I dagens datadrevne tidsalder har den gamle metoden for manuell datainnsamling blitt overflødig. Med datamaskiner og internett på alle kontorer, har nettet utviklet seg til en enorm kilde for informasjon. Derfor er moderne metoder for datainnsamling, som web scraping, både mer effektive og tidsbesparende. Når det gjelder web scraping, tilbyr Python et kraftfullt verktøy kalt Beautiful Soup. I denne artikkelen skal vi se på installasjonsprosessen for Beautiful Soup, slik at du kan begynne med web scraping.
Før vi starter installasjonen og arbeidet med Beautiful Soup, la oss først utforske fordelene ved å velge dette verktøyet.
Hva er Beautiful Soup?
Tenk deg at du forsker på «COVIDs innvirkning på folks helse» og har funnet flere nettsider med relevante data. Men hva om disse sidene ikke tilbyr en enkel nedlastingsfunksjon for å få tak i informasjonen? Det er her Beautiful Soup kommer inn i bildet.
Beautiful Soup er et av de mest populære Python-bibliotekene for å hente ut data fra spesifikke nettsider. Det er spesielt nyttig for å hente data fra HTML- eller XML-dokumenter.
Leonard Richardson introduserte Beautiful Soup for web scraping i 2004, og han fortsetter å bidra til prosjektet den dag i dag. Han annonserer stolt hver nye utgivelse av Beautiful Soup på sin Twitter-konto.
Selv om Beautiful Soup for web scraping ble utviklet med Python 3.8, fungerer det utmerket med både Python 3 og Python 2.4.
Ofte bruker nettsider captcha-beskyttelse for å hindre automatiske verktøy i å samle dataene deres. I slike tilfeller kan mindre justeringer i «user-agent»-headeren i Beautiful Soup, eller bruk av captcha-løsnings-API-er, imitere en ekte nettleser og lure deteksjonsverktøyene.
Hvis du derimot ikke har tid til å lære Beautiful Soup, eller ønsker en rask og enkel løsning for web scraping, bør du vurdere å bruke et web scraping-API. Disse lar deg oppgi en URL og motta de ønskede dataene uten å skrive komplisert kode.
Hvis du allerede er en programmerer, vil du finne Beautiful Soup lett å bruke for web scraping, takket være dens enkle syntaks. Den lar deg navigere på nettsider og trekke ut ønsket data basert på betinget parsing. Samtidig er verktøyet også nybegynnervennlig.
Selv om Beautiful Soup kanskje ikke er det beste valget for avansert scraping, er det ideelt for å hente data fra filer som er skrevet i markup-språk.
En annen fordel med Beautiful Soup er dens klare og detaljerte dokumentasjon.
La oss se på hvordan du enkelt kan installere Beautiful Soup på datamaskinen din.
Hvordan installere Beautiful Soup for web scraping?
Pip, en enkel Python-pakkebehandler som ble utviklet i 2008, er i dag et standardverktøy for utviklere som skal installere Python-biblioteker og avhengigheter.
Pip følger som standard med nyere installasjoner av Python. Hvis du har en nyere versjon av Python installert på systemet ditt, er du klar til å begynne.
Åpne kommandolinjen og skriv følgende pip-kommando for å installere Beautiful Soup:
pip install beautifulsoup4
Du vil se en bekreftelse på skjermen som ligner på denne:
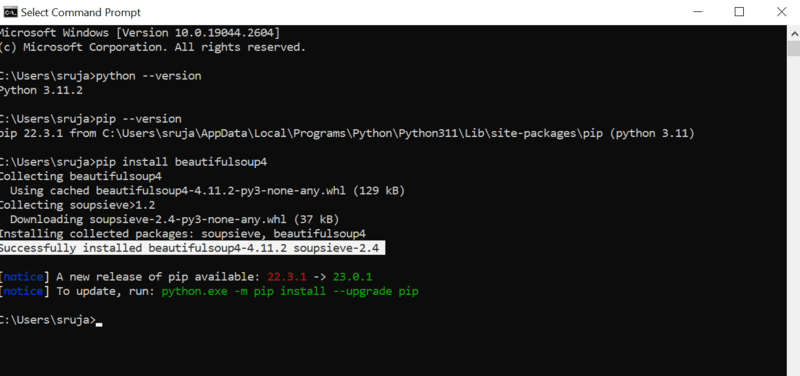
For å unngå potensielle problemer, sørg for at du har oppdatert PIP-installasjonsprogrammet til den nyeste versjonen.
