En Dypdykk i Pandas: Python’s Ledende Bibliotek for Dataanalyse
Pandas er et uomgjengelig verktøy innen dataanalyse for Python. Det er et førstevalg for dataanalytikere, forskere og maskinlæringsingeniører.
Sammen med NumPy, utgjør det en essensiell del av verktøykassen for alle som arbeider med data og kunstig intelligens.
Denne artikkelen gir en omfattende oversikt over Pandas og funksjonene som har gjort det til en sentral aktør i dataøkosystemet.
Hva er Pandas?
Pandas er et dataanalyseverktøy for Python. Det gir deg mulighet til å jobbe med og manipulere data direkte fra Python-koden. Du kan effektivt lese, redigere, visualisere, analysere og lagre data.
Navnet «Pandas» er en sammenslåing av ordene Panel Data, et begrep fra økonometri som omhandler data fra observasjoner av flere individer over tid. Pandas ble lansert i januar 2008 av Wes Kinney og har siden da utviklet seg til å bli det mest populære biblioteket innen sitt felt.
I kjernen av Pandas finner vi to grunnleggende datastrukturer: Dataframes og Series. Når et datasett opprettes eller lastes inn i Pandas, representeres det som en av disse strukturene.
Neste avsnitt utforsker disse datastrukturene i detalj, ser på forskjellene og når hver enkelt er mest hensiktsmessig å bruke.
Sentrale Datastrukturer
Som tidligere nevnt, er alle data i Pandas organisert i enten en dataramme eller en serie. La oss se nærmere på disse to strukturene:
Dataramme
Datamaterialet i dataramme-eksempelet under er generert ved hjelp av kodebiten som presenteres i bunnen av dette avsnittet.
En dataramme i Pandas er en todimensjonal struktur med kolonner og rader. Den kan sammenlignes med et regneark i et regnearkprogram eller en tabell i en relasjonsdatabase.
Datarammer består av kolonner, hvor hver kolonne representerer en egenskap eller et attributt i datasettet. Disse kolonnene består igjen av individuelle verdier, organisert som et serieobjekt. Vi vil se nærmere på serie-datastrukturen senere i artikkelen.
Kolonnene i en dataramme er navngitt slik at de er lette å skille fra hverandre. Disse navnene settes i forbindelse med opprettelsen eller innlasting av datarammen, men kan enkelt endres ved behov.
Dataene i en kolonne må være av samme type, selv om kolonnene ikke trenger å inneholde samme datatyper. For eksempel vil en navne-kolonne kun lagre strenger, mens en annen kolonne kan lagre heltall som alder.
Datarammer har også en indeks for å referere til radene. Verdier på tvers av ulike kolonner med samme indeks utgjør en rad. Som standard er indeksene nummererte, men kan endres for å tilpasses datasettet. I eksemplet nedenfor (og bildet over) har vi satt indekskolonnen til «måneder».
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
print(sales_df)
Serie
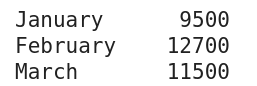
Denne eksempelserien er generert ved hjelp av koden som presenteres nederst i dette avsnittet.
Som tidligere nevnt brukes en serie til å representere en kolonne med data i Pandas. En serie er derfor en endimensjonal struktur, i motsetning til en todimensjonal dataramme.
Selv om en serie ofte brukes som en kolonne i en dataramme, kan den også representere et komplett datasett, forutsatt at datasettet kun inneholder ett attributt som er registrert i en enkel kolonne – eller rettere sagt, en liste over verdier.
Siden en serie kun representerer en enkelt kolonne, trenger den ikke å ha et navn, men verdiene i serien er indeksert. På samme måte som for en dataramme, kan indeksen i en serie endres fra standardnummereringen.
I eksemplet over (og kodebiten under), er indeksen satt til ulike måneder ved hjelp av set_axis-metoden i et Pandas Series-objekt.
import pandas as pd total_sales = pd.Series([9500, 12700, 11500]) months = ['January', 'February', 'March'] total_sales = total_sales.set_axis(months) print(total_sales)
Kjennetegn ved Pandas
Nå som vi har etablert en grunnleggende forståelse for hva Pandas er og hvilke datastrukturer den bruker, kan vi se nærmere på hva som gjør Pandas til et så kraftig dataanalyseverktøy og hvorfor det er så utrolig populært innen datavitenskap og maskinlæring.
#1. Datamanipulasjon
Dataframe- og Series-objektene er dynamiske og kan endres etter behov. Du kan legge til eller fjerne kolonner, legge til rader og til og med slå sammen datasett.
