Når vi snakker om «serverløs» databehandling, er det en vanlig misforståelse at det ikke finnes noen servere involvert i denne modellen for å muliggjøre kodekjøring og andre utviklingsprosesser. Dette stemmer ikke.
Etter denne avklaringen, kan du kanskje lure på logikken bak navnet «serverløs».
La meg gi deg et hint: Det handler ikke om «ingen servere», men om *hvordan* serverne håndteres og implementeres. Det er dette «serverløs» egentlig innebærer.
Høres dette forvirrende ut?
Vi skal nå utforske hva serverløs databehandling betyr, og andre relaterte begreper for å fjerne all tvil. Markedet for serverløs teknologi er i rask vekst. Det er anslått at det vil nå 7,7 milliarder dollar i 2021, en betydelig økning fra 1,9 milliarder dollar i 2016.
La oss se nærmere på serverløs databehandling og prøve å forstå årsaken bak dens økende popularitet.
Hva innebærer serverløs databehandling?
Serverløs databehandling er en skymodell der skytjenesteleverandører tilbyr datakraft etter behov og håndterer alle servere, i stedet for at kunder eller utviklere gjør det. Det er en kombinasjon av tjenester, strategier og praksis som gir utviklere muligheten til å lage skybaserte applikasjoner ved å la dem konsentrere seg om koden sin fremfor serveradministrasjon.
Skytjenesteleverandøren, som for eksempel AWS eller Google Cloud Platform, tar ansvar for alle vanlige infrastrukturrelaterte oppgaver, fra ressursallokering, kapasitetsplanlegging, administrasjon, konfigurasjoner og skalering, til patching, oppdateringer, planlegging og vedlikehold. Som et resultat kan utviklere fokusere sin innsats på forretningslogikken i sine prosjekter og applikasjoner.
Denne serverløse dataarkitekturen lagrer ikke dataressurser i flyktig minne. I stedet foregår databehandling i korte, separate deler. Dette betyr at hvis en applikasjon ikke er i bruk, vil ingen ressurser være tildelt den. Du betaler dermed bare for de ressursene du faktisk bruker.
Hovedmålet med serverløs modellen er å forenkle prosessen med å distribuere kode til produksjon. Ofte brukes den også i kombinasjon med mer tradisjonelle tilnærminger, som mikrotjenester. Når serverløs er implementert, vil applikasjonene raskt tilpasse seg etterspørselen og automatisk skalere opp eller ned etter behov.
Serverløs databehandling benytter seg av en hendelsesdrevet modell for å bestemme skaleringsbehov. Utviklere trenger ikke lenger å forutse bruken av en applikasjon for å bestemme hvor mange servere eller båndbredde de trenger. De kan be om flere ressurser basert på økende behov uten forhåndsbestilling, og skalere ned uten problemer når som helst.
Hvordan utviklet serverløs databehandling seg?
Det tradisjonelle systemet hadde utfordringer knyttet til skalerbarhet og smidighet i utvikling og utrulling av applikasjoner. Med et økende behov for kvalitetsapper og kortere tid til markedet, oppstod behovet for et system som kunne tilby mer skalerbarhet og fleksibilitet. Dette førte til utviklingen av cloud computing og serverløse modeller.
Den serverløse modellen har utviklet seg gjennom forskjellige faser, fra monolittisk til mikrotjenester, og til slutt til serverløs arkitektur, eller Function-as-a-Service (FaaS).
- Monolittisk arkitektur er en tradisjonell tilnærming til programvareutvikling, der alle komponenter er tett koblet sammen. Hvis en tjeneste svikter, kan hele applikasjonsserveren og alle tilhørende tjenester krasje.
- Mikrotjenestearkitektur består av en samling mindre tjenester i en stor applikasjon, som distribueres uavhengig for å utføre en bestemt oppgave. Dette muliggjør rask levering av applikasjoner i stor skala og gir utviklere fleksibilitet ved bruk av Infrastructure-as-a-Service (IaaS) og Platform as a Service (PaaS). Valget mellom PaaS og IaaS kan imidlertid være utfordrende i denne modellen.