Kommandoen for å oppdatere pip er:
pip install --upgrade pip
Med installasjonen fullført, er vi nå klare til å utforske hvordan du kan bruke Beautiful Soup for web scraping.
Hvordan importere og bruke Beautiful Soup for web scraping?
For å importere Beautiful Soup i ditt nåværende Python-skript, skriver du inn følgende kommando i din Python IDE:
from bs4 import BeautifulSoup
Nå er Beautiful Soup klar til bruk i din Python-fil.
La oss se på et kodeeksempel for å lære hvordan du trekker ut ønsket data med Beautiful Soup.
Vi kan instruere Beautiful Soup om å søke etter spesifikke HTML-tagger på kildenettstedet og skrape dataene som finnes i disse taggene.
I dette eksemplet vil jeg bruke marketwatch.com, som oppdaterer aksjekursene for ulike selskaper i sanntid. Vi skal hente ut noen data fra denne nettsiden for å demonstrere bruken av Beautiful Soup.
Først må vi importere «requests»-pakken, som lar oss motta og svare på HTTP-forespørsler, og «urllib» for å laste nettsiden fra URL-en.
from urllib.request import urlopen import requests
Lagre nettsidekoblingen i en variabel for enkel tilgang senere:
url="https://www.marketwatch.com/investing/stock/amzn"
Deretter bruker vi «urlopen»-metoden fra «urllib»-biblioteket for å laste HTML-siden inn i en variabel. Send URL-en til «urlopen»-funksjonen og lagre resultatet i en variabel:
page = urlopen(url)
Lag et Beautiful Soup-objekt og analyser den ønskede nettsiden ved å bruke «html.parser».
soup_obj = BeautifulSoup(page, 'html.parser')
Nå er hele HTML-skriptet for den valgte nettsiden lagret i variabelen «soup_obj».
Før vi fortsetter, la oss se på kildekoden for den valgte siden for å lære mer om HTML-skriptet og taggene.
Høyreklikk hvor som helst på nettsiden og velg alternativet «Inspiser» for å se kildekoden:
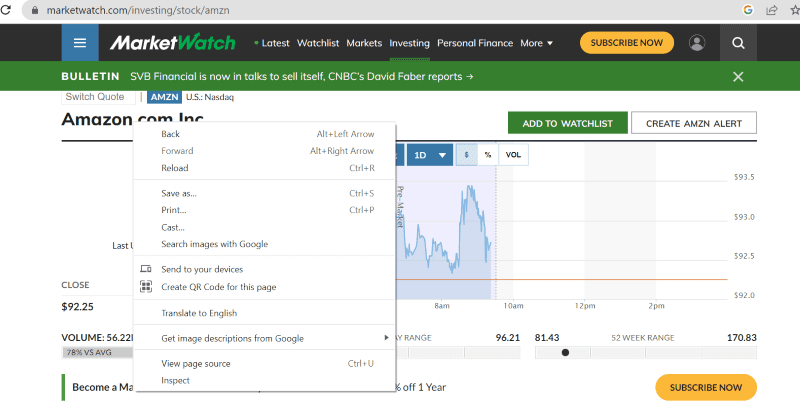
Klikk på «Inspiser» for å se kildekoden.
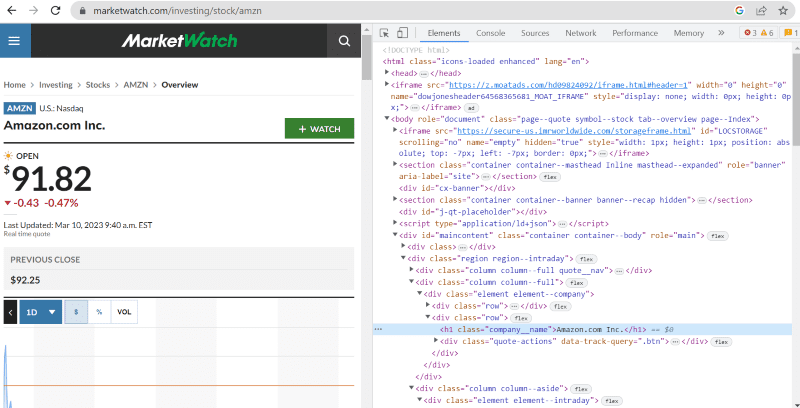
I kildekoden finner du tagger, klasser og annen spesifikk informasjon om hvert element som er synlig på nettsidens grensesnitt.
