

Er du klar til å lære funksjonsteknikk for maskinlæring og datavitenskap? Du er på rett sted!
Funksjonsteknikk er en kritisk ferdighet for å trekke ut verdifull innsikt fra data, og i denne hurtigveiledningen vil jeg dele den opp i enkle, fordøyelige biter. Så la oss dykke rett inn og komme i gang på reisen din for å mestre funksjonsutvinning!
Innholdsfortegnelse
Hva er funksjonsteknikk?

Når du lager en maskinlæringsmodell relatert til et forretnings- eller eksperimentelt problem, leverer du læringsdata i kolonner og rader. I datavitenskap og ML-utviklingsdomenet er kolonner kjent som attributtene eller variablene.
Granulære data eller rader under disse kolonnene er kjent som observasjoner eller forekomster. Kolonnene eller attributtene er funksjonene i et rådatasett.
Disse rå funksjonene er ikke nok eller optimale for å trene en ML-modell. For å redusere støyen fra de innsamlede metadataene og maksimere unike signaler fra funksjoner, må du transformere eller konvertere metadatakolonner til funksjonelle funksjoner gjennom funksjonsutvikling.
Eksempel 1: Finansiell modellering
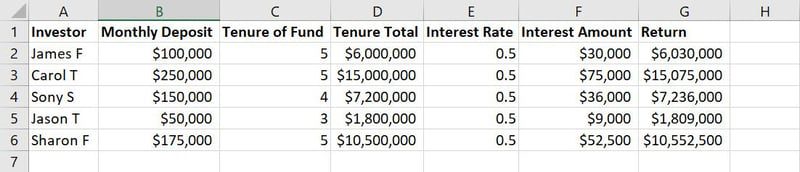 Rådata for opplæring i ML-modell
Rådata for opplæring i ML-modell
For eksempel, i bildet ovenfor av et eksempeldatasett, er kolonnene fra A til G funksjoner. Verdier eller tekststrenger i hver kolonne langs radene, som navn, innskuddsbeløp, innskuddsår, renter osv., er observasjoner.
I ML-modellering må du slette, legge til, kombinere eller transformere data for å skape meningsfulle funksjoner og redusere størrelsen på den generelle modellopplæringsdatabasen. Dette er funksjonsteknikk.
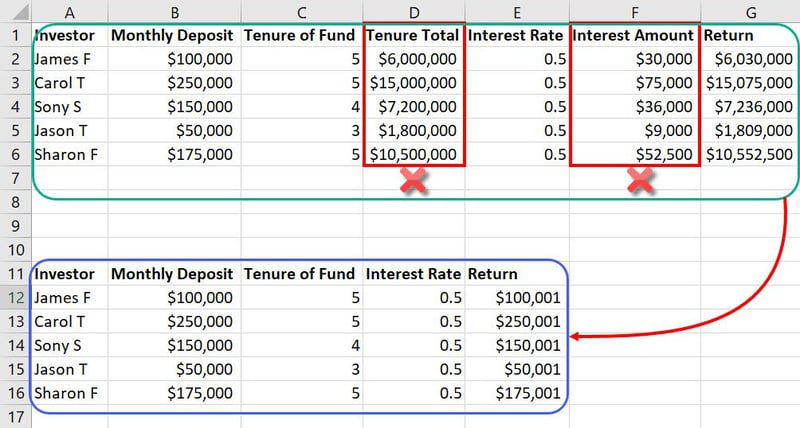 Eksempel på funksjonsteknikk
Eksempel på funksjonsteknikk
I det samme datasettet nevnt tidligere er funksjoner som Tenure Total og Interest Amount unødvendige inndata. Disse vil ganske enkelt ta mer plass og forvirre ML-modellen. Så du kan redusere to funksjoner fra totalt syv funksjoner.
Siden databasene i ML-modeller inneholder tusenvis av kolonner og millioner av rader, vil det å redusere to funksjoner påvirke prosjektet mye.
Eksempel 2: AI Music Playlist Maker
Noen ganger kan du lage en helt ny funksjon av flere eksisterende funksjoner. Anta at du lager en AI-modell som automatisk lager en spilleliste med musikk og sanger i henhold til hendelse, smak, modus osv.
