En sammensatt læringstilnærming kan bistå deg i å ta mer veloverveide avgjørelser og adressere en rekke praktiske utfordringer ved å forene prognoser fra flere ulike modeller.
Maskinlæring (ML) fortsetter å ekspandere sin innflytelse over et mangfold av sektorer og bransjer, inkludert finans, helsevesen, applikasjonsutvikling og sikkerhet.
Å trene ML-modeller på en hensiktsmessig måte vil øke sannsynligheten for suksess i din bedrift eller profesjonelle rolle, og det finnes en rekke metoder for å oppnå dette.
I denne artikkelen vil vi gå dypere inn i konseptet ensemblelæring, utforske dens betydning, praktiske anvendelser og de ulike teknikkene den omfatter.
Følg med for å lære mer!
Hva er ensemblelæring?
I domenet maskinlæring og statistikk, refererer begrepet «ensemble» til metoder som genererer distinkte hypoteser ved hjelp av en felles basislæringsalgoritme.
Ensemblelæring er en maskinlæringsstrategi der flere modeller (tolket som eksperter eller klassifiserere) utvikles strategisk og kombineres med det formål å løse et spesifikt beregningsproblem eller forbedre prediksjonsnøyaktigheten.
Denne metoden tar sikte på å forbedre ytelsen til en gitt modell, enten det er prediksjon, funksjonstilnærming, klassifisering eller andre parametre. Den bidrar også til å unngå potensielle fallgruver ved å velge en suboptimal eller mindre effektiv modell blant mange tilgjengelige alternativer. Flere læringsalgoritmer samspiller for å oppnå forbedret prediktiv kapasitet.
Betydningen av ensemblelæring i maskinlæring
I maskinlæringsmodeller eksisterer flere feilkilder, som skjevhet, varians og støy, som kan føre til uønskede resultater. Ensemblelæring kan bidra til å redusere effekten av disse feilkildene og sikre stabiliteten og nøyaktigheten til dine ML-algoritmer.
Følgende punkter illustrerer hvorfor ensemblelæring er en verdifull tilnærming i ulike scenarier:
Forbedret klassifikasjonsvalg
Ensemblelæring hjelper deg å identifisere en overlegen modell eller klassifiserer samtidig som den reduserer risikoen for dårlig modellvalg.

Det finnes ulike typer klassifikatorer som er egnet for forskjellige problemstillinger, inkludert støttevektormaskiner (SVM), flerlagsperceptron (MLP), naive Bayes-klassifiserere og beslutningstrær. I tillegg finnes det en mengde implementeringer av klassifiseringsalgoritmer som man må vurdere. Ytelsen til algoritmer kan også variere avhengig av de spesifikke treningsdataene.
I stedet for å stole på en enkelt modell, kan du redusere sannsynligheten for å velge en undermålsmodell ved å ta i bruk et ensemble som kombinerer utdataene fra alle disse modellene.
Håndtering av datavolum
Mange ML-metoder og modeller kan vise begrenset effektivitet hvis de blir trent på et utilstrekkelig eller for stort datavolum.
Ensemblelæring er mer fleksibel og kan fungere effektivt under begge forhold, enten datavolumet er for lite eller overveldende.
- Hvis datatilgangen er begrenset, kan du benytte bootstrapping for å trene forskjellige klassifiserere med utgangspunkt i ulike datasett generert med bootstrap-metoden.
- I tilfeller der datamengden er stor og utfordrer opplæringen av en enkelt klassifiserer, kan du dele dataene strategisk inn i mindre delmengder.
Håndtering av kompleksitet

En individuell klassifikator er kanskje ikke i stand til å håndtere svært komplekse problemer på en tilfredsstillende måte. Beslutningsgrensene for å skille data fra ulike klasser kan være avanserte. Dermed vil en lineær klassifikator slite med å lære seg en ikke-lineær grense.
Ved å sammensette et ensemble av egnede lineære klassifiserere på en smart måte, kan du likevel lykkes med å lære en gitt ikke-lineær grense. Klassifikatorene deler dataene inn i flere lettlærte og mindre partisjoner, slik at hver klassifikator bare fokuserer på å lære en enklere partisjon. Ulike klassifiserere vil deretter kombineres for å generere en tilnærmet beslutningsgrense.
