Opprett din egen AI-chatbot med tilpasset kunnskapsbase
I vår tidligere artikkel utforsket vi hvordan man bygger en AI-chatbot ved hjelp av ChatGPT API og tilpasser den med en spesifikk rolle. Men hva om du ønsker å trene AI-en din på dine egne data? Kanskje du har en bok, finansielle data eller omfattende databaser som du vil kunne søke i raskt og enkelt. Denne artikkelen gir deg en detaljert veiledning om hvordan du kan trene en AI-chatbot ved å bruke din egen kunnskapsbase, ved hjelp av LangChain og ChatGPT API. Vi bruker LangChain, GPT Index og andre kraftige verktøy for å trene AI-chatboten ved hjelp av OpenAIs store språkmodell (LLM). La oss se nærmere på hvordan du kan trene og utvikle din egen AI-chatbot ved hjelp av dine egne data.
Trinnvis veiledning for å trene en AI-chatbot
I denne artikkelen presenterer vi en grundig og trinnvis forklaring på hvordan du kan lære en AI-chatbot å forstå dine egne data. Vi dekker alt fra oppsett av nødvendige verktøy og programvare til selve trening av AI-modellen. Det er viktig å følge instruksjonene i rekkefølge, uten å hoppe over noen deler.
Viktige hensyn før du begynner
1. Denne opplæringen fungerer på alle de vanlige plattformene, inkludert Windows, macOS, Linux og ChromeOS. Selv om vi bruker Windows 11 i dette eksemplet, er trinnene tilnærmet like på de andre operativsystemene.
2. Denne veiledningen er rettet mot vanlige brukere. Instruksjonene er forklart på en lettfattelig måte, slik at du kan trene og bygge en Q&A AI-chatbot selv om du har begrenset datakunnskap eller ikke kan kode. Hvis du har lest vår forrige artikkel om ChatGPT-boter, vil du finne denne prosessen enda lettere å forstå.
3. For å trene en AI-chatbot basert på dine egne data, anbefales det å bruke en datamaskin med en god prosessor (CPU) og grafikkort (GPU). Du kan imidlertid bruke en hvilken som helst moderne datamaskin til testing. Vi testet med en Chromebook og en bok på 100 sider (~100 MB) uten problemer. Men hvis du har planer om å trene AI-en med tusenvis av sider, er det en fordel med en kraftigere maskin.
4. Datasettet bør ideelt sett være på engelsk for best resultat, men ifølge OpenAI fungerer det også med andre store språk, som fransk, spansk og tysk. Du kan derfor eksperimentere med ditt eget språk.
Oppsett av programvaremiljø
Som vi nevnte i vår forrige artikkel, krever dette prosjektet at Python og Pip er installert, samt flere Python-biblioteker. Vi starter fra bunnen av denne gangen, slik at selv nye brukere kan forstå installasjonsprosessen. Vi begynner med å installere Python og Pip, deretter installerer vi Python-biblioteker som inkluderer OpenAI, GPT Index, Gradio og PyPDF2. Underveis vil du lære hva hvert bibliotek gjør. Installasjonsprosessen er enkel, så la oss sette i gang.
Installere Python
1. Først må du laste ned og installere Python (som inkluderer Pip) på datamaskinen din. Gå til denne lenken og last ned installasjonsfilen for ditt operativsystem.
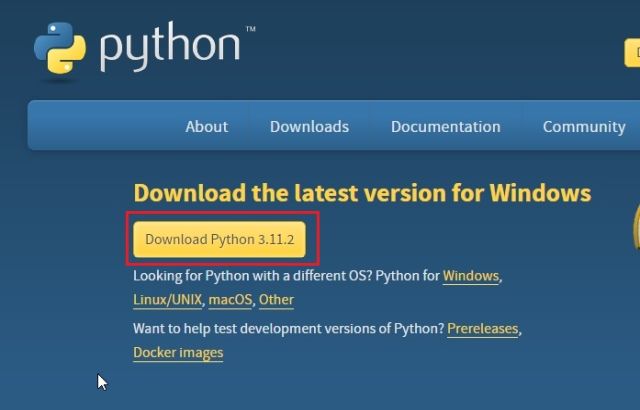
2. Når installasjonsfilen er lastet ned, kjører du den. Pass på å huke av for «Add Python.exe to PATH». Dette er et svært viktig steg. Klikk deretter på «Installer nå» og følg de vanlige trinnene for å fullføre installasjonen.