Nå har du samlet inn data om sanger og musikk fra forskjellige kilder og opprettet følgende database:
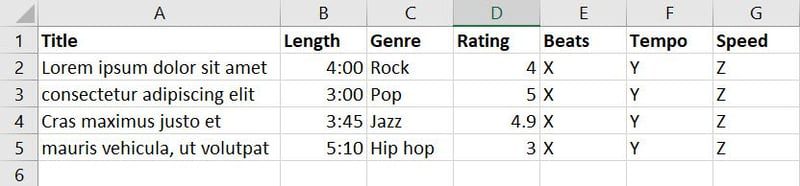
Det er syv funksjoner i databasen ovenfor. Men siden målet ditt er å trene ML-modellen for å avgjøre hvilken sang eller musikk som passer for hvilken begivenhet, kan du slå sammen funksjoner som sjanger, vurdering, beats, tempo og hastighet til en ny funksjon kalt Applicability.
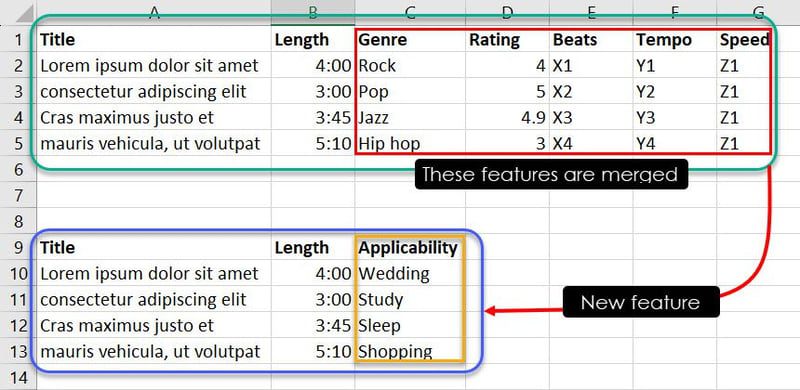
Nå, enten gjennom ekspertise eller mønsteridentifikasjon, kan du kombinere visse forekomster av funksjoner for å finne ut hvilken sang som passer for hvilken begivenhet. Observasjoner som Jazz, 4.9, X3, Y3 og Z1 forteller for eksempel ML-modellen at sangen Cras maximus justo et bør være i brukerens spilleliste hvis de leter etter en sang for søvntid.
Typer funksjoner i maskinlæring
Kategoriske funksjoner
Dette er dataattributter som representerer distinkte kategorier eller etiketter. Du må bruke denne typen for å merke kvalitative datasett.
#1. Ordinale kategoriske trekk
Ordinaltrekk har kategorier med en meningsfull rekkefølge. For eksempel har utdanningsnivåer som videregående skole, bachelor, master, etc. et klart skille i standardene, men det er ingen kvantitative forskjeller.
#2. Nominelle kategoriske egenskaper
Nominelle funksjoner er kategorier uten noen iboende rekkefølge. Eksempler kan være farger, land eller typer dyr. Dessuten er det bare kvalitative forskjeller.
Array-funksjoner
Denne funksjonstypen representerer data organisert i matriser eller lister. Dataforskere og ML-utviklere bruker ofte Array-funksjoner for å håndtere sekvenser eller legge inn kategoriske data.
#1. Innebygging av array-funksjoner
Innebygde matriser konverterer kategoriske data til tette vektorer. Det er ofte brukt i naturlig språkbehandling og anbefalingssystemer.
#2. List Array-funksjoner
Listematriser lagrer sekvenser av data, for eksempel lister over elementer i en ordre eller handlingshistorikk.
Numeriske funksjoner
Disse ML-treningsfunksjonene brukes til å utføre matematiske operasjoner siden disse funksjonene representerer kvantitative data.
#1. Intervall numeriske funksjoner
Intervallfunksjoner har konsistente intervaller mellom verdier, men ingen ekte nullpunkt – for eksempel temperaturovervåkingsdata. Her betyr null frysepunktet, men attributtet er der fortsatt.
#2. Forhold Numeriske funksjoner
Forholdsfunksjoner har konsistente intervaller mellom verdier og et sant nullpunkt. Eksempler inkluderer alder, høyde og inntekt.
Viktigheten av funksjonsteknikk i ML og datavitenskap
Deretter vil vi utforske trinn-for-trinn-prosessen for funksjonsutvikling.
Funksjonsteknikk trinn-for-trinn

Deretter vil vi diskutere funksjonsteknikkmetoder.
