Aggregeringsrørledningen representerer den foretrukne metoden for å utføre avanserte søk i MongoDB. Hvis du tidligere har benyttet deg av MongoDBs MapReduce-funksjonalitet, vil et skifte til aggregeringsrørledningen resultere i mer effektive beregninger.
Hva er aggregering i MongoDB og hvordan fungerer det?
Aggregeringsrørledningen er en fler-trinns prosess designet for å utføre avanserte spørringer i MongoDB. Den behandler informasjon gjennom flere faser, referert til som en rørledning. Resultatene som genereres fra en fase kan brukes som operasjonsmal i den neste.
For eksempel kan du videresende resultatet av en match-operasjon til et sorteringstrinn for å justere rekkefølgen, helt til du oppnår den ønskede utgangen.
Hvert trinn i en aggregeringsrørledning benytter en MongoDB-operator og produserer ett eller flere modifiserte dokumenter. Avhengig av søket, kan et trinn forekomme flere ganger i rørledningen. Det kan for eksempel være nødvendig å anvende $count- eller $sort-operatorene flere ganger gjennom aggregeringsrørledningen.
Stadiene i aggregeringsrørledningen
Aggregeringsrørledningen sender data gjennom en rekke stadier i et enkelt søk. Det finnes flere stadier, og du kan finne mer informasjon om dem i MongoDB-dokumentasjonen.
La oss se på noen av de mest brukte stadiene nedenfor.
$match-stadiet
Dette stadiet lar deg definere spesifikke betingelser for filtrering før de andre aggregeringsstadiene begynner. Du kan bruke det for å velge ut data som samsvarer med dine kriterier, som du vil inkludere i aggregeringsrørledningen.
$gruppestadiet
Gruppestadiet organiserer data i ulike grupper basert på bestemte kriterier ved hjelp av nøkkelverdi-par. Hver gruppe representerer en unik nøkkel i det resulterende dokumentet.
Ta for eksempel følgende salgsdata:
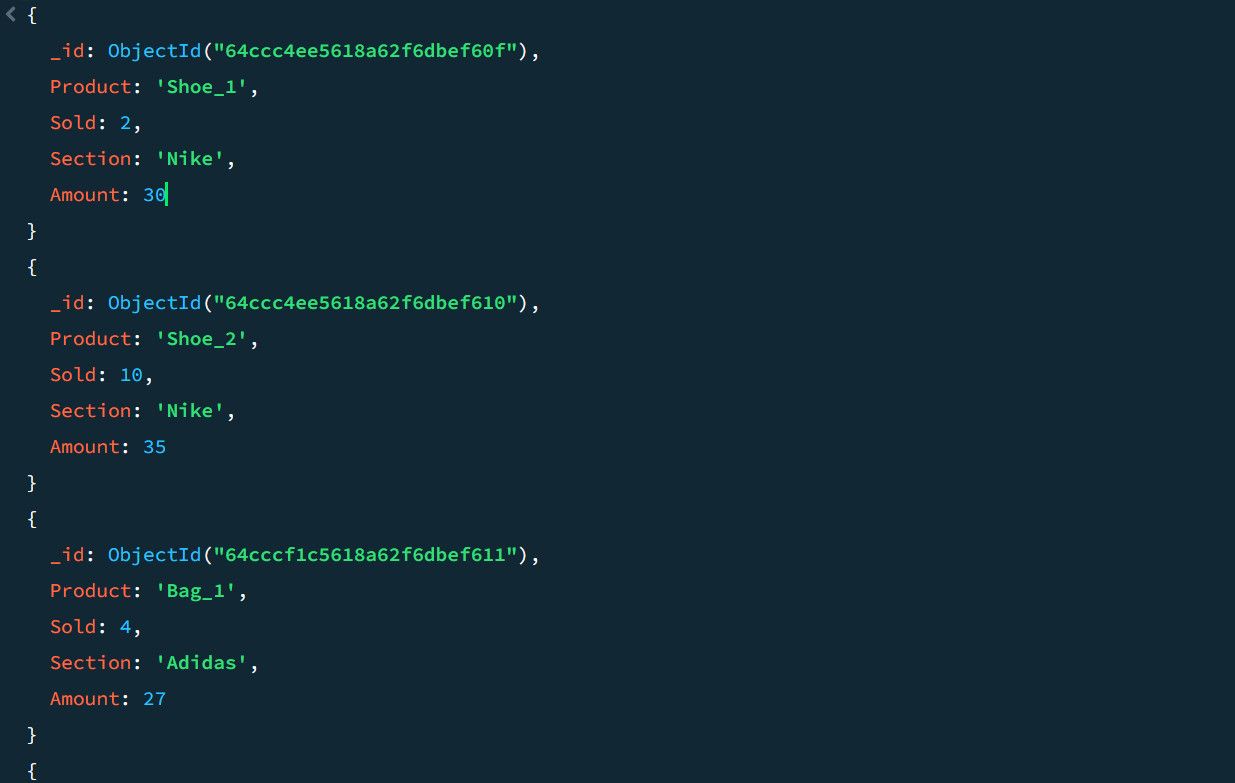
Ved å bruke aggregeringsrørledningen kan du beregne det totale antallet salg og det høyeste salget for hver produktseksjon:
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
