Utforskning av Forsterkningslæring: En Dybdegående Veiledning
I kjernen av moderne kunstig intelligens (KI) finner vi forsterkningslæring (FL), et forskningsområde som genererer betydelig interesse. Utviklere innen KI og maskinlæring (ML) anvender FL for å skape mer avanserte applikasjoner og verktøy.
Maskinlæring er grunnlaget for all KI-teknologi. Utviklere benytter ulike ML-teknikker for å trene intelligente systemer, spill og apper. Mangfoldet innen ML er stort, og det dukker stadig opp nye metoder for maskinopplæring.
En særlig lovende tilnærming er dyp forsterkningslæring. Her belønnes ønsket atferd hos den intelligente maskinen, mens uønsket atferd straffes. Eksperter ser på denne metoden som avgjørende for at KI skal kunne lære av egen erfaring.
Dersom du vurderer en karriere innen kunstig intelligens og maskinlæring, er det viktig å forstå forsterkningslæring. Denne veiledningen gir en grundig innføring i metodene som brukes for å trene intelligente apper og maskiner.
Hva er Forsterkningslæring i Maskinlæring?
FL innebærer opplæring av maskinlæringsmodeller for dataprogrammer. Disse modellene gir programmet evnen til å ta beslutninger i et komplekst og usikkert miljø. En FL-modell kan sees på som en spill-lignende situasjon for KI.
KI-applikasjonen bruker prøving og feiling for å finne kreative løsninger. Når den har lært de korrekte modellene, kan den instruere den kontrollerte maskinen til å utføre spesifikke oppgaver.
Ved vellykket utførelse av oppgaver mottar KI en belønning, mens feil handlinger fører til straff, som tap av belønningspoeng. Målet for KI-applikasjonen er å maksimere belønningspoengene for å vinne «spillet».
Programmereren av KI-appen definerer spillereglene og belønningssystemet, samt problemet som KI skal løse. I motsetning til andre ML-modeller får ikke KI-programmet direkte hjelp eller tips fra programmereren.
KI må selv finne ut hvordan man løser utfordringene for å oppnå maksimale belønninger. Dette kan inkludere prøving og feiling, tilfeldige forsøk, bruk av avansert datakraft og sofistikerte tankeprosesser.
For å oppnå optimal ytelse, må KI-programmet ha tilgang til kraftig datainfrastruktur og være koblet til ulike parallelle og historiske spill. Dette gir KI muligheten til å demonstrere kreativitet på et nivå som overgår menneskelige evner.
Fremtredende Eksempler på Forsterkningslæring
#1. Beseire den beste Go-spilleren
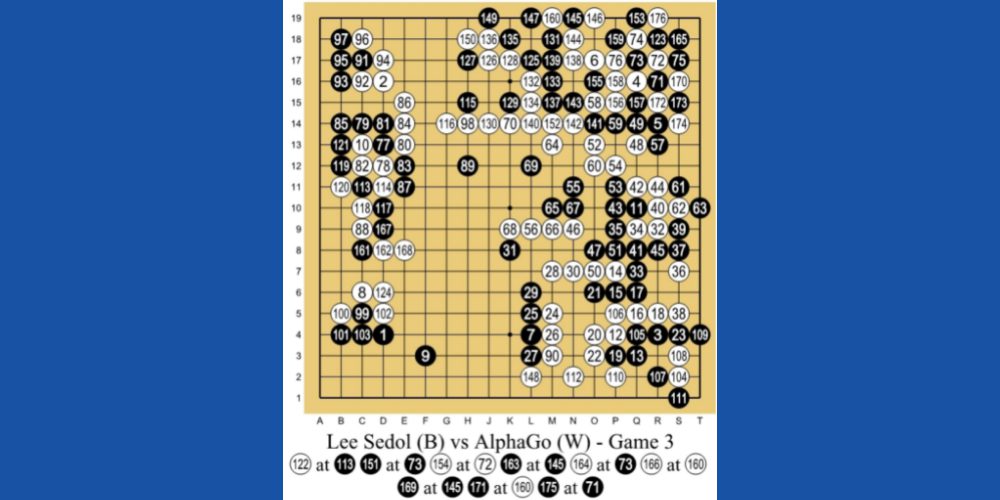
AlphaGo, utviklet av DeepMind Technologies (et Google-datterselskap), er et bemerkelsesverdig eksempel på FL-drevet maskinlæring. AlphaGo er en KI som spiller det kinesiske brettspillet Go, et 3000 år gammelt spill som krever taktikk og strategi.
Gjennom FL trente programmererne AlphaGo ved å la den spille tusenvis av partier mot både mennesker og seg selv. I 2016 oppnådde AlphaGo en historisk seier over verdens beste Go-spiller, Lee Se-dol.
#2. Robotikk i den Virkelige Verden
Roboter har lenge blitt brukt i produksjonslinjer for repetetive oppgaver. Imidlertid er det en stor utfordring å utvikle roboter som kan operere i den virkelige verden hvor handlinger ikke er forhåndsprogrammert.
FL-drevet KI gir robotene muligheten til å navigere og finne effektive ruter mellom to punkter.
#3. Selvkjørende Kjøretøy
Forskere innen autonome kjøretøy bruker FL for å trene sine KI-er i:
- Dynamisk baneberegning
- Optimalisering av baner
- Planlegging av bevegelser som parkering og filskifte
- Optimalisering av kontrollere (ECUer, MCUs)
- Scenariobasert læring på motorveier
#4. Automatiserte Kjølesystemer