Funksjonsteknikker
#1. Hovedkomponentanalyse (PCA)
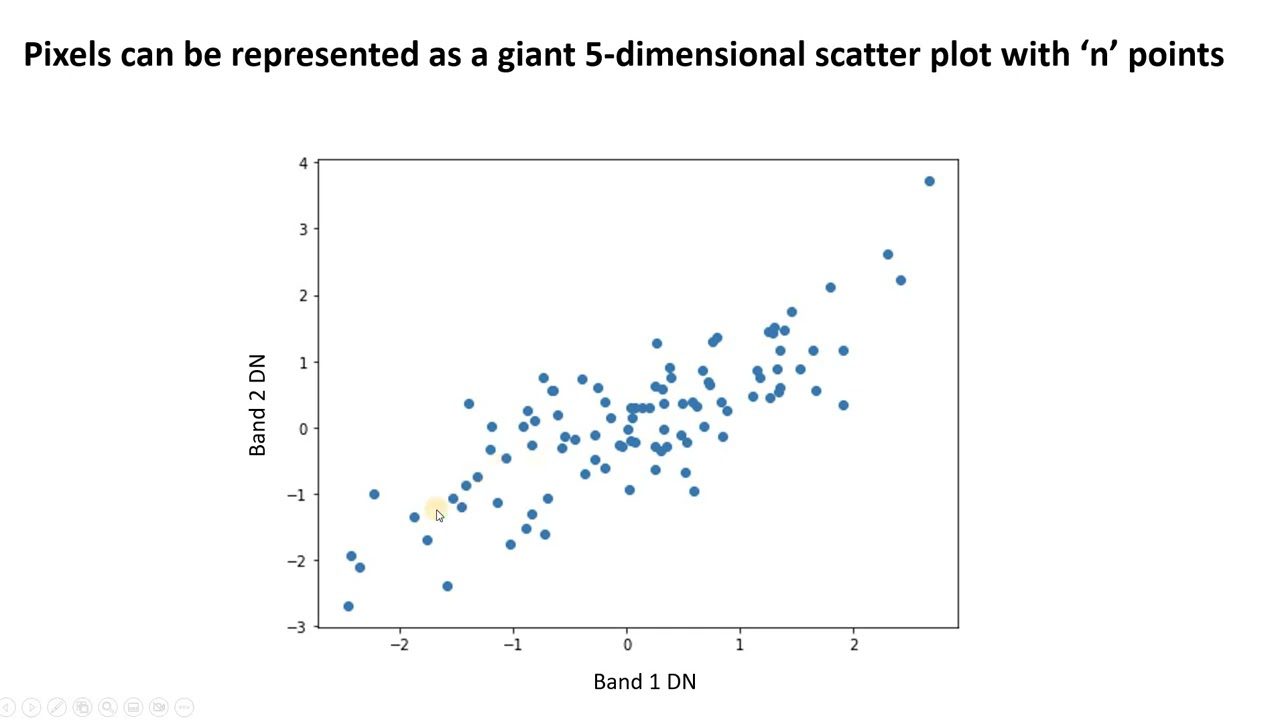
PCA forenkler komplekse data ved å finne nye ukorrelerte funksjoner. Disse kalles hovedkomponenter. Du kan bruke den til å redusere dimensjonalitet og forbedre modellytelsen.
#2. Polynomegenskaper
Å lage polynomiske funksjoner betyr å legge til kraften til eksisterende funksjoner for å fange komplekse relasjoner i dataene dine. Det hjelper modellen din til å forstå ikke-lineære mønstre.
#3. Håndtering av uteliggere
Outliers er uvanlige datapunkter som kan påvirke ytelsen til modellene dine. Du må identifisere og håndtere uteliggere for å forhindre skjeve resultater.
#4. Logg Transform
Logaritmisk transformasjon kan hjelpe deg med å normalisere data med en skjev fordeling. Det reduserer virkningen av ekstreme verdier for å gjøre dataene mer egnet for modellering.
