Om du er kjent med feltet dyp læring, har du garantert støtt på diskusjonen om PyTorch kontra TensorFlow mer enn én gang.
PyTorch og TensorFlow er to av de mest utbredte rammeverkene for dyp læring. Denne veiledningen gir en grundig gjennomgang av de viktigste egenskapene til disse to rammeverkene. Målet er å hjelpe deg med å avgjøre hvilket rammeverk som passer best for ditt neste prosjekt innen dyp læring.
I denne artikkelen vil vi først presentere de to rammeverkene, PyTorch og TensorFlow, og deretter oppsummere de ulike funksjonene de tilbyr.
La oss starte!
Hva er PyTorch?
PyTorch er et åpen kildekode-rammeverk som brukes til å utvikle modeller for maskinlæring og dyp læring for et bredt spekter av bruksområder, inkludert naturlig språkbehandling og datasyn.
Det er et Python-basert rammeverk som ble utviklet av Meta AI (tidligere Facebook AI) i 2016. Det er basert på Torch, en pakke som er skrevet i Lua.
Meta AI lanserte nylig PyTorch 2.0. Den nye versjonen tilbyr blant annet forbedret støtte for distribuert trening, modellkompilering og grafiske nevrale nettverk (GNN).
Hva er TensorFlow?

TensorFlow ble lansert i 2014 og er et ende-til-ende, åpen kildekode-rammeverk for maskinlæring fra Google. Det kommer med en rekke funksjoner for dataforberedelse, modelldistribusjon og MLOps.
TensorFlow tilbyr utviklingsstøtte på tvers av ulike plattformer og gir god støtte for alle stadier i maskinlæringens livssyklus.
PyTorch vs. TensorFlow
Både PyTorch og TensorFlow er svært populære rammeverk i miljøet for dyp læring. De fleste bruksområder du ønsker å jobbe med vil ha innebygd støtte i begge disse rammeverkene.
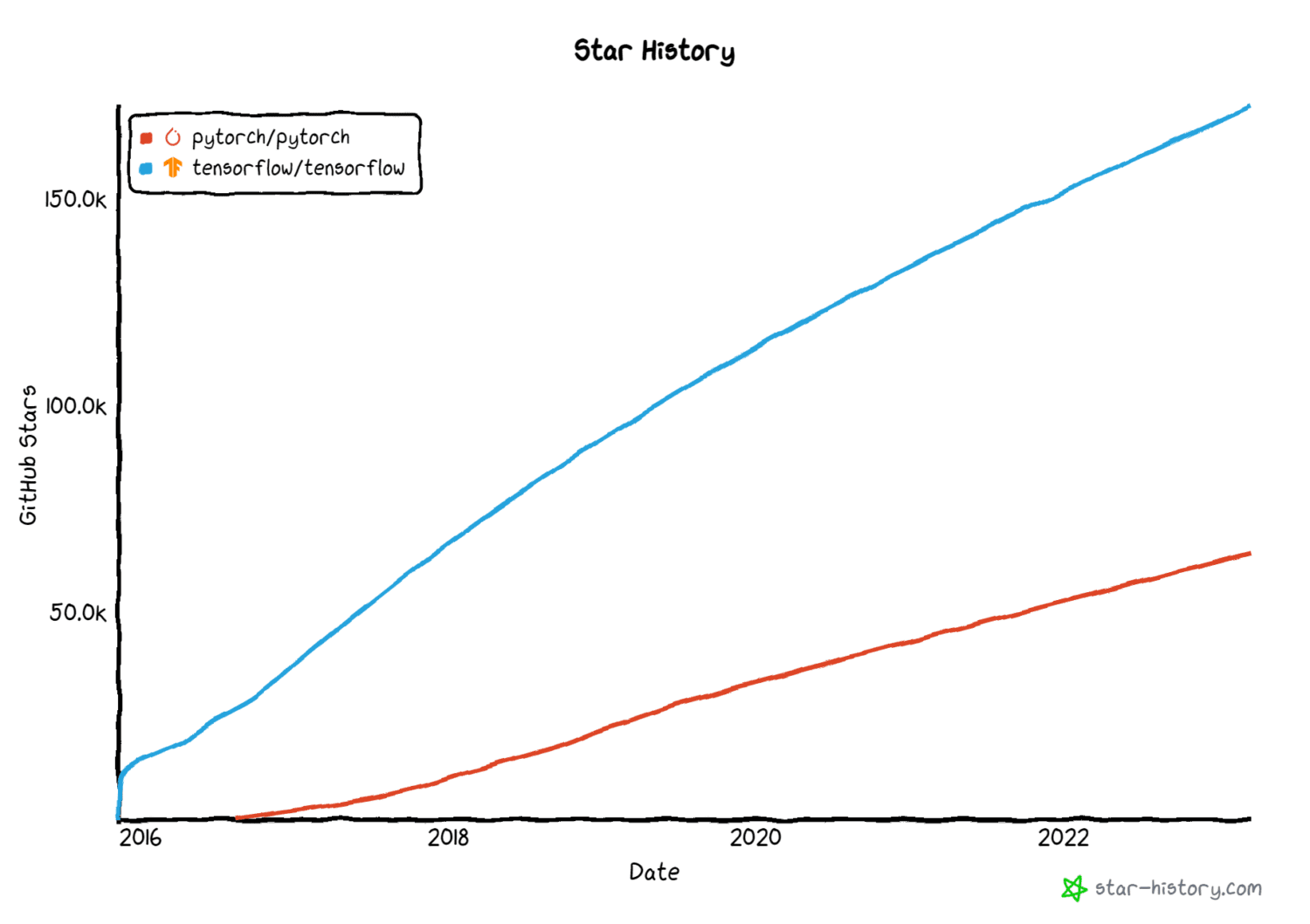 Bildekilde: star-history.com
Bildekilde: star-history.com
