Føderert læring representerer en ny tilnærming til datainnsamling og trening av maskinlæringsmodeller, og bryter med tradisjonelle metoder.
Gjennom føderert læring oppnås kostnadseffektiv trening av maskinlæringsmodeller som samtidig tar hensyn til personvern. Denne artikkelen gir en innføring i hva føderert læring er, hvordan det fungerer, ulike bruksområder og relevante rammeverk.
Hva er Føderert Læring?
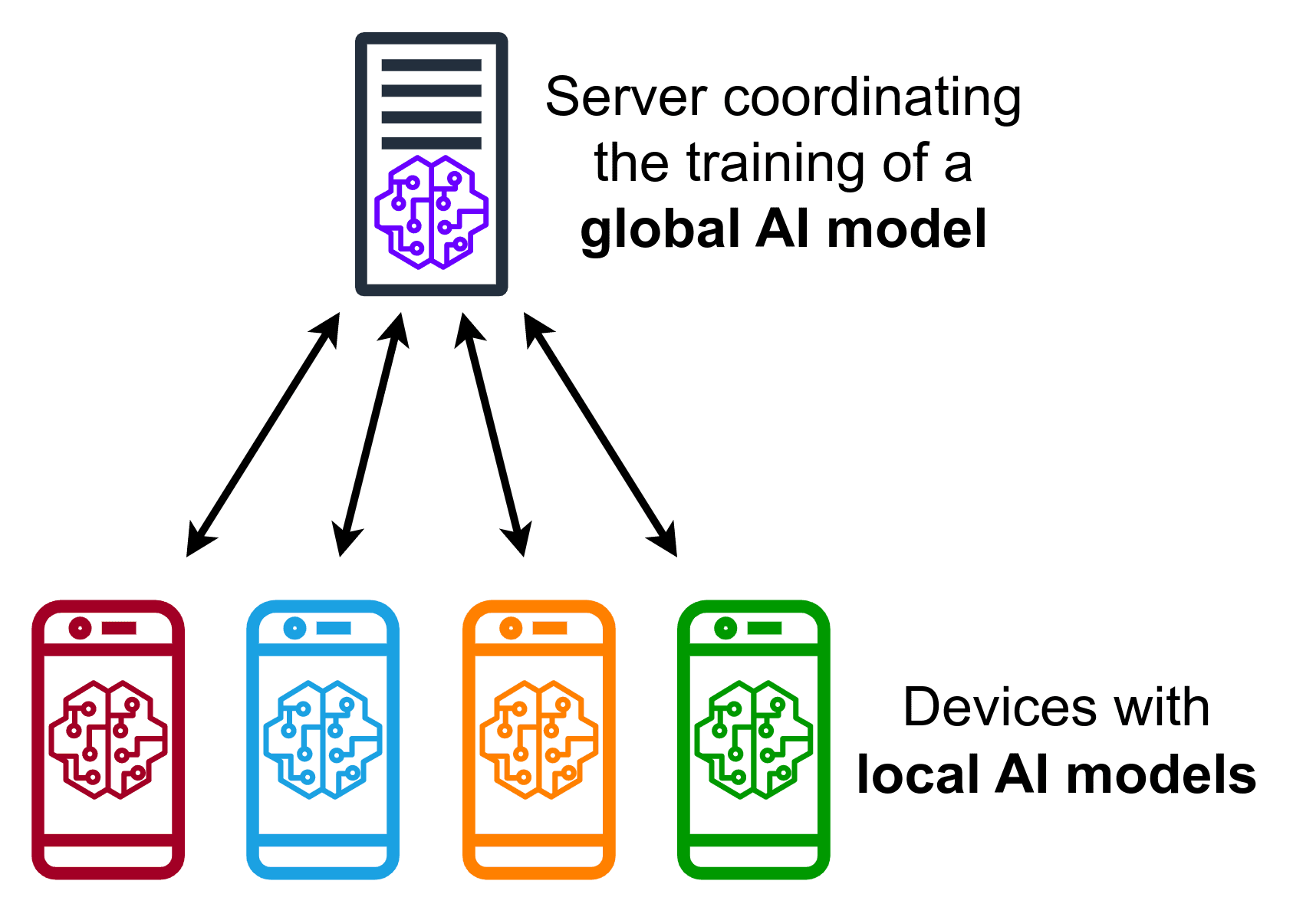 Kilde: Wikipedia
Kilde: Wikipedia
Føderert læring markerer et paradigmeskifte i hvordan maskinlæringsmodeller trenes. Tradisjonelt samles data fra flere kilder i et sentralisert datalager for å trene modeller. Føderert læring snur derimot på dette. I stedet for å sende data til et sentralt sted, trenes modellene lokalt på klientsiden, noe som bidrar til å bevare konfidensialiteten til brukernes data.
Les også: En oversikt over de mest brukte maskinlæringsmodellene
Hvordan fungerer Føderert Læring?
Føderert læring baserer seg på en serie av gjentatte trinn som gradvis forbedrer en modell. Disse trinnene, kjent som læringsrunder, går gjennom en syklus for å oppnå optimal ytelse. Hver runde består av flere faser.
