Alternative metoder for tilgangskontroll i AWS S3
I tidligere tider, med lokale Unix-servere og store filsystemer, utviklet organisasjoner omfattende systemer for mappeadministrasjon. Disse systemene fokuserte på å kontrollere tilgangen til ulike mapper for ulike brukere.
Ofte vil en organisasjons plattform betjene forskjellige brukergrupper med varierende behov, konfidensialitetskrav eller definisjoner av innhold. I globale organisasjoner kan dette innebære å skille innhold basert på geografisk plassering, og dermed skille mellom brukere fra forskjellige land.
Andre typiske eksempler inkluderer:
- Datasikring mellom utviklings-, test- og produksjonsmiljøer
- Salgsdokumenter som ikke skal være offentlig tilgjengelige
- Landsspesifikt juridisk innhold som ikke skal kunne leses i andre regioner
- Prosjektrelatert data hvor tilgang til «lederdata» er begrenset til en utvalgt gruppe
Listen over slike eksempler er nærmest uendelig. Essensen er at det alltid eksisterer et behov for å regulere tilgangen til filer og data mellom alle brukerne som plattformen gir tilgang til.
Med lokale løsninger var dette en standardoppgave. Systemadministratoren definerte regler, brukte et relevant verktøy, grupperte brukere, og koblet grupper til mapper eller monteringspunkter med tilgangsrettigheter, enten skrivebeskyttet eller lese- og skrivetilgang.
Med AWS sine skyplattformer er det naturlig å forvente at brukere har lignende krav til tilgangsbegrensninger. Men, løsningen må være annerledes. Filer eksisterer ikke lenger på Unix-servere, men i skyen, og er potensielt tilgjengelige globalt. Innhold lagres ikke i mapper, men i S3-bøtter.

Nedenfor beskrives en alternativ fremgangsmåte for å håndtere dette problemet, basert på erfaringer fra et faktisk prosjekt.
En enkel, men manuell tilnærming
En relativt enkel og rask metode, uten automatisering, er å:
- Opprette en egen S3-bøtte for hver unik brukergruppe.
- Tildele tilgangsrettigheter til hver bøtte slik at bare den spesifikke gruppen har tilgang.
Denne tilnærmingen kan være akseptabel for en rask og enkel løsning, men har sine begrensninger.
Som standard er det mulig å opprette maksimalt 100 S3-bøtter per AWS-konto. Denne grensen kan økes til 1000 ved å sende inn en forespørsel til AWS. Hvis dette er tilstrekkelig for ditt behov, kan du bruke separate S3-bøtter for alle domenebrukere.
Problemer oppstår når noen grupper har felles ansvar, eller brukere trenger tilgang til innhold på tvers av flere domener. For eksempel:
- Dataanalytikere som evaluerer data fra flere områder eller regioner.
- Testteam som jobber med tjenester for ulike utviklingsteam.
- Rapporteringsbrukere som trenger analyser fra flere land i samme region.
Denne listen kan vokse betydelig, og organisasjoners behov vil generere mange ulike brukstilfeller.
Jo mer kompleks listen blir, jo mer kompleks blir tilgangskontrollen. Det vil kreve ekstra verktøy, og eventuelt en dedikert ressurs (administrator) for å vedlikeholde tilgangsrettighetene og oppdatere dem når endringer forespørres (som kan være ofte, spesielt i store organisasjoner).
Hvordan kan vi da oppnå dette på en mer organisert og automatisert måte?
Hvis en bøtte per domene ikke fungerer, vil andre løsninger kreve delte bøtter for flere brukergrupper. I slike tilfeller er det nødvendig å bygge all logikk for å tildele tilgang i et område som er lett å endre dynamisk.