«Finn»-metoden i Beautiful Soup lar oss søke etter de angitte HTML-taggene og hente ut dataene. For å gjøre dette gir vi klassenavnet og taggene til metoden som skal trekke ut den spesifikke informasjonen.
For eksempel har «Amazon.com Inc.» som vises på nettsiden, klassenavnet: «company__name» under taggen «h1». Vi kan bruke denne informasjonen i «finn»-metoden for å hente ut den relevante HTML-koden til en variabel:
name = soup_obj.find('h1', attrs={'class': 'company__name'})
La oss skrive ut HTML-skriptet som er lagret i variabelen «name» og deretter den rene teksten på skjermen:
print(name) print(name.text)

Du kan se den uthentede dataen skrevet ut på skjermen.
Web scraping fra IMDb-nettstedet
Mange av oss sjekker filmvurderinger på IMDb før vi ser en film. Dette eksemplet vil gi deg en liste over de best rangerte filmene og hjelpe deg å bli kjent med Beautiful Soup for web scraping.
Trinn 1: Importer Beautiful Soup og forespørselsbibliotekene.
from bs4 import BeautifulSoup import requests
Trinn 2: La oss tilordne URL-en vi vil skrape til en variabel kalt «url» for enkel tilgang i koden.
«Requests»-pakken brukes til å hente HTML-siden fra URL-en.
url = requests.get('https://www.imdb.com/search/title/?count=100&groups=top_1000&sort=user_rating')
Trinn 3: I den følgende kodebiten analyserer vi HTML-siden til gjeldende URL for å lage et Beautiful Soup-objekt.
soup_obj = BeautifulSoup(url.text, 'html.parser')
Variabelen «soup_obj» inneholder nå hele HTML-skriptet for den ønskede nettsiden, som i bildet nedenfor.
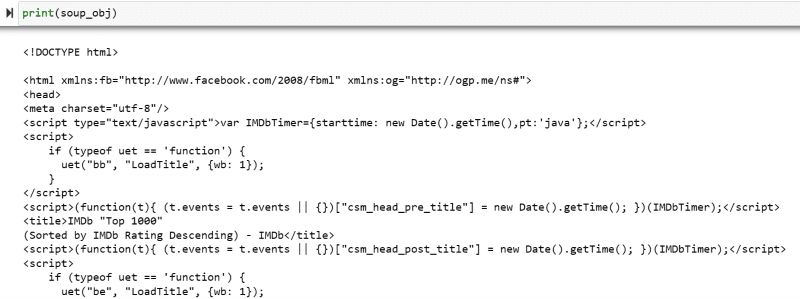
La oss inspisere kildekoden til nettsiden for å finne HTML-skriptet til dataene vi vil skrape.
Hold markøren over elementet du vil trekke ut. Høyreklikk på elementet og velg «Inspiser» for å se kildekoden for det spesifikke elementet. Bildene nedenfor vil veilede deg bedre:
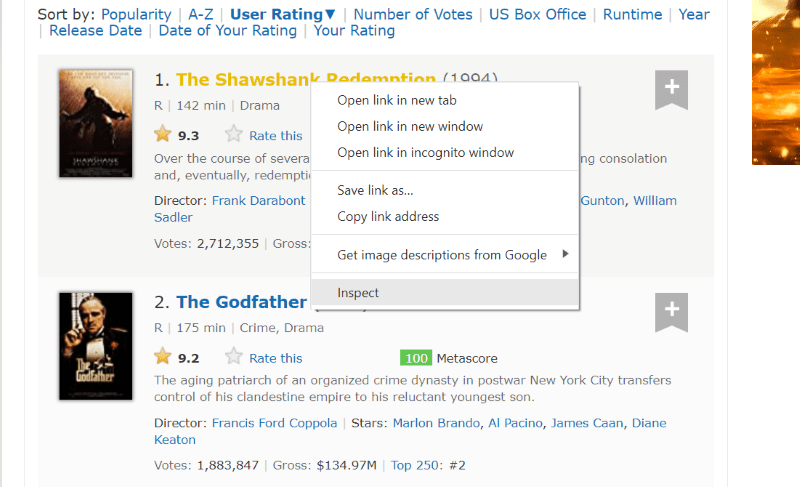
Listen med klassen «lister-list» inneholder alle de topprangerte filmrelaterte dataene, som underavdelinger i påfølgende div-tagger.