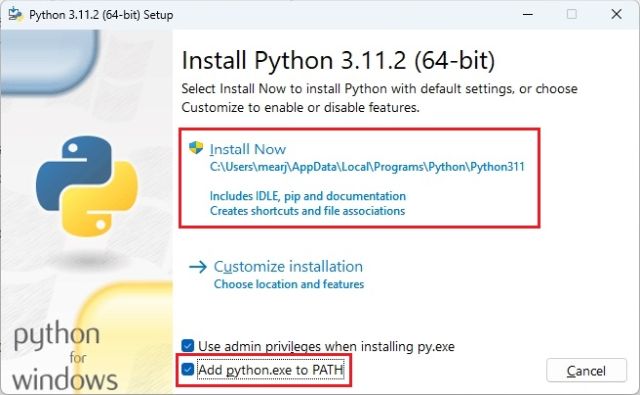
3. For å verifisere at Python er installert riktig, åpne terminalen (eller kommandoprompt) og kjør kommandoen under. Hvis installasjonen er vellykket, vil den vise Python-versjonen. På Linux og macOS må du kanskje bruke kommandoen `python3 –version` i stedet for `python –version`.
python --version
Oppgradere Pip
Når du installerer Python, følger Pip automatisk med. La oss sørge for at du har den nyeste versjonen. Pip er pakkebehandleren for Python, og den lar deg installere tusenvis av Python-biblioteker via terminalen. Vi vil bruke Pip til å installere OpenAI, gpt_index, gradio og PyPDF2 bibliotekene. Her er trinnene du må følge:
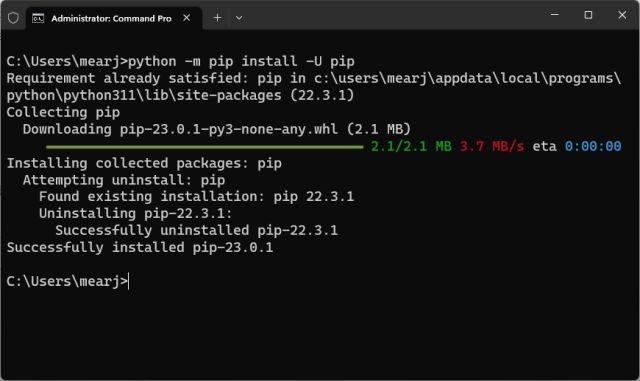
1. Åpne terminalen og kjør kommandoen nedenfor for å oppgradere Pip. På Linux og macOS må du kanskje bruke `python3` og `pip3` i stedet for `python` og `pip`.
python -m pip install -U pip
2. For å sjekke at Pip er installert korrekt, kjør kommandoen under, som vil vise versjonsnummeret. Hvis du får feilmelding, kan du sjekke vår guide om hvordan du installerer Pip på Windows for å løse PATH-relaterte problemer.
pip --version
Installere OpenAI, GPT Index, PyPDF2 og Gradio bibliotekene
Nå som Python og Pip er satt opp, er vi klare til å installere de nødvendige bibliotekene for å trene AI-chatboten. Her er trinnene:
1. Åpne terminalen og kjør kommandoen under for å installere OpenAI-biblioteket. Dette brukes som en stor språkmodell (LLM) for å trene og bygge AI-chatboten, og vi importerer LangChain-rammeverket fra OpenAI. På Linux og macOS må du kanskje bruke `pip3` i stedet for `pip`.