Tillitsestimering
Ensemblelæring gir en tillitsvurdering til avgjørelser et system tar. Se for deg et ensemble av ulike klassifiserere som er trent på et gitt problem. Hvis det er enighet blant majoriteten av klassifisererne om den endelige beslutningen, kan resultatet betraktes som en beslutning med høy tillit.
Hvis imidlertid en betydelig andel av klassifisererne ikke er enige i den fattede beslutningen, vil avgjørelsen ha lavere tillit.
Det er viktig å merke seg at høy eller lav tillit ikke alltid garanterer korrekthet. Imidlertid er det større sjanse for at en beslutning med høy tillit er korrekt hvis ensemblet er tilstrekkelig trent.
Forbedret nøyaktighet gjennom datasammenslåing
Data innhentet fra ulike kilder kan strategisk kombineres for å forbedre nøyaktigheten til klassifikasjonsbeslutninger. Denne nøyaktigheten er høyere enn den som oppnås med en enkelt datakilde.
Hvordan fungerer ensemblelæring?
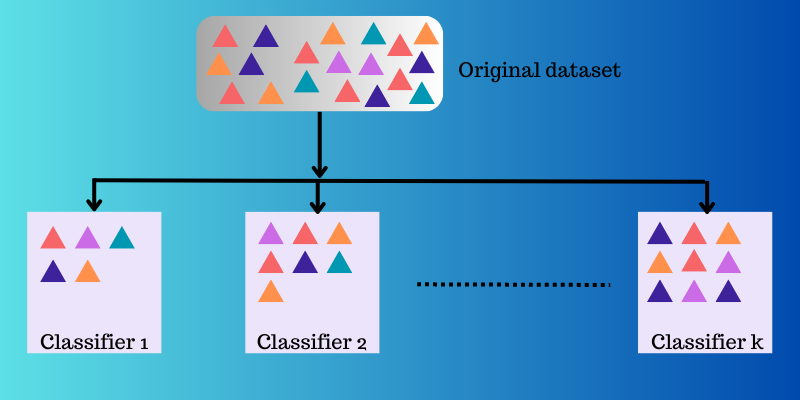
Ensemblelæring tar flere kartleggingsfunksjoner som ulike klassifiserere har lært, og kombinerer dem for å lage én enkelt kartleggingsfunksjon.
Nedenfor presenteres et eksempel på hvordan ensemblelæring kan anvendes:
Tenk deg at du utvikler en matbasert applikasjon for sluttbrukere. For å tilby en førsteklasses brukeropplevelse ønsker du å samle inn tilbakemeldinger om potensielle problemer, svakheter, feil og mangler.
For å gjøre dette kan du innhente meninger fra familie, venner, kolleger og andre personer du regelmessig er i kontakt med, angående deres matpreferanser og erfaringer med matbestilling på nett. Du kan også tilby appen din i en betautgave for å samle inn tilbakemeldinger i sanntid, uten skjevheter eller støy.
I realiteten samler du inn ulike perspektiver og ideer fra forskjellige individer for å forbedre brukeropplevelsen.
Ensemblelæring og de tilhørende modellene fungerer på en lignende måte. Den benytter seg av et sett med modeller og kombinerer dem for å produsere en endelig utgang som gir bedre prediksjonsnøyaktighet og ytelse.
Grunnleggende ensemblelæringsteknikker
#1. Modus
En «modus» representerer verdien som forekommer hyppigst i et datasett. Innenfor ensemblelæring bruker ML-eksperter flere modeller for å generere prediksjoner for hvert datapunkt. Disse prediksjonene tolkes som individuelle stemmer, og prediksjonen som de fleste modellene stemmer for anses som den endelige. Denne teknikken brukes ofte i klassifiseringsproblemer.
Eksempel: Hvis fire personer vurderte appen din til 4, mens én person ga den en 3, vil modusen være 4, ettersom et flertall vurderte appen som 4.
#2. Gjennomsnitt
Med denne teknikken beregner eksperter det aritmetiske gjennomsnittet av alle modellprediksjoner for å få den endelige prognosen. Dette brukes ofte i regresjonsproblemer, beregning av sannsynligheter i klassifiseringsproblemer og mye mer.