Her oppsummerer vi de viktigste funksjonene til både PyTorch og TensorFlow, og identifiserer situasjoner der det kan være hensiktsmessig å foretrekke det ene rammeverket fremfor det andre.
#1. Bibliotek med datasett og forhåndstrente modeller
Et rammeverk for dyp læring bør inkludere et godt utvalg av ressurser. Det er ofte ikke nødvendig å kode en modell fra bunnen av. I stedet kan du dra nytte av forhåndstrente modeller og finjustere dem for ditt spesifikke bruksområde.
På samme måte er det ønskelig at vanlige datasett er lett tilgjengelige. Dette gjør det mulig å utvikle eksperimentelle modeller raskt, uten å måtte sette opp en egen datainnsamlingsprosess eller importere og rense data fra eksterne kilder.
Vi ønsker at disse rammeverkene skal leveres med både datasett og forhåndstrente modeller, slik at det er mulig å få en grunnleggende modell raskere.
PyTorch-datasett og modeller
PyTorch tilbyr biblioteker som torchtext, torchaudio og torchvision for henholdsvis NLP-, lyd- og bildebehandlingsoppgaver. Ved bruk av PyTorch kan du dra nytte av datasettene og modellene som tilbys av disse bibliotekene, inkludert:
- torchtext.datasets og torchtext.models for datasett og behandling for oppgaver innen naturlig språkbehandling.
- torchvision.datasets og torchvision.models tilbyr bildedatasett og forhåndstrente modeller for datasynsoppgaver.
- torchaudio.datasets og torchaudio.models for datasett og forhåndstrente modellvekter samt verktøy for maskinlæring på lyd.
TensorFlow-datasett og modeller
I tillegg kan du finne både PyTorch- og TensorFlow-modeller i HuggingFace Model Hub.
#2. Støtte for distribusjon
I diskusjonen om PyTorch vs. TensorFlow, er støtte for distribusjon et sentralt tema.