pip install openai
2. La oss installere GPT Index (også kjent som LlamaIndex), som kobler LLM-en til våre eksterne data.
pip install gpt_index
3. Installer deretter PyPDF2 for å analysere PDF-filer. Dette biblioteket hjelper programmet med å lese PDF-dokumenter.
pip install PyPDF2
4. Til slutt, installer Gradio-biblioteket, som lar oss lage et enkelt brukergrensesnitt for å samhandle med AI-chatboten. Nå er vi ferdig med å installere alle de nødvendige bibliotekene for å trene en AI-chatbot.
pip install gradio
Laste ned en kodeeditor
For å redigere koden trenger du en kodeeditor. For Windows anbefales Notepad++ (last ned). Du kan også bruke VS Code, som fungerer på alle plattformer, hvis du foretrekker et kraftigere utviklingsmiljø. Andre alternativer er Sublime Text (last ned) for macOS og Linux, og Caret-appen (last ned) for ChromeOS. Vi er nesten klare med oppsettet, nå mangler bare OpenAI API-nøkkelen.
Skaffe OpenAI API-nøkkel gratis
For å kunne trene AI-chatboten med din egen kunnskapsbase, må du skaffe en API-nøkkel fra OpenAI. API-nøkkelen lar deg bruke OpenAIs modell som en LLM for å behandle dataene dine. OpenAI tilbyr gratis API-nøkler med en kreditt på $5 de første tre månedene. Hvis du allerede har en OpenAI-konto, kan du ha $18 i gratis kreditt. Når den gratis kreditten er brukt opp, må du betale for tilgang til API-et. Foreløpig er den tilgjengelig for alle nye brukere gratis.
1. Gå til platform.openai.com/signup og opprett en gratis konto. Hvis du allerede har en OpenAI-konto, logger du bare inn.
2. Klikk på profilen din øverst til høyre og velg «View API keys» i rullegardinmenyen.
3. Klikk på «Create new secret key» og kopier API-nøkkelen. Vær oppmerksom på at du ikke kan se hele API-nøkkelen senere, så det er viktig å lagre den i en tekstfil umiddelbart.
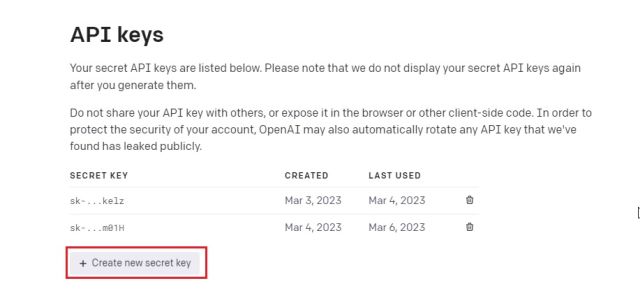
4. Ikke del API-nøkkelen din offentlig. Det er en privat nøkkel for tilgang til din konto. Du kan også slette API-nøkler og opprette nye (opptil fem).
Trening og opprettelse av AI-chatbot med tilpasset kunnskapsbase
Nå som programvaremiljøet er klart og du har din API-nøkkel, kan vi starte treningen av AI-chatboten. Vi bruker modellen «text-davinci-003» i stedet for den nyeste «gpt-3.5-turbo», da Davinci fungerer bedre for tekstkomplettering. Du kan endre til Turbo for å redusere kostnadene. La oss starte med trinnene:
Legge til dokumentene for å trene AI-chatboten
1. Lag en ny mappe med navnet «docs» på et lett tilgjengelig sted, for eksempel skrivebordet. Du kan også velge et annet sted. Det er viktig at du bruker mappenavnet «docs».

2. Flytt dokumentene du vil bruke til trening inn i «docs»-mappen. Du kan legge til flere tekst- og PDF-filer (inkludert skannede). Hvis du har store tabeller i Excel, kan du lagre dem som CSV- eller PDF-filer og legge dem til i mappen. Du kan også bruke SQL-databasefiler, som vist i denne Langchain AI tweet. Vi har ikke testet alle filformater, men du kan eksperimentere selv. Vi bruker en av våre artikler om NFT i PDF-format i dette eksemplet.