- Serverløs arkitektur utviklet seg med cloud computing og tilbyr enda mer skalerbarhet og forretningsmessig fleksibilitet. I stedet for IaaS og PaaS, benytter den seg av FaaS og Backend-as-a-Service (BaaS). Her distribueres applikasjoner etter behov, sammen med de nødvendige ressursene. Man trenger ikke å administrere serveren, og man slutter å betale når kodekjøringen er ferdig.
Kjennetegn ved serverløs databehandling
Her er noen av de viktigste kjennetegnene ved serverløs databehandling:
- De fleste applikasjoner som bruker serverløs er basert på enkeltfunksjoner og små kodeenheter.
- Koden kjører kun etter behov, vanligvis i en statsløs programvarebeholder, og skalerer sømløst basert på etterspørsel.
- Kunder trenger ikke å administrere serverne.
- Har hendelsesbasert utførelse, der datamiljøet opprettes når en funksjon utløses eller en hendelse mottas for å utføre forespørselen.
- Tilbyr fleksibel skalerbarhet, slik at du enkelt kan skalere opp eller ned. Når koden er ferdig, avsluttes infrastrukturen og kostnadene spares. Når funksjonen fortsetter å kjøre, kan du skalere opp i det uendelige etter behov.
- Man kan bruke administrerte skytjenester til å håndtere komplekse oppgaver som fillagring, køer, databaser med mer.
Hvordan fungerer serverløs databehandling?
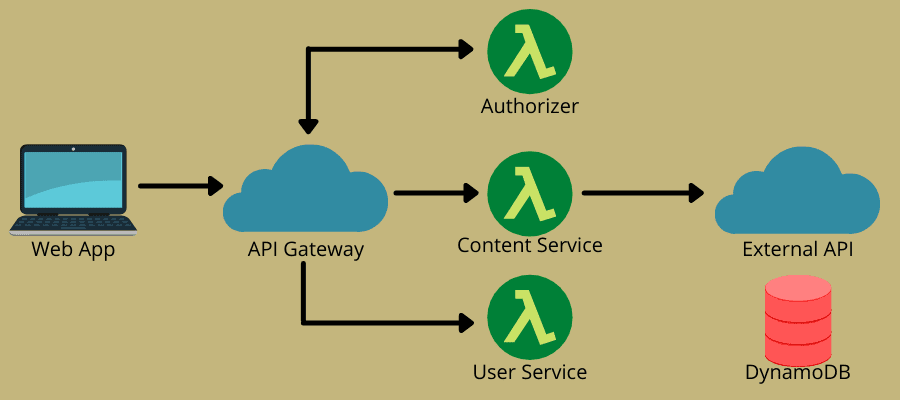
Den serverløse arkitekturen kombinerer to sentrale konsepter: Function-as-a-Service (FaaS) og Backend-as-a-Service (BaaS). Den er i stor grad basert på FaaS, som tillater skytjenester for kodekjøring uten behov for fullstendig forhåndskonfigurerte instanser. FaaS består av statsløse, hendelsesdrevne, skalerbare funksjoner som skytjenester administrerer fullt ut.
Denne modellen lar DevOps-team skrive kode med fokus på forretningslogikken. De definerer en hendelse, som for eksempel en HTTP-forespørsel, som kan utløse en funksjon. Deretter utfører skyleverandøren funksjonen og sender resultatene til applikasjoner som brukerne kan se.
På denne måten tilbyr den serverløse modellen kostnadseffektivitet og brukervennlighet med automatisk skalering, on-demand tjenester og betaling etter bruk. Derfor velger mange bedrifter og DevOps-team serverløs databehandling i dag.
Hvem bruker serverløs og hvorfor?
Serverløs databehandling er en av de raskest voksende teknologiene innen programvareutvikling, med potensial til å eliminere behovet for infrastrukturadministrasjon og klargjøring i fremtiden.