En typisk læringsrunde
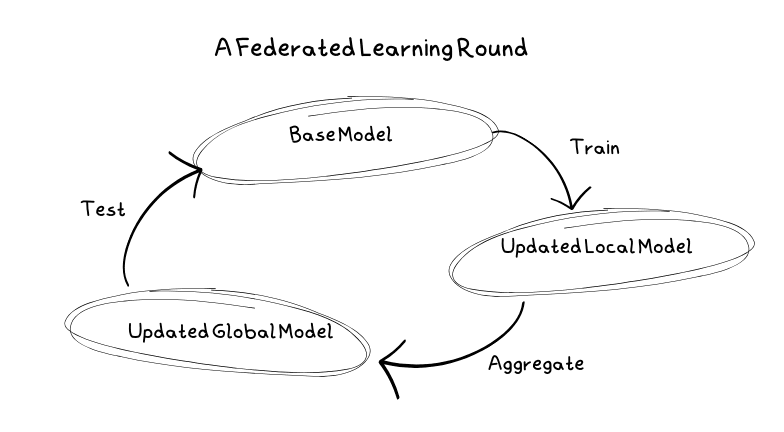
Først velger serveren den modellen som skal trenes, sammen med hyperparametere som antall runder, hvilke klientnoder som skal delta og andelen av noder som benyttes per runde. Modellen initialiseres også med de første parameterne for å danne en utgangsmodell.
Deretter mottar klientene hver sin kopi av utgangsmodellen for lokal trening. Disse klientene kan være alt fra mobile enheter og personlige datamaskiner til servere. De trener modellen ved bruk av egne lokale data, og unngår dermed å dele sensitive opplysninger med serverne.
Etter at klientene har trent modellen lokalt, sender de oppdateringene tilbake til serveren. Serveren beregner et gjennomsnitt av oppdateringene fra alle klientene for å skape en ny utgangsmodell. Ettersom noen klienter kan være upålitelige, kan det forekomme at enkelte klienter ikke sender inn sine oppdateringer. Serveren håndterer alle feil som oppstår.
Før den nye utgangsmodellen distribueres, må den testes. Da serveren ikke oppbevarer data selv, sendes modellen tilbake til klientene hvor den testes med lokale data. Hvis modellen presterer bedre enn den forrige, blir den tatt i bruk som den nye basismodellen.
Her finner du en veiledende ressursside fra Federated Learning-teamet hos Google AI om hvordan føderert læring fungerer.
Sentralisert vs. Føderert vs. Heterogen
I et sentralisert føderert læringsoppsett kontrolleres treningsprosessen av en sentral server.
Alternativt finnes det desentralisert føderert læring, hvor klientene samarbeider direkte med hverandre.
En tredje type er heterogen læring, hvor klientene ikke nødvendigvis har den samme globale modellarkitekturen.
Fordeler med Føderert Læring
- Den primære fordelen med føderert læring er at den bidrar til å bevare personvernet. Klientene deler resultatene av treningen, ikke selve treningsdataene. Det kan også etableres protokoller for å samle resultater på en måte som gjør at de ikke kan knyttes til spesifikke klienter.
- Det reduserer også bruken av nettverksbåndbredde siden ingen data deles mellom klienter og server. I stedet utveksles treningsmodeller.
- Kostnadene for trening reduseres også, da det ikke er nødvendig å investere i dyr treningsmaskinvare. Utviklere kan bruke klientenes eksisterende maskinvare. Den lille mengden data som involveres, belaster heller ikke klientenes enheter nevneverdig.
Ulemper med Føderert Læring
- Denne tilnærmingen krever deltakelse fra mange ulike noder, hvorav noen ikke kontrolleres av utvikleren. Derfor kan tilgjengeligheten ikke garanteres, noe som gjør treningsressursene potensielt upålitelige.
- Klientene som brukes til modelltrening er ofte ikke kraftige GPUer, men vanlige enheter som telefoner. Selv i sum kan disse enhetene være mindre kraftfulle enn GPU-klynger.
- Føderert læring forutsetter at alle klientnoder er pålitelige og handler i fellesskapets interesse. Noen klienter kan imidlertid være ondsinnede og sende inn falske oppdateringer for å manipulere modellen.
Anvendelser av Føderert Læring
Føderert læring gjør det mulig å trene modeller samtidig som personvernet bevares. Dette er verdifullt i mange ulike scenarioer, som for eksempel:
- Prediksjon av neste ord på smarttelefontastaturer.
- IoT-enheter som kan trene modeller lokalt for å tilpasses spesifikke situasjoner.
- Farmasøytisk og helsesektor.
- Forsvarsindustrien kan også dra nytte av trening av modeller uten å dele sensitiv informasjon.
Rammeverk for Føderert Læring
Det finnes mange rammeverk for implementering av føderert læring. Noen av de mest populære er NVFlare, FATE, Flower og PySft. Les denne guiden for en detaljert sammenligning av de ulike rammeverkene.
Konklusjon
Denne artikkelen har introdusert konseptet føderert læring, hvordan det fungerer, fordeler og ulemper ved implementering. I tillegg har vi sett på noen av de vanligste bruksområdene og rammeverkene for å implementere føderert læring i praksis.
Les deretter en artikkel om de beste MLOps-plattformene for å trene dine maskinlæringsmodeller.