Merk: Behandlingstiden avhenger av filstørrelsen og datamaskinens kapasitet. Jo større dokument, desto lengre tid vil det ta, og jo raskere vil din gratis OpenAI-kreditt brukes opp. Det er derfor anbefalt å starte med et mindre dokument (30-50 sider eller <100MB) for å forstå prosessen.
Forberede koden
1. Åpne Notepad++ (eller din foretrukne kodeeditor) og lim inn koden under i en ny fil. Koden er basert på en kode på Google Colab av armrrs, og er justert for å fungere med PDF-filer og lage et Gradio-grensesnitt.
from gpt_index import SimpleDirectoryReader, GPTListIndex, GPTSimpleVectorIndex, LLMPredictor, PromptHelper
from langchain import OpenAI
import gradio as gr
import sys
import os
os.environ["OPENAI_API_KEY"] = 'Your API Key'
def construct_index(directory_path):
max_input_size = 4096
num_outputs = 512
max_chunk_overlap = 20
chunk_size_limit = 600
prompt_helper = PromptHelper(max_input_size, num_outputs, max_chunk_overlap, chunk_size_limit=chunk_size_limit)
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0.7, model_name="text-davinci-003", max_tokens=num_outputs))
documents = SimpleDirectoryReader(directory_path).load_data()
index = GPTSimpleVectorIndex(documents, llm_predictor=llm_predictor, prompt_helper=prompt_helper)
index.save_to_disk('index.json')
return index
def chatbot(input_text):
index = GPTSimpleVectorIndex.load_from_disk('index.json')
response = index.query(input_text, response_mode="compact")
return response.response
iface = gr.Interface(fn=chatbot,
inputs=gr.inputs.Textbox(lines=7, label="Enter your text"),
outputs="text",
title="Custom-trained AI Chatbot")
index = construct_index("docs")
iface.launch(share=True)
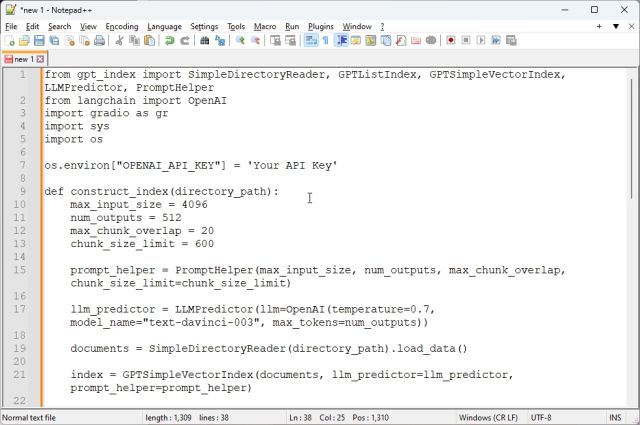
2. Koden skal se omtrent slik ut i kodeeditoren.
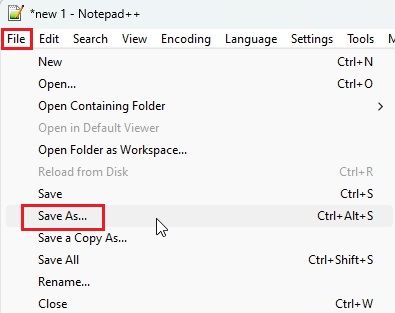
3. Klikk på «File» og velg «Save as» fra rullegardinmenyen.
4. Gi filen navnet `app.py` og endre «Save as type» til «All Types». Lagre filen i samme mappe som «docs»-mappen (skrivebordet i dette tilfellet). Det er viktig at filen får filtypen .py.