Eksempel: I eksempelet over, der fire personer ga appen en 4 og én person ga en 3, vil gjennomsnittet være (4+4+4+4+3)/5=3,8
#3. Vektet gjennomsnitt
Med denne ensemblelæringsmetoden tildeler fagfolk ulike vekter til forskjellige modeller for å lage en prognose. Den tildelte vekten indikerer hver modells relevans.
Eksempel: Hvis 5 personer ga tilbakemelding på applikasjonen din, og 3 av dem er apputviklere, mens de 2 andre ikke har erfaring med apputvikling, vil tilbakemeldingene fra de 3 apputviklerne ha større vekt enn de 2 andre.
Avanserte ensemblelæringsteknikker
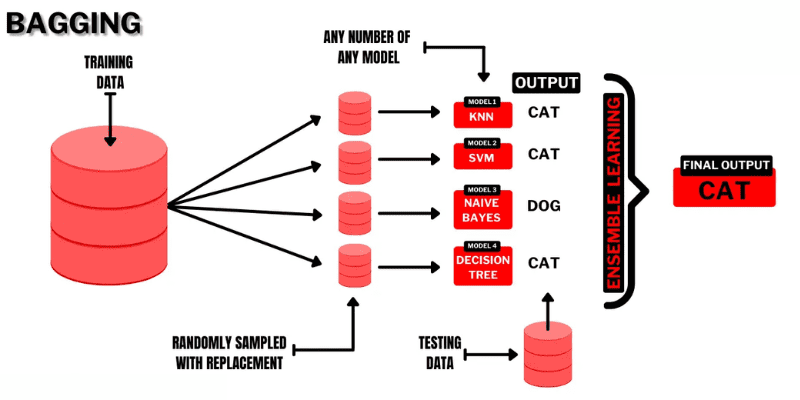
#1. Bagging
Bagging (Bootstrap Aggregating) er en intuitiv og brukervennlig ensemblelæringsteknikk med god ytelse. Som navnet antyder, er den formet ved å kombinere konseptene «Bootstrap» og «aggregation».
Bootstrapping er en resamplingmetode der man lager delsett ved å trekke flere observasjoner med tilbakelegging fra det opprinnelige datasettet. Størrelsen på delsettet er identisk med størrelsen på det opprinnelige datasettet.
Kilde: Buggy-programmerer
I bagging benyttes delsett for å forstå fordelingen av hele datasettet. Disse delsettene kan være mindre enn det opprinnelige datasettet. Denne metoden bruker en enkelt ML-algoritme. Formålet med å kombinere resultater fra ulike modeller er å oppnå et generalisert resultat.
Bagging fungerer som følger:
- Flere delsett genereres fra det opprinnelige datasettet, der observasjoner velges med tilbakelegging. Disse delsettene brukes for å trene modeller eller beslutningstrær.
- En svak modell eller basismodell utvikles for hvert delsett. Modellene er uavhengige av hverandre og jobber parallelt.
- Den endelige prediksjonen oppnås ved å kombinere prognosene fra hver modell ved bruk av statistiske metoder, som gjennomsnitt eller stemming.
Populære algoritmer som brukes i denne ensembleteknikken er:
- Tilfeldig skog
- Posede beslutningstrær
En fordel med denne metoden er at den hjelper til med å minimere variansfeil i beslutningstrær.
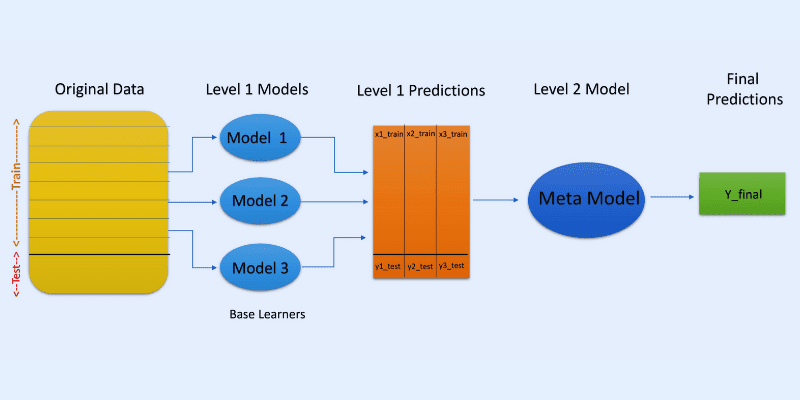
#2. Stacking
Bildekilde: OpenGenus IQ
I stabling eller stablet generalisering brukes prediksjoner fra flere modeller, slik som et beslutningstre, for å lage en ny modell som genererer prediksjoner for testsettet.