En maskinlæringsmodell som fungerer utmerket i ditt lokale utviklingsmiljø er et godt utgangspunkt. For å få verdi fra maskinlæringsmodeller er det likevel viktig å distribuere dem til produksjon og overvåke dem kontinuerlig.
I dette avsnittet ser vi nærmere på funksjonene som både PyTorch og TensorFlow tilbyr for å distribuere maskinlæringsmodeller til produksjon.
TensorFlow Extended (TFX)
TensorFlow Extended, forkortet til TFX, er et distribusjonsrammeverk som er basert på TensorFlow. Det tilbyr funksjonalitet som hjelper deg med å orkestrere og vedlikeholde maskinlæringspipeliner. Det inkluderer funksjoner for datavalidering og datatransformasjon.
Med TensorFlow Serving kan du distribuere maskinlæringsmodeller i produksjonsmiljøer.
TorchServe
Det er en vanlig oppfatning at PyTorch er populært i forskningsmiljøet, mens TensorFlow er populært i industrien. Begge rammeverkene har likevel funnet utbredt bruk.
I likhet med TensorFlow Serving tilbyr PyTorch TorchServe, et brukervennlig rammeverk som forenkler betjeningen av PyTorch-modeller i produksjon. I tillegg kan du benytte TensorFlow Lite for å distribuere maskinlæringsmodeller på mobile enheter og andre enheter.
Selv om begge rammeverkene tilbyr distribusjonsstøtte, har TensorFlow mer omfattende støtte for modelldistribusjon, noe som gjør det til det foretrukne valget i mange produksjonsmiljøer.
#3. Funksjoner for modelltolkbarhet
Du kan utvikle modeller for dyp læring som brukes i domener som helsevesen og finans. Hvis disse modellene er svarte bokser som bare gir en etikett eller en prediksjon, kan det være vanskelig å tolke modellenes prediksjoner.
Dette har ført til utviklingen av tolkbar maskinlæring (eller forklarbar ML), med mål om å utvikle metoder for å forklare hvordan nevrale nettverk og andre maskinlæringsmodeller fungerer.
Tolkbarhet er derfor svært viktig for dyp læring, for å bedre forstå hvordan nevrale nettverk fungerer. Vi ser nå på hvilke funksjoner PyTorch og TensorFlow tilbyr for dette.
PyTorch Captum
PyTorch Captum, biblioteket for modelltolkbarhet i PyTorch, gir flere funksjoner for modelltolkbarhet.

Disse funksjonene inkluderer attribusjonsmetoder som:
- Integrerte gradienter
- LIME, SHAP
- DeepLIFT
- GradCAM og varianter
- Lagattribusjonsmetoder
TensorFlow Explain (tf-explain)
TensorFlow Explain (tf-explain) er et bibliotek som tilbyr funksjonalitet for tolkning av nevrale nettverk, inkludert:
- Integrerte gradienter
- GradCAM
- SmoothGrad
- Vaniljegradienter og mer.
Vi har nå sett på funksjonene for tolkning. La oss gå videre til et annet viktig aspekt – personvern.
#4. Støtte for personvernbevarende maskinlæring
Nytten av maskinlæringsmodeller er avhengig av tilgang til reelle data. Dette medfører risiko for tap av personvern for dataene. Det har i den siste tiden vært betydelige fremskritt innen personvernbevarende maskinlæringsteknikker, som differensielt personvern og forent læring.
PyTorch Opacus
Differensielt privat modellopplæring sikrer personvernet til enkeltpersoner, samtidig som det læres nyttig informasjon om datasettet som helhet.

PyTorch Opacus gir deg mulighet til å trene modeller med differensielt personvern. For å lære mer om implementering av differensielt privat modellopplæring, kan du se introduksjonen til Opacus.
TensorFlow Federated
Forent læring eliminerer behovet for en sentralisert datainnsamlings- og behandlingsenhet. I et forent oppsett forlater dataene aldri eieren eller lokasjonen, noe som gir bedre datakontroll.