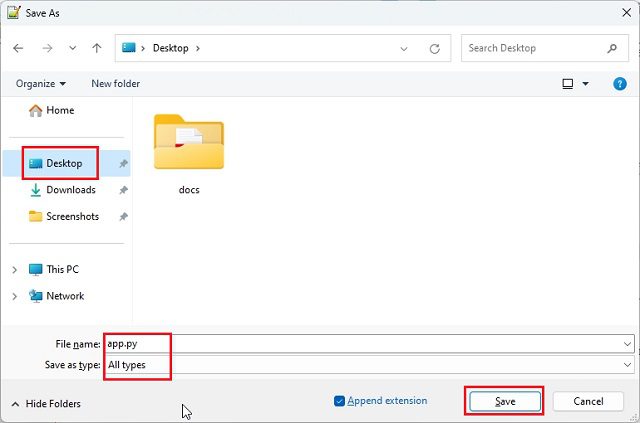
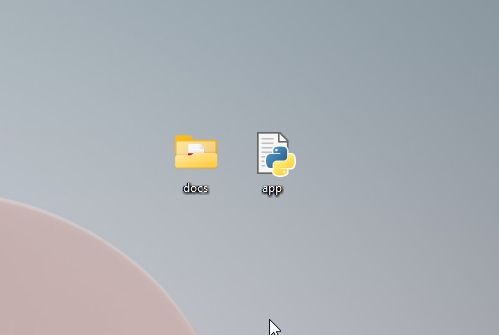
5. Forsikre deg om at «docs»-mappen og `app.py` ligger på samme plassering. `app.py`-filen skal ligge utenfor «docs»-mappen, ikke inne i den.
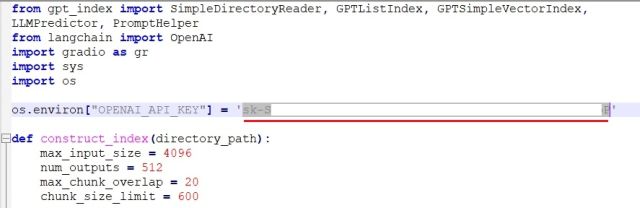
6. Gå tilbake til koden i kodeeditoren. Erstatt `Your API Key` med din faktiske API-nøkkel fra OpenAIs nettside.
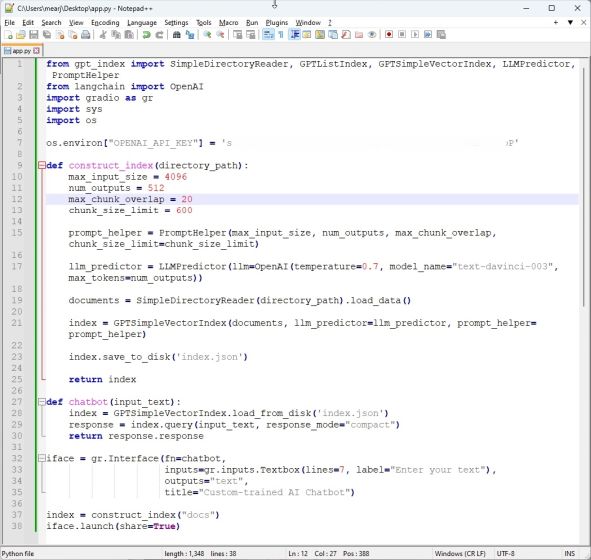
7. Trykk «Ctrl + S» for å lagre koden. Nå er du klar til å kjøre koden.
Lage en ChatGPT AI-bot med tilpasset kunnskapsbase
1. Åpne terminalen og bruk kommandoen `cd Desktop` for å navigere til skrivebordet (eller mappen der du har lagret `docs`-mappen og `app.py`).
cd Desktop
2. Kjør kommandoen under. På Linux og macOS kan du måtte bruke `python3` istedenfor `python`.
python app.py
3. Programmet vil nå begynne å analysere dokumentet ved hjelp av OpenAI LLM, og indeksere informasjonen. Behandlingstiden avhenger av filstørrelsen og datamaskinens ytelse. Når behandlingen er ferdig, vil en «index.json» fil bli opprettet på skrivebordet. Hvis terminalen ikke viser noen output, betyr ikke det at noe er feil, den kan fortsatt behandle dataene. Det tar rundt 10 sekunder å behandle et 30 MB dokument.
4. Når LLM har behandlet dataene, kan du få noen advarsler, som du trygt kan ignorere. Nederst i terminalen vil du finne en lokal URL. Kopier denne.