Det er spesielt nyttig for:
- Organisasjoner som ønsker mer skalerbarhet og fleksibilitet med bedre app-testbarhet.
- Utviklere som ønsker å redusere tiden det tar å lansere produkter, ved å bygge smidige applikasjoner med høy ytelse.
- Bedrifter som ikke trenger at serverne deres kjører kontinuerlig. De kan kalle modulbaserte funksjoner ved hjelp av applikasjoner, etter behov, for å spare kostnader.
- Organisasjoner som ønsker å bygge effektive skybaserte apper og forenkle overgangen til skyen.
- Utviklere som ønsker å redusere ventetiden for brukere og tilby enkel tilgang til funksjoner eller applikasjoner.
- Selskaper som mangler tilstrekkelige ressurser til å håndtere vedlikehold og kompleksitet av IT-infrastruktur. Serverløs databehandling kan løse problemer automatisk uten at det kreves vedlikehold fra deres side.
Noen kjente brukere av serverløs modell inkluderer Slack, Coca-Cola, Netflix og flere.
På grunn av sine unike egenskaper er serverløs modellen egnet for mange bruksområder, inkludert:
- Webapplikasjoner: Du kan bygge raske og skalerbare webapplikasjoner som reagerer raskt på brukerkrav. Dette er ideelt for å bygge statsløse apper som kan startes umiddelbart og for apper som må håndtere uforutsigbare, sjeldne økninger i brukerkrav.
- API-backends: I serverløse plattformer kan enhver funksjon enkelt gjøres om til HTTP-endepunkter som er klare for bruk av klienter. Disse funksjonene kalles netthandlinger når de aktiveres på internett. Dette gjør det enkelt å kombinere funksjoner til et fullverdig API. Du kan også bruke en API-gateway for å øke sikkerheten, domene-støtte, hastighetsbegrensning og OAuth-støtte.
- Mikrotjenester: Serverløs er mye brukt i mikrotjenestemodeller som fokuserer på å bygge små tjenester som utfører en enkelt funksjon og kommuniserer med hverandre ved hjelp av API-er. Selv om det er mulig å lage mikrotjenester ved hjelp av programvarebeholdere og PaaS, er serverløs mer effektivt. Det forenkler mindre kodelinjer som utfører én oppgave og tilbyr rask klargjøring, automatisk skalering og fleksible priser som ikke belaster kunder når ressurser ikke er i bruk.
- Databehandling: Serverløs er en utmerket løsning for å håndtere data som inneholder videoer, lyd, bilder og strukturert tekst. Den er også gunstig for oppgaver som datavalidering, transformasjon, berikelse, rensing, lydnormalisering og PDF-behandling. Du kan bruke det for bildebehandling som inkluderer skarphet, rotasjon, generering av miniatyrbilder og støyreduksjon. Annen bruk av serverløs i databehandling kan være videotranskoding og optisk tegngjenkjenning (OCR).
- Strøm-/batchbehandling: Du kan lage kraftige strømmeapplikasjoner og datapipelines ved å bruke FaaS og en database med Apache Kafka. Den serverløse modellen er egnet for ulike typer strømmer, som applogger, IoT-sensorer, forretningslogikk og data fra finansmarkedet.
- Parallell databehandling: Serverløs er utmerket for oppgaver relatert til parallell databehandling, der hver oppgave kjører parallelt for å utføre en spesifikk oppgave. Dette kan omfatte datasøk, behandling, kartoperasjoner, nettskraping, genombehandling, hyperparameterinnstilling og mer.
- Andre bruksområder: Serverløs brukes også i ulike applikasjoner, som Customer Relationship Management (CRM), økonomi, chatbots, business intelligence og analyse.
