFrame, kalt `isnull()`.
Funksjonen `isnull()` kan brukes slik:
df.isnull()Dette returnerer en DataFrame med boolske verdier som viser om dataene som var der, faktisk mangler. Utgangen ser slik ut:
Vi trenger en måte å erstatte alle de manglende verdiene. Ofte kan de manglende verdiene erstattes med null. Andre ganger kan det erstattes med gjennomsnittet av alle de andre verdiene eller gjennomsnittet av dataene rundt det, avhengig av dataforskeren og bruksområdet til dataene som analyseres.
For å fylle ut alle manglende verdier i en DataFrame, bruker vi funksjonen `.fillna()`, som brukes slik:
df.fillna(0)I eksemplet ovenfor fyller vi alle tomme data med verdien null. Det kan like godt være et hvilket som helst annet tall som vi ønsker at det skal være.
Betydningen av data kan ikke understrekes for mye. Det hjelper oss med å få svar direkte fra dataene våre! Dataanalyse blir ofte omtalt som den nye oljen for digitale økonomier.
Du finner alle eksemplene i denne artikkelen her.
For å lære mer, se nettkurset Dataanalyse med Python og Pandas.