_id: $Section-paret grupperer utdatadokumentet basert på seksjonene. Ved å definere feltene top_sales_count og top_sales, lager MongoDB nye nøkler basert på operasjonen som er definert av aggregatoren; dette kan være $sum, $min, $max eller $avg.
$hopp-stadiet
Du kan bruke $hopp-stadiet til å hoppe over et bestemt antall dokumenter i utdataene. Det kommer vanligvis etter gruppestadiet. Hvis du for eksempel forventer to dokumenter i utdataene, men hopper over ett, vil aggregeringen kun vise det andre dokumentet.
For å legge til et hoppstadium, inkludér $skip-operasjonen i aggregeringsrørledningen:
...,
{
$skip: 1
},
$sort-stadiet
Sorteringsstadiet lar deg ordne data i stigende eller synkende rekkefølge. Vi kan for eksempel sortere dataene fra det forrige søkeeksemplet i synkende rekkefølge for å finne ut hvilken seksjon som har det høyeste salget.
Legg til $sort-operatoren i den forrige søkingen:
...,
{
$sort: {top_sales: -1}
},
$limit-stadiet
Begrensningsoperasjonen hjelper deg med å redusere antallet dokumenter som aggregeringsrørledningen skal vise. For eksempel kan du bruke $limit-operatoren for å få seksjonen med høyest salg returnert fra det forrige stadiet:
...,
{
$sort: {top_sales: -1}
},
{"$limit": 1}
Ovennevnte returnerer kun det første dokumentet, som er seksjonen med høyest salg, siden den er øverst i den sorterte listen.
$prosjekt-stadiet
$prosjekt-stadiet lar deg forme utdatadokumentet slik du ønsker. Ved å bruke $project-operatoren kan du spesifisere hvilke felter som skal inkluderes i utdataene og tilpasse nøkkelnavn.
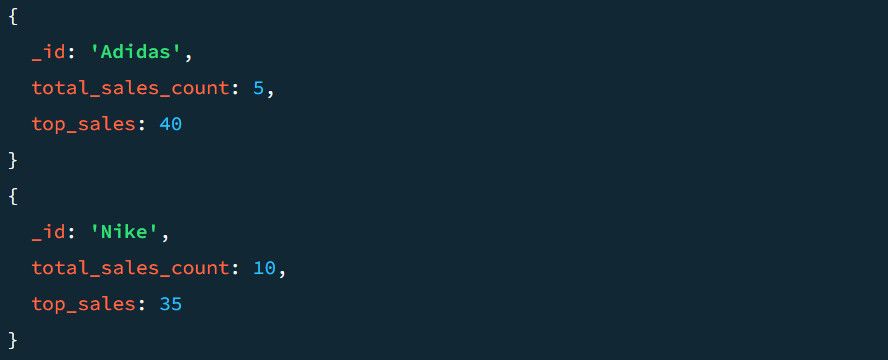
For eksempel ser et utdataeksempel uten $project-stadiet slik ut:
La oss se hvordan det ser ut med $project-stadiet. Slik legger du $project til rørledningen:
...,
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
Siden vi tidligere har gruppert dataene basert på produktseksjoner, inkluderer det ovenstående hver produktseksjon i utdatadokumentet. Det sikrer også at det aggregerte salgsantallet og toppsalget vises i utdataene som TotalSold og TopSale.