Vær oppmerksom på at serverløs kanskje ikke er den ideelle løsningen i alle tilfeller. Store applikasjoner med forutsigbar og jevn arbeidsbelastning vil sannsynligvis ha større nytte av en tradisjonell systemarkitektur. Disse kan velge dedikerte servere, enten administrerte eller selvstyrte. I tillegg, hvis organisasjonen din har etablert tradisjonelle oppsett med eldre systemer og applikasjoner, kan det være kostbart og utfordrende å gå over til en helt ny arkitektur.
Fordeler og ulemper med serverløs databehandling
Som alle andre teknologier, har serverløs databehandling både fordeler og ulemper. Før du bestemmer deg for å implementere serverløs, er det viktig å være klar over begge sider for å vurdere om det vil være en god løsning for din organisasjon.
Fordeler 👍
Her er noen av fordelene med serverløs arkitektur:
Kostnadseffektivt
Serverløs kan være mer kostnadseffektivt enn å kjøpe eller leie servere, der du må betale for ressurser selv om du ikke bruker dem.
Serverløs bruker en «betal-etter-bruk»-modell, der du kun betaler for de ressursene du faktisk bruker. Den serverløse leverandøren belaster deg kun for minnet som er tildelt og tiden det tar å kjøre koden, uten kostnader for inaktiv tid.
Dette gir besparelser på driftskostnader knyttet til installasjon, lisenser, vedlikehold, patching og support. Uten servermaskinvare sparer du også arbeidskostnader.
Skalerbarhet
Serverløse systemer tilbyr et høyt nivå av skalerbarhet. Du kan skalere opp eller ned etter behov. De kalles også «elastiske» av denne grunn.
Utviklere trenger ikke å bruke tid på å konfigurere eller justere autoskalingssystemer. Skyleverandøren håndterer dette. Utviklere i små team kan også kjøre koden sin uten behov for støtteingeniører eller infrastruktur.
Redusert ventetid
Siden apper ikke er vert på en enkelt server, kan du kjøre koden fra hvor som helst. Hvis skyleverandøren støtter det, kan du kjøre appfunksjoner på en server som er nær sluttbrukerne. Dette reduserer ventetiden.
Produktivitet
Serverløs hjelper til med å øke utviklernes produktivitet, da de ikke trenger å håndtere serveradministrasjon. De trenger heller ikke å tenke på å håndtere HTTP-forespørsler eller multithreading direkte i koden.
Dette forenkler backend-utvikling, takket være FaaS, der eksponert kode er hendelsesdrevne funksjoner. Alt dette sparer tid, som kan brukes til å forbedre koden og applikasjonen.
Raskere app-implementering
Med serverløs trenger ikke utviklere å konfigurere backend eller laste opp kode til serveren for å distribuere en ny appversjon. De kan også raskt laste opp koden i mindre deler for å lansere nye produkter.
De har også fleksibilitet til å distribuere kode enten samtidig eller sekvensielt, siden det ikke er en monolittisk arkitektur. I tillegg kan de raskt patche, oppdatere, legge til funksjoner eller fikse feil i applikasjonen.
Andre fordeler inkluderer miljøvennlig databehandling med redusert energiforbruk, enklere apputvikling med innebygde integrasjoner, raskere tid til markedet, og mer.
Ulemper 👎
La oss se på ulempene med serverløs databehandling:
Ytelse
Noen ganger kan serverløs kode som sjeldnere brukes vise større forsinkelse enn kode som kjører kontinuerlig på dedikerte servere eller virtuelle maskiner. Dette skyldes at det kan ta lengre tid å starte opp på nytt, noe som skaper ekstra ventetid.
Vanskelig å feilsøke og teste
Det er viktig å ha innsikt i hvordan koden fungerer etter implementering. Dette krever testing, som kan være utfordrende i et serverløst miljø. Manglende innsikt i hver backend-prosess, og applikasjoner som er delt opp i mindre funksjoner, kompliserer feilsøkingen.
Sikkerhetsproblemer
Nye og avanserte cybersikkerhetsproblemer oppstår. Det er vanskelig å fullt ut vite eller måle sikkerheten til skyleverandøren. Når de administrerer hele backend-en din med sensitive data lagret i applikasjonene, kan det være risikabelt.