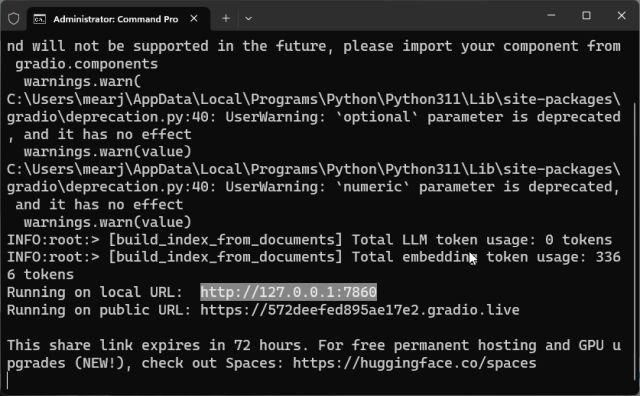
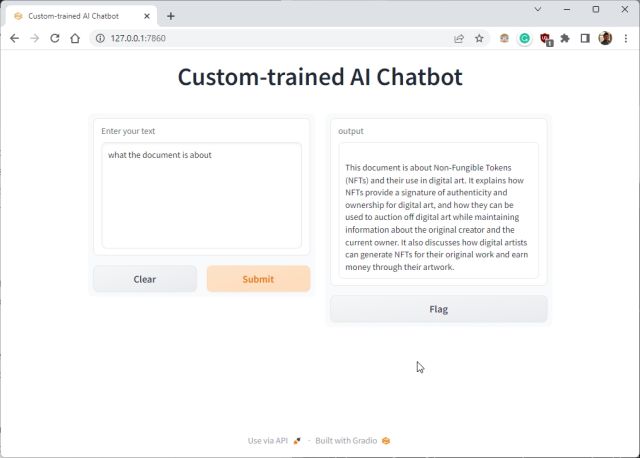
5. Lim den kopierte URL-en inn i nettleseren, og der har du det! Din spesialtrente ChatGPT-drevne AI-chatbot er klar. Du kan starte med å spørre chatboten hva dokumentet handler om.
6. Du kan stille flere spørsmål, og ChatGPT-boten vil svare med informasjon fra de dataene du har matet inn. Dette er hvordan du kan bygge en spesialtrent AI-chatbot med ditt eget datasett. Mulighetene er mange.
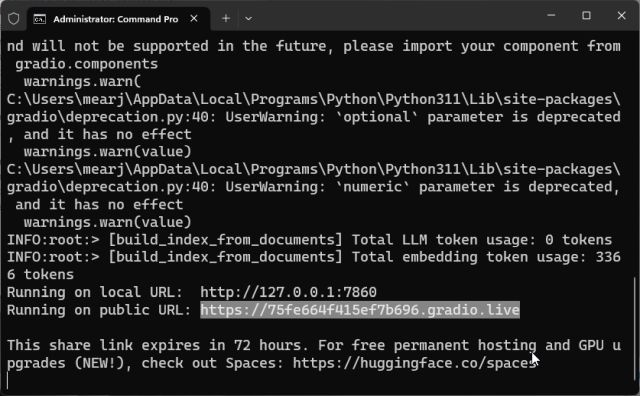
7. Du kan også kopiere den offentlige URL-en og dele den med andre. Denne lenken vil være aktiv i 72 timer, men du må holde datamaskinen på da serveren kjører lokalt.