Pandas gjør det mulig å utføre numeriske beregninger som normalisering og logiske sammenligninger på elementnivå. Du kan også gruppere data og benytte aggregerte funksjoner som gjennomsnitt, median, maksimum og minimum. Dette gjør databehandling i Pandas til en effektiv prosess.
#2. Datavask
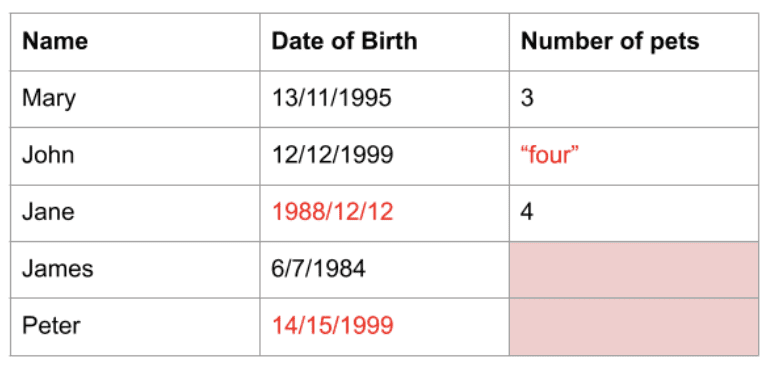
Data hentet fra den virkelige verden har ofte verdier som er vanskelige å jobbe med. Dataene kan være av feil type, i feil format eller det kan mangle verdier. Slik data må behandles før den er egnet for analyse eller bruk i maskinlæringsmodeller. Dette kalles datavask.
Pandas tilbyr funksjoner som gjør det lettere å utføre datavask. Du kan for eksempel slette dupliserte rader, fjerne kolonner eller rader med manglende data, eller erstatte verdier med standardverdier eller andre verdier som gjennomsnitt. Pandas har et bredt utvalg av funksjoner og biblioteker som kan brukes for å forenkle datavask.
#3. Datavisualisering
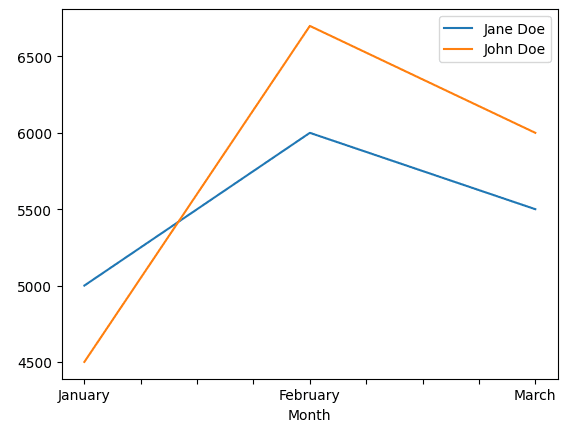
Denne grafen er generert ved hjelp av koden som presenteres nederst i dette avsnittet.
Selv om Pandas ikke er et fullverdig visualiseringsbibliotek som Matplotlib, tilbyr det likevel funksjoner for å lage grunnleggende datavisualiseringer. Disse er tilstrekkelige for de fleste behov.
Med Pandas kan du enkelt plotte søylediagrammer, histogrammer, spredningsdiagrammer og mange andre typer visualiseringer. Ved å kombinere datamanipulasjon i Python kan du lage enda mer avanserte visualiseringer for en dypere forståelse av dataene.
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
sales_df.plot.line()
#4. Tidsserieanalyse
Pandas er også egnet for arbeid med tidsstemplede data. Når Pandas gjenkjenner en kolonne med datetime-verdier, kan du utføre en rekke operasjoner som er nyttige for analyse av tidsseriedata.
Dette inkluderer gruppering av observasjoner etter tidsperiode og bruk av aggregerte funksjoner som sum eller gjennomsnitt. Du kan også finne de tidligste eller seneste observasjonene ved hjelp av min og maks. Det finnes en rekke verktøy for tidsserieanalyse i Pandas.