Stacking skaper delsett av data for å trene modeller, på samme måte som bagging. Utdataene fra disse modellene brukes imidlertid som input til en annen klassifiserer, kjent som en metaklassifiserer, for den endelige prediksjonen av prøvene.
Grunnen til at to klassifiseringslag brukes, er for å finne ut om treningsdatasett har blitt lært korrekt. Selv om en to-lags tilnærming er vanlig, kan flere lag også brukes.
For eksempel kan du bruke 3-5 modeller i det første laget eller nivå-1 og en enkelt modell i lag 2 eller nivå-2. Den sistnevnte modellen kombinerer prognosene oppnådd i nivå-1 for å lage den endelige prediksjonen.
Videre kan du bruke hvilken som helst ML-modell for å samle inn prediksjoner. En lineær modell, slik som lineær regresjon eller logistisk regresjon, er vanlig.
Vanlige ML-algoritmer som brukes i stabling er:
- Blanding
- Super ensemble
- Stablede modeller
Merk: Blanding benytter et valideringssett for å generere prediksjoner. I motsetning til stabling, genereres prediksjoner i blanding kun fra holdout-settet.
#3. Boosting
Boosting er en iterativ ensemblelæringsmetode som justerer vekten til en spesifikk observasjon, basert på dens tidligere klassifisering. Hver påfølgende modell prøver å korrigere feil som ble begått av den forrige modellen.
Hvis en observasjon ikke blir klassifisert riktig, øker boosting vekten av observasjonen.
I boosting trener eksperter den første boosting-algoritmen på et komplett datasett. Deretter bygges påfølgende ML-algoritmer med utgangspunkt i residualene fra den forrige boosting-algoritmen. På denne måten legges det mer vekt på feilklassifiserte observasjoner.
Følgende er trinnvis fremgangsmåte:
- Et delsett opprettes fra det opprinnelige datasettet. Hvert datapunkt vil i utgangspunktet ha lik vekt.
- En basismodell opprettes for delsettet.
- En prediksjon gjøres på hele datasettet.
- Feil beregnes ved bruk av de faktiske og predikerte verdiene.
- Feilpredikerte observasjoner får økt vekt.
- En ny modell opprettes og den endelige prediksjonen genereres, mens modellen prøver å rette opp tidligere feil. Flere modeller vil opprettes på tilsvarende måte, der hver modell korrigerer feilene som ble begått av de tidligere modellene.
- Den endelige prediksjonen genereres fra den siste modellen, som er det vektede gjennomsnittet av alle modellene.
Populære boosting-algoritmer er:
- CatBoost
- Lett GBM
- AdaBoost
Fordelen med boosting er at den produserer overlegne prognoser og reduserer feil som skyldes skjevhet.
Andre ensembleteknikker

Blanding av eksperter: Denne teknikken brukes til å trene flere klassifiserere, og deres utganger kombineres ved hjelp av en generell lineær regel. Vekten til kombinasjonene bestemmes av en trenbar modell.
Flertallsstemming: Denne teknikken innebærer å velge en odde antall klassifiserere, og prediksjoner beregnes for hver prøve. Klassen som mottar det største antallet stemmer fra en klassifiseringspool vil være den forutsagte klassen i ensemblet. Denne teknikken brukes for å løse binære klassifiseringsproblemer.
Maks-regel: Denne teknikken bruker sannsynlighetsfordelingene til hver klassifikator og stoler på tillitsnivåer for å generere prediksjoner. Den brukes for å løse klassifiseringsproblemer i flere klasser.
Praktiske anvendelser for ensemblelæring
#1. Ansikts- og følelsesgjenkjenning
Ensemblelæring bruker teknikker som uavhengig komponentanalyse (ICA) for å utføre ansiktsgjenkjenning.