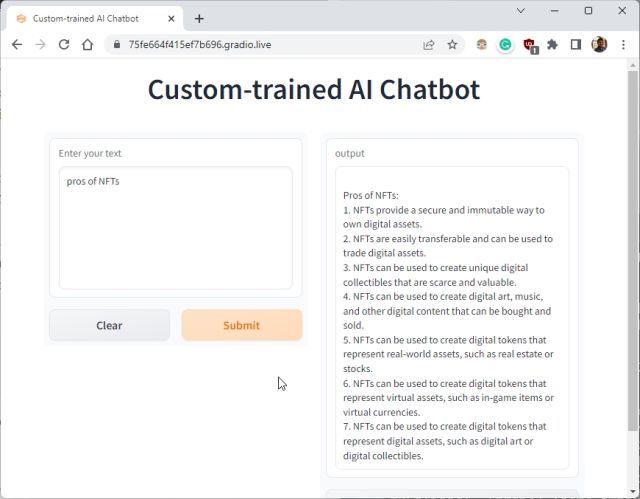
8. For å stoppe AI-chatboten trykker du «Ctrl + C» i terminalen. Hvis det ikke fungerer, prøv igjen.
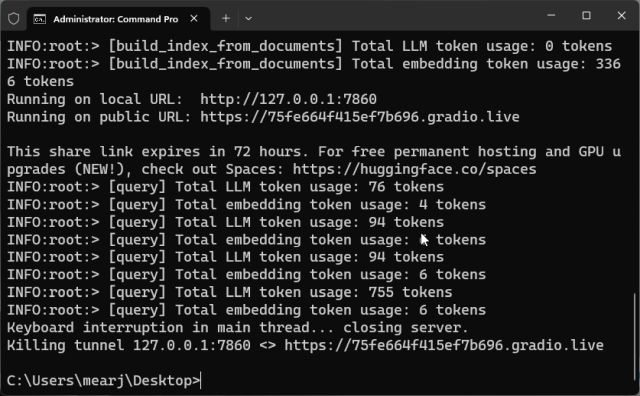
9. For å starte AI-chatboten igjen, naviger til skrivebordet og kjør `python app.py` igjen. Den lokale URL-en vil være den samme, men den offentlige URL-en vil endres hver gang du starter serveren på nytt.
python app.py
10. Hvis du vil trene AI-chatboten med nye data, slett filene i «docs»-mappen og legg til de nye. Det er best å trene boten med data om samme tema.
11. Kjør koden i terminalen på nytt, og den vil opprette en ny «index.json»-fil. Den gamle filen vil bli erstattet automatisk.
python app.py
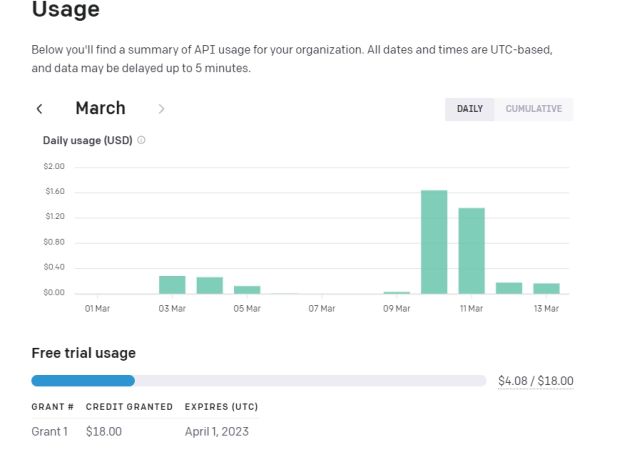
12. For å holde oversikt over tokens brukt, kan du gå til OpenAIs dashbord for å se hvor mye gratis kreditt du har igjen.
13. Du trenger ikke å endre koden, med mindre du vil bytte API-nøkkel eller OpenAI-modell for ytterligere tilpasning.
Lag din egen AI-chatbot med dine egne data
Dette er hvordan du kan trene en AI-chatbot med din egen kunnskapsbase. Vi har brukt denne koden til å trene AI på medisinske bøker, artikler, tabeller og rapporter fra gamle arkiver, med gode resultater. Nå kan du lage din egen AI-chatbot ved hjelp av OpenAIs store språkmodell og ChatGPY. Hvis du ønsker å utforske alternativer til ChatGPT, kan du lese vår andre artikkel. Og for å bruke ChatGPT på Apple Watch, kan du sjekke vår guide. Hvis du har problemer, legg igjen en kommentar nedenfor, så vil vi hjelpe deg så godt vi kan.