TensorFlow Federated gir funksjonalitet for å trene maskinlæringsmodeller på desentraliserte data.
#5. Enkel læring
PyTorch er et Python-basert rammeverk for dyp læring. For å kode komfortabelt i PyTorch, kreves middels ferdigheter i Python, inkludert en god forståelse av objektorientert programmering, som arv.
Med TensorFlow kan du benytte Keras API. Dette API-et på høyt nivå abstraherer bort noen av de underliggende implementasjonsdetaljene. Om du er nybegynner innen utvikling av dyp læring, kan du derfor oppleve Keras som enklere å bruke.
PyTorch vs. TensorFlow: En oversikt
Vi har nå diskutert de viktigste funksjonene til PyTorch og TensorFlow. Her er en sammenligning:
| Funksjon | PyTorch | TensorFlow |
| Datasett og forhåndstrente modeller | Bibliotek med datasett og forhåndstrente modeller i torchtext, torchaudio og torchvision | Bibliotek med datasett og forhåndstrente modeller |
| Distribusjon | TorchServe for betjening av maskinlæringsmodeller | TensorFlow Serving for betjening av TensorFlow-modeller |
| Personvernbevarende maskinlæring | PyTorch Opacus for differensielt privat modellopplæring | TensorFlow Federated for forent maskinlæring |
| Enkel læring | Krever middels ferdigheter i Python | Relativt enklere å lære og bruke |
Læringsressurser
La oss avslutte denne diskusjonen med å se på noen nyttige ressurser for å lære PyTorch og TensorFlow. Dette er ikke en uttømmende liste, men et utvalg ressurser som kan hjelpe deg raskt i gang med disse rammeverkene.
#1. Deep Learning with PyTorch: A 60-Minute Blitz
Den 60-minutters blitzveiledningen på PyTorchs offisielle nettside er en utmerket nybegynnervennlig ressurs for å lære PyTorch.

Denne opplæringen vil hjelpe deg med å komme i gang med Pytorch-grunnleggende elementer som tensorer og autografer, og bygge et grunnleggende nevralt nettverk for bildeklassifisering med PyTorch.
#2. Deep Learning med PyTorch: Null til GAN-er

Deep Learning with PyTorch: Zero to GANs av Jovian.ai er en annen omfattende ressurs for å lære dyp læring med PyTorch. I løpet av omtrent seks uker kan du lære:
- Grunnleggende PyTorch: tensorer og gradienter
- Lineær regresjon i PyTorch
- Bygge dype nevrale nettverk, ConvNets og ResNets i PyTorch
- Bygging av generative kontradiktoriske nettverk (GAN)
#3. TensorFlow 2.0 komplett kurs
Om du ønsker å lære TensorFlow, kan TensorFlow 2.0 Complete Course på freeCodeCamps fellesskapskanal være nyttig.

#4. TensorFlow – Python Deep Learning Neural Network API av DeepLizard
Et annet bra TensorFlow-kurs for nybegynnere er fra DeepLizard. I dette nybegynnervennlige TensorFlow-kurset lærer du det grunnleggende om dyp læring, inkludert:
- Laste og forhåndsbehandle datasett
- Bygge grunnleggende nevrale nettverk
- Bygge konvolusjonelle nevrale nettverk (CNN)
Konklusjon
Denne artikkelen har gitt deg en overordnet oversikt over PyTorch og TensorFlow. Valg av optimalt rammeverk vil avhenge av prosjektet du jobber med. Det krever også at du tar hensyn til støtte for distribusjon, forklarbarhet og personvern, blant annet.
Er du en Python-programmerer som ønsker å lære disse rammeverkene? Da kan det være en god idé å utforske en eller flere av ressursene som er nevnt ovenfor.
Om du er interessert i NLP, kan du se denne listen over kurs i naturlig språkbehandling. God læring!