FL-basert KI bidrar til å minimere energiforbruket i kjølesystemer i store kontorbygg, kjøpesentre og datasentre. KI analyserer data fra tusenvis av varmesensorer, samt informasjon om menneskelig aktivitet. Dette gjør det mulig for KI å forutsi fremtidig varmegenerering og justere kjølesystemene for å spare energi.
Hvordan Sette Opp en Forsterkningslæringsmodell
Oppsettet av en FL-modell kan baseres på følgende metoder:
#1. Politikkbasert
Denne tilnærmingen gjør det mulig for programmereren å finne den optimale strategien for å oppnå maksimale belønninger uten å bruke en verdifunksjon. Forsterkningslæringsagenten forsøker å bruke denne strategien for å maksimere belønningspoengene i hvert trinn.
Det finnes to hovedtyper strategier:
#1. Deterministisk: Strategien gir samme handling i en gitt situasjon.
#2. Stokastisk: Handlingen bestemmes av sannsynligheten for hendelser.
#2. Verdibasert
Den verdibaserte tilnærmingen fokuserer på å finne den optimale verdifunksjonen, som representerer den maksimale verdien under en gitt strategi. Agenten forventer langsiktig avkastning i en eller flere situasjoner.
#3. Modellbasert
I den modellbaserte tilnærmingen lager programmereren en virtuell modell av miljøet. FL-agenten navigerer og lærer av denne modellen.
Typer Forsterkningslæring
#1. Positiv Forsterkningslæring (PFL)
Positiv læring innebærer å legge til elementer som øker sannsynligheten for at ønsket atferd gjentas. Denne metoden påvirker agentens atferd positivt og styrker spesifikke handlinger.
PFL forbereder KI til å tilpasse seg endringer over tid. For mye positiv læring kan imidlertid føre til en overbelastning av situasjoner, noe som kan redusere effektiviteten.

#2. Negativ Forsterkningslæring (NFL)
Når FL-algoritmen hjelper KI med å unngå eller stoppe negativ atferd, lærer den av det og forbedrer fremtidige handlinger. NFL gir imidlertid KI en begrenset intelligens som kun oppfyller visse atferdskrav.
Praktiske Bruksområder for Forsterkningslæring
#1. E-handelsløsninger bruker FL for å utvikle personlig tilpassede anbefalingsverktøy. Disse verktøyene lærer av brukernes atferd og foreslår relevante produkter og tjenester.
#2. Åpne videospill benytter KI for å tilpasse spillopplevelsen. KI-programmet lærer av spillernes handlinger og endrer spillkoden for å tilpasse seg ukjente situasjoner.
#3. KI-baserte aksjehandelsplattformer bruker FL for å lære av bevegelsene i aksjemarkeder. Dette danner grunnlaget for å foreslå investeringer.
#4. Online videobiblioteker, som YouTube, bruker FL for å anbefale personaliserte videoer til brukerne.
Forsterkningslæring vs. Veiledet Læring
Forsterkningslæring fokuserer på å trene KI-agenter til å ta sekvensielle beslutninger. Utgangen avhenger av den nåværende inngangen, og den neste inngangen avhenger av tidligere utganger. Et sjakkspillende KI er et eksempel på dette.