Ikke egnet for langvarige prosesser
Serverløs er kostnadseffektivt, men ikke for alle typer applikasjoner. Hvis du har en applikasjon med langvarige prosesser, kan kostnadene for å kjøre den basert på tid og ressurser være svært høy. I slike tilfeller kan det være bedre å bruke dedikert serverhosting.
Andre ulemper med serverløs inkluderer problemer med å bytte leverandør og personvernproblemer.
Viktige begreper i serverløs arkitektur
Det er viktig å forstå noen sentrale begreper relatert til serverløs. FaaS og BaaS er to av de mest fremtredende konseptene som førte til utviklingen av den serverløse modellen vi kjenner i dag. I tillegg trenger du en database, et lagringssystem, en teknologistabel og et rammeverk for å bygge et serverløst system. La oss se nærmere på noen av disse begrepene.
Function-as-a-Service (FaaS)
FaaS er en sentral del av serverløs databehandling. Denne hendelsesdrevne modellen for kodekjøring (apper som kjører som svar på en forespørsel) lar deg skrive logikk som distribueres i programvarebeholdere, utføres etter behov, og håndteres av en skyplattform.
Sammenlignet med BaaS gir FaaS utviklere mer kontroll over å lage tilpassede apper, istedenfor å være avhengig av biblioteker som inneholder forhåndsdefinert kode.
Programvarebeholderne der koden utplasseres er statsløse for å forenkle dataintegrasjon, og koden kjører i en kortere tidsperiode. Utviklere kan også kalle serverløse applikasjoner via API-er ved å bruke FaaS, som skyleverandørene administrerer via en API-gateway.
Backend-as-a-Service (BaaS)
BaaS ligner på FaaS, ved at begge benytter seg av en tredjeparts tjenesteleverandør. I denne modellen tilbyr en skyleverandør backend-tjenester, som for eksempel datalagring, for å hjelpe utviklere med å fokusere på frontend-koden. BaaS-applikasjoner er imidlertid ikke nødvendigvis hendelsesdrevne eller kjøres på kanten som serverløse applikasjoner.
Et godt eksempel på BaaS er AWS Lambda. Utviklere bruker serverløs kode i containere med Lambda, som gir retningslinjer for hvordan koden skal sendes inn. Det automatiserer også prosessen med å legge koden i programvarebeholdere og tilbyr en administrert tjeneste.
Serverløs stabel
Som alle andre programvareteknologier, har også serverløs arkitektur en teknologistabel. Den samler ulike komponenter som er avgjørende for å skape et serverløst system eller applikasjon.
Den serverløse stabelen inkluderer:
- Et programmeringsspråk: Språket som utviklerne bruker til å skrive koden. Du kan velge mellom Java, JavaScript, Python, C#, Go, Node.js, F# og mer, avhengig av leverandøren.
- Et serverløst rammeverk: Et rammeverk gir strukturen til koden. Det finnes mange serverløse rammeverk du kan velge mellom. De gjør det mulig å bygge, pakke og kompilere kode og til slutt distribuere til skyen. Serverløse rammeverk fremskynder prosessen med koding og forenkler skalering med redusert konfigurasjonstid. Eksempler på serverløse rammeverk er Apex, AWS Serverless Application Model, etc.
- Serverløse databaser: Disse brukes til å lagre data som koden trenger tilgang til. De er også nødvendige for å samhandle med funksjoner for triggere. Serverløse databaser oppfører seg som serverløse funksjoner, men lagrer data på ubestemt tid. Eksempler på serverløse databaser er DynamoDB, Azure Cosmos DB, Aurora Serverless og Cloud Firestore.
- Et sett med triggere: Disse bidrar til å starte kodekjøringen, for eksempel HTTP-forespørsler.
- Programvarebeholdere: De forbedrer den serverløse modellen og tilbyr containerbaserte mikrotjenester uten kompleksitet. De fungerer også som et oppbevaringssted for koden og forenkler utvikling av kode for flere plattformer, som PC eller iOS.