Ensemblelæring benyttes også for å oppdage følelsene til en person ved hjelp av talegjenkjenning. I tillegg hjelper funksjonen brukere med å oppdage ansiktsfølelser.
#2. Sikkerhet
Svindeldeteksjon: Ensemblelæring bidrar til å forbedre effekten av normal atferdsmodellering. Dette gjør metoden effektiv for å avdekke svindel, slik som svindel med kredittkort, banksystemer, telekommunikasjon, hvitvasking og mer.

DDoS: Et distribuert tjenestenektangrep (DDoS) kan være et dødelig angrep for en internettleverandør (ISP). Ensembleklassifiserere kan redusere falske positive resultater og skille angrep fra ekte trafikk.
Intrusjonsdeteksjon: Ensemblelæring kan brukes i overvåkningssystemer, som for eksempel inntrengningsdeteksjonsverktøy, for å finne inntrengerkoder ved å overvåke nettverk eller systemer, oppdage uregelmessigheter og så videre.
Oppdagelse av skadelig programvare: Ensemblelæring er svært effektiv for å oppdage og klassifisere skadelig programvare, som datavirus, ormer, løsepengevirus, trojanske hester og spionprogrammer, med bruk av maskinlæringsteknikker.
#3. Inkrementell læring
Ved inkrementell læring lærer en ML-algoritme fra nye datasett samtidig som den bevarer tidligere læring. Systemet har ikke tilgang til tidligere data som det allerede har analysert. Ensemblesystemer brukes i inkrementell læring ved at systemet lærer en ekstra klassifisering på hvert nye datasett som blir tilgjengelig.
#4. Medisin
Ensembleklassifiserere er nyttige i medisinsk diagnostikk, for eksempel for å oppdage nevrokognitive lidelser (som Alzheimers). Systemet utfører deteksjon ved å ta MR-datasett som input for å klassifisere livmorhalsprøver. I tillegg brukes det innen proteomikk (studier av proteiner), nevrovitenskap og andre områder.
#5. Fjernmåling
Endringsdeteksjon: Ensembleklassifiserere brukes for å utføre endringsdeteksjon med metoder som Bayesiansk gjennomsnitt og flertallsstemming.
Kartlegging av landdekke: Ensemblelæringsmetoder, slik som boosting, beslutningstrær og kjernekomponentanalyse (KPCA), brukes for å oppdage og kartlegge landdekke effektivt.
#6. Finans
Nøyaktighet er viktig innen finans, enten det er beregninger eller prediksjoner. Dette påvirker i stor grad utfallet av beslutningene som tas. Ensemblelæring kan også brukes for å analysere endringer i aksjemarkedsdata, oppdage manipulasjon av aksjekurser og mye mer.
Ytterligere ressurser

#1. Ensemblemetoder for maskinlæring
Denne boken gir deg innsikt i hvordan du lærer og implementerer grunnleggende metoder for ensemblelæring fra bunnen av.
#2. Ensemblemetoder: Grunnlag og algoritmer
Denne boken tar for seg det grunnleggende i ensemblelæring og de tilhørende algoritmene. Den beskriver også hvordan konseptet brukes i praksis.
#3. Ensemblelæring
Denne ressursen gir en introduksjon til en samlet ensemblemetode, utfordringer, anvendelser og mer.
#4. Ensemble maskinlæring: Metoder og anvendelser
Dette materialet gir en bred oversikt over avanserte ensemblelæringsteknikker.
Konklusjon
Vi håper du nå har en god forståelse av hva ensemblelæring er, de ulike metodene som brukes, praktiske anvendelser og hvorfor det kan være et fordelaktig verktøy i din spesifikke situasjon. Konseptet har et stort potensial for å løse mange utfordringer i virkeligheten, innen sikkerhet, applikasjonsutvikling, økonomi, helsevesen og andre områder. Bruksområdene utvides stadig, så det er sannsynlig at det vil komme enda flere forbedringer innenfor dette feltet i nær fremtid.
Du kan også utforske noen verktøy for syntetisk datagenerering for å trene maskinlæringsmodeller.