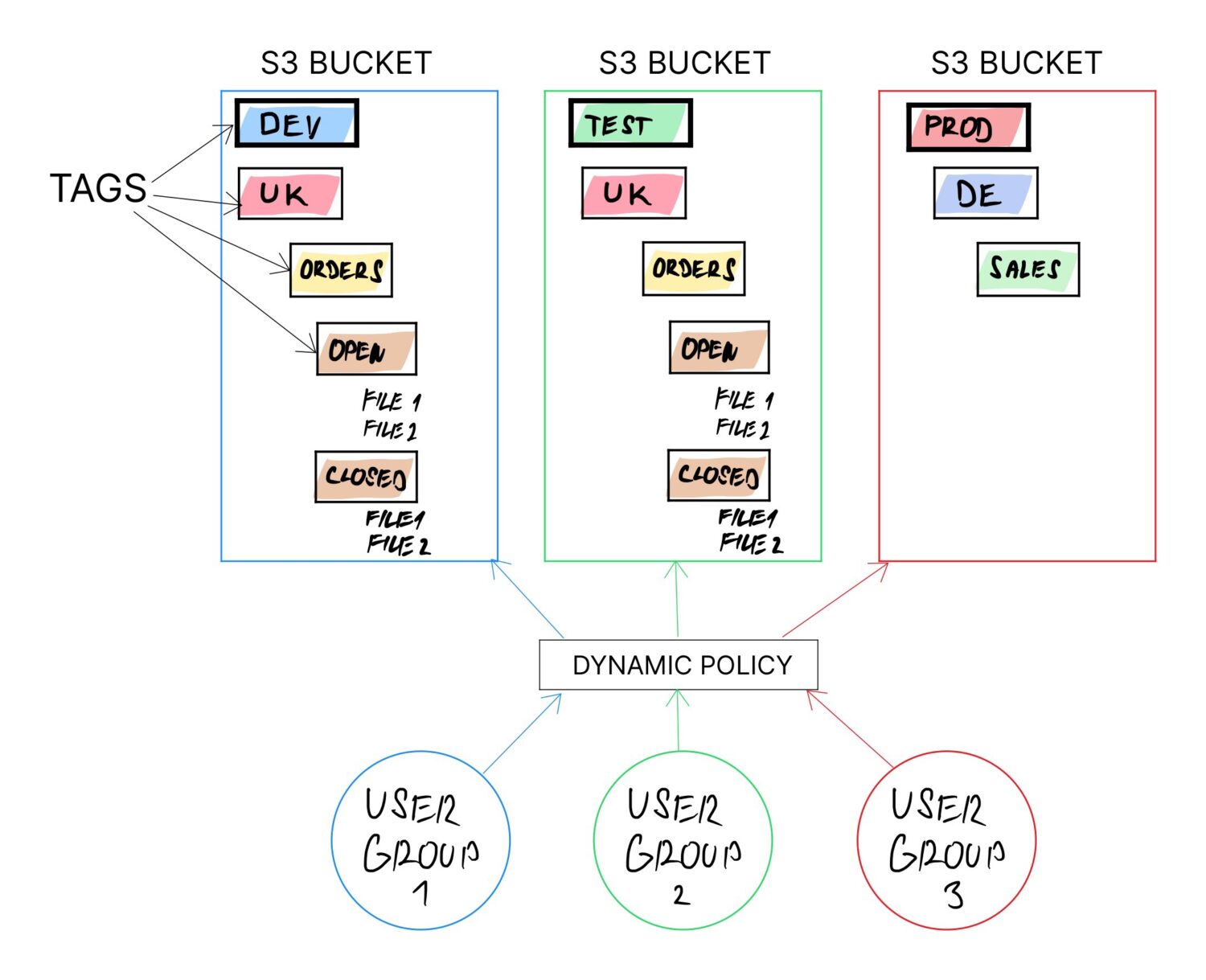
En løsning er å bruke tags på S3-bøttene. Tags anbefales uansett (om ikke annet for å forenkle fakturering). Tag-verdier kan endres for en bøtte når som helst.
Ved å bygge all logikk basert på bøtte-tags, med konfigurasjon avhengig av tag-verdiene, sikres dynamikken, siden formålet med bøtten kan omdefineres ved å endre tag-verdien.
Hvilke tagger bør brukes?
Dette avhenger av ditt spesifikke behov. For eksempel:
- Man kan skille bøtter per miljøtype. Da kan en tag være «ENV» med verdier som «DEV», «TEST» eller «PROD».
- Man kan skille team basert på land, med en «COUNTRY»-tag og tilhørende landnavn.
- Eller man kan skille brukerne etter funksjonsområde, som forretningsanalytikere, datalagerbrukere eller dataforskere, med en tag som «USER_TYPE».
- Et annet alternativ er å definere en fast mappestruktur som brukergruppene forventes å bruke (for å unngå rot). Dette kan oppnås med tags, for eksempel med arbeidsmapper som «data/import», «data/behandlet» eller «data/feil».
Ideelt sett defineres tags slik at de kan kombineres logisk for å danne en mappestruktur i bøtten.
For eksempel kan følgende tags kombineres for å lage en dedikert mappestruktur for ulike brukertyper fra ulike land med forhåndsdefinerte importmapper:
- /
/ / /
Ved å endre
Dette gjør det mulig å bruke samme bøtte for flere brukere. Bøtter støtter ikke mapper eksplisitt, men de støtter «etiketter». Disse etikettene fungerer som undermapper, da brukerne må navigere gjennom dem for å nå dataene sine.
Etter å ha definert tags, er neste steg å bygge S3-bøttepolicyer som bruker disse taggene.
Når policyene bruker tag-navnene, skaper man «dynamiske policyer». Dette betyr at policyen vil oppføre seg forskjellig basert på bøttenes tag-verdier.
Dette trinnet krever tilpasset koding, men AWS Policy Editor kan forenkle prosessen.