- API-porter: De fungerer som en proxy for netthandlinger. De tilbyr HTTP-ruting, hastighetsbegrensninger, visning av API-bruk, svarlogger, klient-ID og mer.
Hvordan implementere en serverløs modell og optimalisere den?
Overgangen til en serverløs modell vil medføre betydelige endringer i applikasjoner, teknologi, kostnader, sikkerhet og fordeler.
Hvis du er en nystartet bedrift eller en liten bedrift, vil serverløs databehandling bidra til å akselerere tiden til markedet og gjøre det enklere å lansere oppdateringer raskt. Med forenklet testing, feilsøking, tilbakemeldinger og mer, vil du raskt kunne tilby en ferdig applikasjon til brukerne.
Større organisasjoner vil oppleve fordeler som økt skalerbarhet, men implementeringen vil kreve betydelige investeringer.
Derfor er det viktig å nøye vurdere fordeler og ulemper med serverløs databehandling spesielt for din virksomhet og dens behov før du går videre. Hvis du er seriøs med å implementere serverløs, bør du starte med følgende:
- Forstå dine behov og identifiser en passende serverløs teknologistabel.
- Velg en serverløs leverandør som Google Cloud Functions, Azure Functions, AWS Lambda osv.
- Gi teamet ditt verktøy for å overvåke systemytelsen og funksjonene. Se på totalt antall forespørsler, begrensninger, feiltelling, suksessrater, varighet av forespørsler og ventetid.
Serverløse leverandører

Det finnes mange serverløse leverandører på markedet i dag. Noen av de beste er:
- AWS Lambda: Perfekt for organisasjoner som allerede bruker AWS-tjenester. Den integreres med et bredt spekter av tjenester for lagring, strømming og databaser.
- Microsoft Azure Functions: Hvis du bruker Visual Studio Code, er dette et godt valg. Det fungerer problemfritt med DevOps og Azure Pipelines for CI/CD. Den støtter også Durable Functions for stateful funksjoner og tilbyr integrert overvåking.
- Google Cloud Functions: Et godt valg hvis du bruker Google-tjenester. Den støtter JS-, Go- og Python-apper, lar deg trigge funksjoner fra Google Assistant eller GCP, og tilbyr innebygd skalering.
- IBM Cloud Functions: Hvis du vil bruke en serverløs modell basert på Apache OpenWhisk, er IBM Cloud Functions noe for deg. Den inkluderer utmerket ytelsesovervåking, hendelsesutløsning fra en REST API eller IBM skytjenester, og integreres med IBMs API Gateway for å administrere endepunkter.
- Knative: Hvis du kjører tjenester på Kubernetes, er dette et godt valg. Det støttes av Google, Red Hat og IBM, blant andre.
- Cloudflare Workers: Flott for apper som krever rask respons, spesielt JavaScript-apper. Den støtter Workers KV for datalagring og WebAssembly for å hjelpe deg med å kompilere og levere flere språk. Det store distribusjonsnettverket med 193 datasentre bidrar til å redusere ventetid og øke responsen.
Konklusjon: Fremtiden til serverløs
Serverløs databehandling er i stadig utvikling med den økende etterspørselen etter svært skalerbare applikasjoner. Det gir også mange fordeler som cloud computing tilbyr, som mer bekvemmelighet, kostnadseffektivitet og høyere produktivitet.
I følge en O’Reilly-undersøkelse jobber 40 % av respondentene i selskaper som har tatt i bruk serverløs arkitektur.
Selv om serverløs fortsatt har noen utfordringer, som ventetid på grunn av kaldstart, testing og feilsøking, jobber skyleverandører med å løse disse. Det er sannsynlig at en mer raffinert form for serverløs vil dukke opp med flere fordeler og løste problemer. Derfor forventes populariteten og bruken av serverløs modell å øke i fremtiden.
Du kan også være interessert i: 7 måter serverløs databehandling er en stigende teknologi