I veiledet læring trenes KI-agenten til å ta beslutninger basert på gitte innganger. Autonome kjøretøy som gjenkjenner objekter er et eksempel på veiledet læring.
Forsterkningslæring vs. Uovervåket Læring
FL lærer KI-agenten å ta beslutninger basert på belønningssystemer. KI lærer gjennom prøving og feiling.
I uovervåket læring presenteres KI for umerkede data uten forhåndsdefinert struktur. Algoritmen lærer beslutninger ved å katalogisere egne observasjoner på disse datasettene.
Forsterkningslæringskurs
Nå som du har lært det grunnleggende, er det mange online kurs som kan gi deg avansert kunnskap om forsterkningslæring. Disse kursene gir også sertifikater som kan presenteres på LinkedIn og andre sosiale medier:
Forsterkende Læringsspesialisering: Coursera
Dette Coursera RL kurs er utmerket for å forstå kjernekonsepter innen forsterkningslæring. Kurset tilbyr fleksible lærings- og sertifiseringsmuligheter, og er egnet for de med følgende bakgrunn:
- Programmeringskunnskap i Python
- Grunnleggende statistikk
- Evne til å konvertere pseudokoder og algoritmer til Python-kode
- Erfaring med programvareutvikling
- Andreårs studenter i informatikk
Kurset har en høy vurdering og mange deltakere. Det tilbyr også økonomisk støtte for kvalifiserte kandidater. Kurset leveres av Alberta Machine Intelligence Institute ved University of Alberta med anerkjente professorer som instruktører. Ved fullført kurs mottas et Coursera-sertifikat.
AI Forsterkningslæring i Python: Udemy
Dette Udemy-kurs er ideelt for de som arbeider med finansmarkedet eller digital markedsføring. Det lærer hvordan man utvikler intelligente programvarepakker for disse feltene.

Noen viktige temaer som dekkes i kurset:
- En oversikt over FL
- Dynamisk programmering
- Monte Carlo-metoder
- Tilnærmingsmetoder
- Aksjehandelsprosjekt med FL
Kurset er høyt rangert og tilgjengelig på flere språk.
Dyp Forsterkningslæring i Python: Udemy
Dette avanserte RL-kurset på Udemy er for de som har en grunnleggende forståelse av dyp læring og kunstig intelligens. Det er et populært valg for å lære RL i forbindelse med AI/ML.

Kurset dekker:
- OpenAI Gym og grunnleggende RL-teknikker
- TD Lambda
- A3C
- Theano og Tensorflow
- Grunnleggende Python
Kurset består av forelesninger og tekstbasert materiale.
Dyp Forsterkningslæring Ekspert: Udacity
Dette Dyp forsterkningslæring-kurset fra Udacity lar deg lære av eksperter fra Nvidia Deep Learning Institute og Unity.

Forutsetninger for å delta i kurset er avansert kunnskap i Python, statistikk, sannsynlighetsteori, TensorFlow, PyTorch og Keras.
Kurset krever 4 måneders engasjement. Du vil lære viktige RL-algoritmer som Deep Deterministic Policy Gradients (DDPG) og Deep Q-Networks (DQN).
Avsluttende Ord
Forsterkningslæring er et spennende felt innen KI-utvikling. IT-selskaper investerer betydelig for å skape pålitelige treningsmetoder.
Selv om FL har utviklet seg raskt, er det fortsatt områder som krever videre forskning. For eksempel deler ikke separate RL-agenter kunnskap med hverandre, noe som begrenser effektiviteten i komplekse situasjoner.
Det er mange muligheter til å investere kreativitet og ML-ekspertise i slike utfordringer. Ved å ta online-kurs kan du øke kunnskapen din om avanserte FL-metoder og deres praktiske anvendelser.
Det er også viktig å forstå forskjellene mellom KI, maskinlæring og dyp læring, som er relatert til dette emnet.