I hvert filmkorts HTML-skript, under klassen «lister-item mode-advanced», har vi en tag «h3» som inneholder filmens navn, rangering og utgivelsesår, som vist på bildet nedenfor.
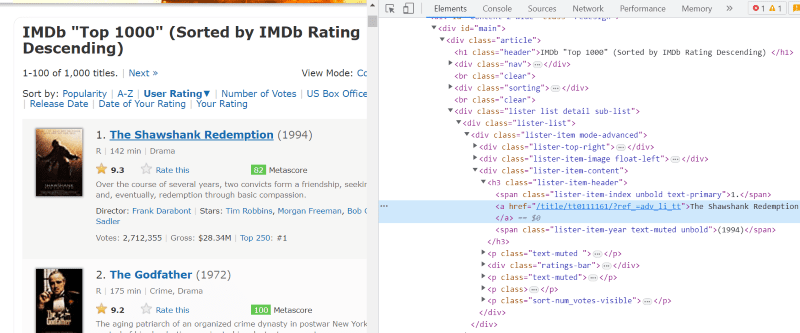
Merk: «Finn»-metoden i Beautiful Soup søker etter den første taggen som samsvarer med input. I motsetning til «finn», søker «finn_alle»-metoden etter alle taggene som samsvarer med den gitte input.
Trinn 4: Du kan bruke metodene «finn» og «finn_alle» for å lagre HTML-skriptet for hvert films navn, rangering og år i en listevariabel.
top_movies = soup_obj.find('div',attrs={'class': 'lister-list'}).find_all('h3')
Trinn 5: Gå gjennom listen over filmer som er lagret i variabelen «top_movies» og trekk ut navnet, rangeringen og året for hver film i tekstformat fra HTML-skriptet ved hjelp av koden nedenfor:
for movie in top_movies:
movi_name = movie.a.text
rank = movie.span.text.rstrip('.')
year = movie.find('span', attrs={'class': 'lister-item-year text-muted unbold'})
year = year.text.strip('()')
print(movi_name + " ", rank+ " ", year+ " ")
I utdata-skjermbildet kan du se listen over filmer med navn, rangering og utgivelsesår.
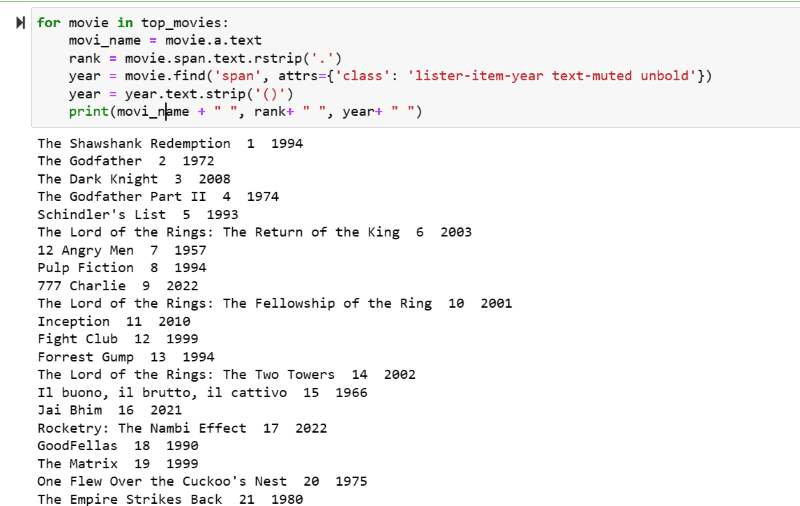
Du kan enkelt flytte de utskrevne dataene til et Excel-ark med litt Python-kode og bruke det til analysen din.
Avsluttende ord
Denne artikkelen har guidet deg gjennom installasjon av Beautiful Soup for web scraping. Eksemplene i artikkelen bør gi deg et godt grunnlag for å begynne med Beautiful Soup.
Siden du er interessert i hvordan du installerer Beautiful Soup for web scraping, anbefaler jeg at du ser nærmere på denne omfattende veiledningen for å lære mer om web scraping med Python.