#5. Input/Output i Pandas
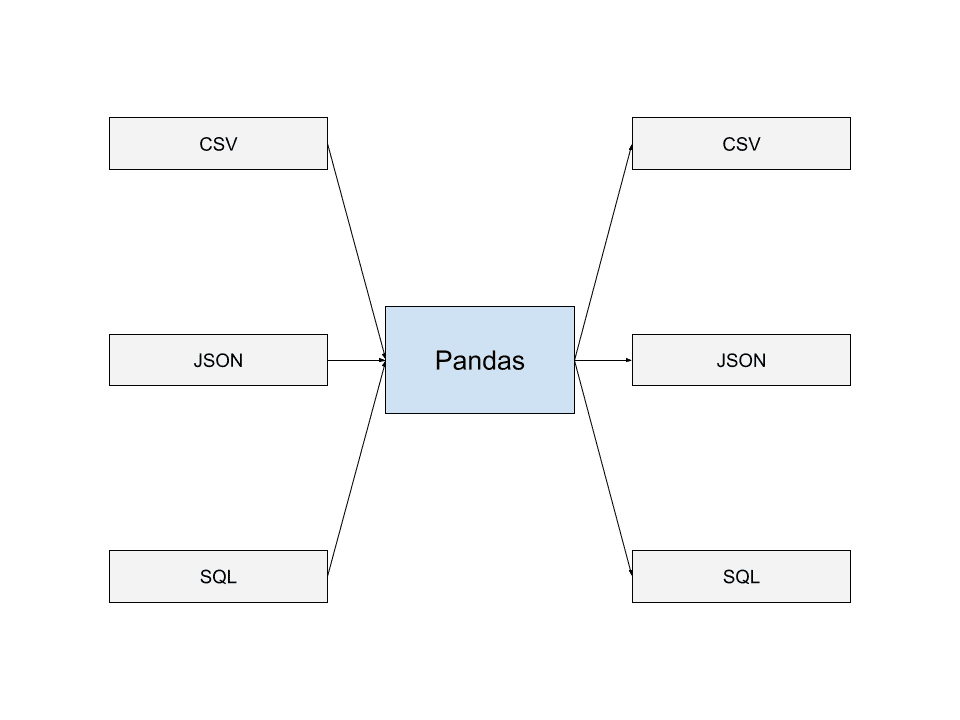
Pandas har evnen til å lese data fra de vanligste datalagringsformatene, som JSON, SQL Dumps og CSV. Du kan også skrive data til filer i mange av disse formatene.
Evnen til å lese og skrive fra ulike datafilformater gjør at Pandas kan integreres sømløst med andre applikasjoner og datapipelines. Dette er en av hovedårsakene til Pandas» utbredte bruk.
#6. Integrasjon med andre biblioteker
Pandas har et bredt økosystem av verktøy og biblioteker som er utviklet for å utfylle dens funksjonalitet. Dette gjør Pandas til et enda mer allsidig og kraftig bibliotek.
Verktøy i Pandas-økosystemet forbedrer funksjonaliteten innenfor datavask, visualisering, maskinlæring, input/output og parallellisering. Pandas har en oversikt over disse verktøyene i sin dokumentasjon.
Ytelse og Effektivitet i Pandas
Selv om Pandas er et effektivt verktøy i de fleste operasjoner, kan det også være langsomt. Heldigvis er det mulig å optimalisere koden for å øke hastigheten. Dette krever en forståelse av hvordan Pandas er bygget.
Pandas er bygget oppå NumPy, et populært Python-bibliotek for numeriske og vitenskapelige beregninger. Som NumPy fungerer Pandas mer effektivt når operasjoner vektoriseres i stedet for å behandle enkeltceller eller rader med løkker.
Vektorisering er en form for parallellisering der samme operasjon utføres på flere datapunkter samtidig. Dette kalles SIMD – Single Instruction, Multiple Data. Ved å utnytte vektoriserte operasjoner kan hastigheten og ytelsen til Pandas forbedres betydelig.
Siden de underliggende datastrukturene i Pandas benytter NumPy-matriser, er DataFrame- og Series-strukturene raskere enn alternative datastrukturer som lister og ordbøker.
Standardimplementasjonen av Pandas kjører på kun én CPU-kjerne. En annen måte å øke hastigheten på koden er å bruke biblioteker som lar Pandas benytte alle tilgjengelige CPU-kjerner. Disse inkluderer Dask, Vaex, Modin og IPython.
Fellesskap og Ressurser
Som et populært bibliotek for det mest populære programmeringsspråket, har Pandas et stort fellesskap av brukere og bidragsytere. Dette betyr at det finnes mange ressurser tilgjengelig for å lære å bruke det. Disse inkluderer den offisielle Pandas-dokumentasjonen, i tillegg til utallige kurs, veiledninger og bøker.
Det finnes også nettsamfunn på plattformer som Reddit, spesielt i r/Python og r/Data Science subreddits, der du kan stille spørsmål og få svar. Som et åpen kildekode-bibliotek kan du også rapportere problemer på GitHub og til og med bidra med kode.
Avsluttende Ord
Pandas er et utrolig nyttig og kraftig bibliotek innen datavitenskap. I denne artikkelen har vi forsøkt å belyse dens popularitet ved å se nærmere på de funksjonene som gjør det til et uvurderlig verktøy for dataforskere og programmerere.
Som neste steg kan du se nærmere på hvordan man lager en Pandas DataFrame.