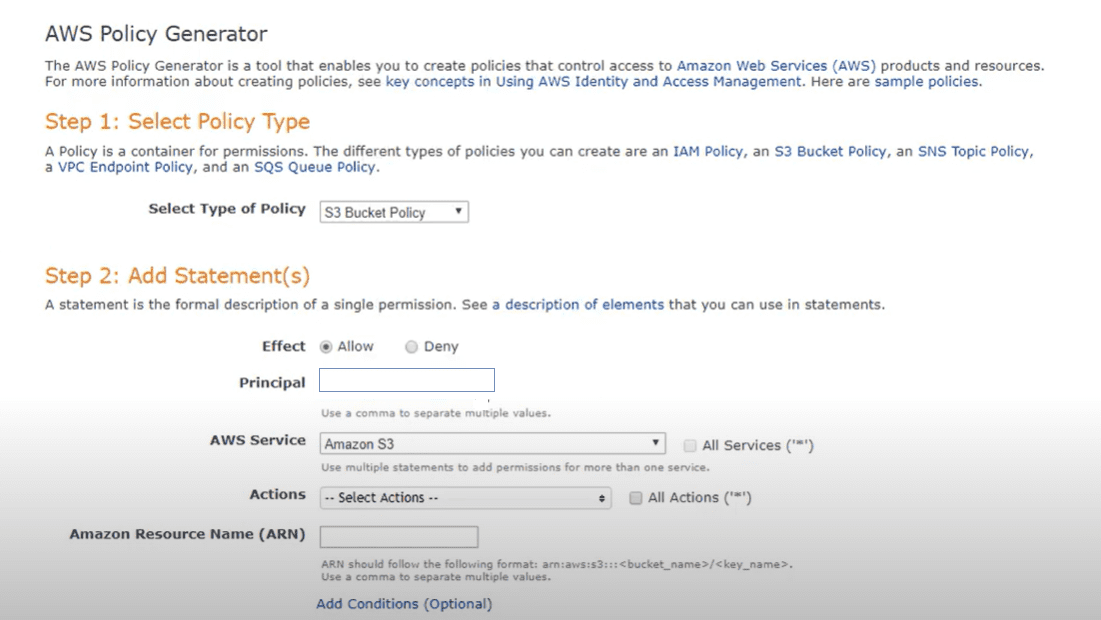
I policyen kodes tilgangsrettighetene for bøtten, og tilgangsnivået (lese, skrive). Logikken leser taggene på bøttene og bygger mappestrukturen (oppretter etiketter basert på taggene). Undermapper og nødvendige tilgangsrettigheter tildeles basert på tag-verdiene.
Fordelen med en dynamisk policy er at man kan lage én policy og tilordne den til mange ulike verdier. Policyen vil oppføre seg ulikt for bøtter med ulike tag-verdier, men vil alltid være i tråd med forventningene til en bøtte med de tag-verdiene.
Dette er en effektiv måte å administrere tilgangsrettigheter sentralt for mange bøtter, der det forventes at hver bøtte følger en malstruktur som er avtalt på forhånd og som skal brukes av organisasjonens brukere.
Automatiser innføringen av nye enheter
Når de dynamiske policyene er definert og tilordnet bøttene, kan brukerne starte å benytte dem uten frykt for at brukere fra andre grupper får tilgang til innhold de ikke skal ha tilgang til (selv om det er lagret i samme bøtte, men under en begrenset mappestruktur).
For brukere med bredere tilgang blir det også lettere å finne data, da alt er lagret i samme bøtte.
Det siste steget er å forenkle introduksjonen av nye brukere, bøtter og tags. Dette krever tilpasset kode, men det behøver ikke være komplisert, forutsatt at introduksjonsprosessen har klare regler som kan innkapsles i en algoritme (dette beviser at prosessen har en logikk og ikke er helt kaotisk).
Dette kan være så enkelt som et skript som kjøres med AWS CLI-kommandoer og parametre. Det kan også være en sekvens av CLI-skript, for eksempel:
- create_new_bucket(
, , , , ..) - create_new_tag(
, , ) - update_existing_tag(
, , ) - create_user_group(
, , ) - etc.
Du forstår poenget. 😃
Et pro-tips 👨💻
Her er et tips som kan legges til den nevnte prosessen.
De dynamiske policyene kan ikke bare brukes til å tildele tilgangsrettigheter for mapper, men også for å tildele tjenesterettigheter automatisk for bøtter og brukergrupper!
Det eneste som kreves er å utvide tag-listen for bøttene, og deretter legge til dynamiske policytilgangsrettigheter for å bruke spesifikke tjenester for konkrete brukergrupper.
For eksempel kan en brukergruppe trenge tilgang til en spesifikk databaseklynge. Dette kan oppnås med dynamiske policyer som bruker bøtte-tags, spesielt hvis tilgang styres av roller. Bare legg til en del av den dynamiske policyen som behandler tags for databaseklyngespesifikasjonen og tildeler policytilgangsrettighetene direkte til DB-klyngen og brukergruppen.
På denne måten styres introduksjonen av en ny brukergruppe av kun én dynamisk policy. Siden den er dynamisk, kan den samme policyen gjenbrukes for mange forskjellige brukergrupper (som følger samme mal, men kanskje ikke de samme tjenestene).
Du kan også se på disse AWS S3-kommandoene for å administrere bøtter og data.