Det endelige resultatet er mye renere sammenlignet med det forrige:

$unwind-stadiet
$unwind-stadiet bryter ned en matrise i et dokument til individuelle dokumenter. Ta for eksempel følgende ordredata:
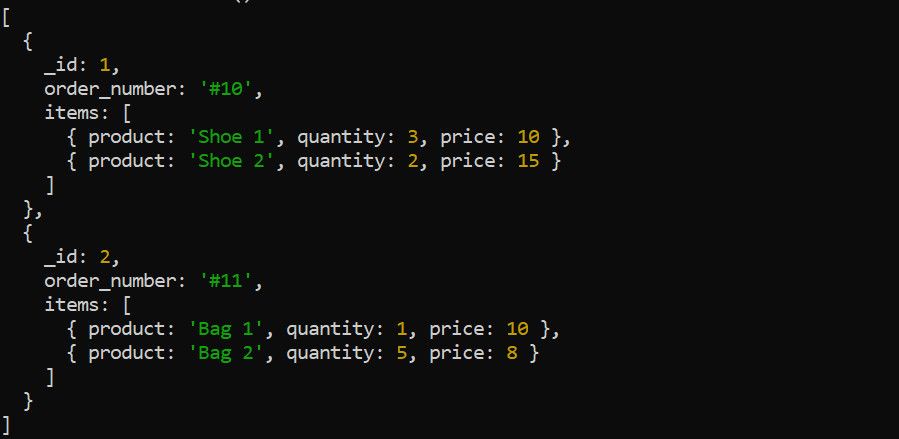
Bruk $unwind-stadiet for å dekonstruere elementarrayen før du bruker andre aggregeringsstadier. For eksempel er det nyttig å «unwinde» varesamlingen hvis du vil beregne den totale inntekten for hvert produkt:
db.Orders.aggregate([
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},
{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",
}
}
])
Her er resultatet av aggregeringssøket ovenfor:

Hvordan lage en aggregeringsrørledning i MongoDB
Selv om aggregeringsrørledningen inkluderer flere operasjoner, gir de tidligere nevnte stadiene en ide om hvordan du bruker dem i rørledningen, inkludert de grunnleggende søkeuttrykkene for hver.
Ved å bruke det forrige salgseksemplet, la oss samle noen av stadiene som er diskutert ovenfor for en bredere oversikt over aggregeringsrørledningen:
db.sales.aggregate([
{
"$match": {
"Sold": { "$gte": 5 }
}
},
{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}
},
{
"$sort": { "top_sales": -1 }
},
{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
])
Det endelige resultatet ser ut som noe du har sett tidligere:
Aggregeringsrørledning vs. MapReduce
Inntil den ble avviklet fra MongoDB 5.0, var MapReduce den tradisjonelle måten å samle data i MongoDB på. Selv om MapReduce har bredere bruksområder utenfor MongoDB, er den mindre effektiv enn aggregeringsrørledningen og krever tredjeparts skripting for å skrive «kart» og «reduser» funksjoner separat.
Aggregeringsrørledningen er derimot spesifikk for MongoDB. Men den tilbyr en renere og mer effektiv måte å utføre komplekse søk på. I tillegg til enkelhet og skalerbarhet for søk, gjør de omtalte pipeline-trinnene resultatene mer tilpassbare.
Det er mange flere forskjeller mellom aggregeringsrørledningen og MapReduce. Du vil oppdage dem når du bytter fra MapReduce til aggregeringsrørledningen.
Gjør store datasøk effektive i MongoDB
Din søk må være så effektivt som mulig hvis du ønsker å kjøre dyptgående beregninger på kompleks data i MongoDB. Aggregeringsrørledningen er ideell for avanserte søk. I stedet for å manipulere data i separate operasjoner, som ofte reduserer ytelsen, lar aggregering deg pakke dem alle inn i en enkelt ytelsesrørledning og utføre dem én gang.
Mens aggregeringsrørledningen er mer effektiv enn MapReduce, kan du gjøre aggregeringen raskere og mer effektiv ved å indeksere dataene dine. Dette begrenser datamengden MongoDB trenger å skanne under hvert aggregeringstrinn.