#5. t-Distribuert Stokastisk Neighbor Embedding (t-SNE)
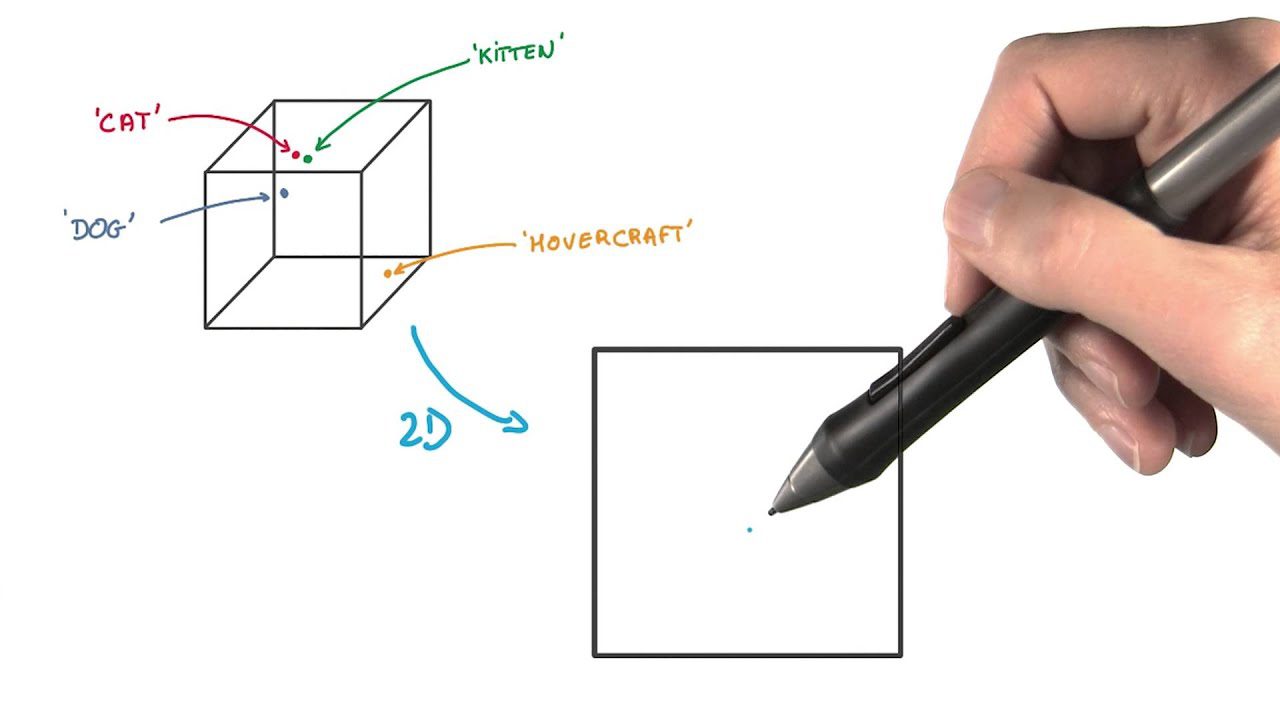
t-SNE er nyttig for å visualisere høydimensjonale data. Det reduserer dimensjonalitet og gjør klynger mer synlige samtidig som datastrukturen bevares.
I denne funksjonsekstraksjonsmetoden representerer du datapunkter som prikker i et lavere dimensjonalt rom. Deretter plasserer du de lignende datapunktene i det opprinnelige høydimensjonale rommet og modelleres til å være nær hverandre i den lavere dimensjonale representasjonen.
Den skiller seg fra andre dimensjonalitetsreduksjonsmetoder ved å bevare strukturen og avstandene mellom datapunkter.
#6. One-Hot-koding
One-hot-koding transformerer kategoriske variabler til binært format (0 eller 1). Så du får nye binære kolonner for hver kategori. One-hot-koding gjør kategoriske data egnet for ML-algoritmer.
#7. Tellekoding
Tellekoding erstatter kategoriske verdier med antall ganger de vises i datasettet. Den kan fange opp verdifull informasjon fra kategoriske variabler.
I denne metoden for funksjonsutvikling bruker du frekvensen eller antallet for hver kategori som en ny numerisk funksjon i stedet for å bruke de originale kategorietikettene.
#8. Funksjonsstandardisering

Kjennetegn ved større verdier dominerer ofte trekk ved små verdier. Dermed kan ML-modellen lett bli partisk. Standardisering forhindrer slike årsaker til skjevheter i en maskinlæringsmodell.
Standardiseringsprosessen involverer vanligvis følgende to vanlige teknikker:
- Z-Score Standardization: Denne metoden transformerer hver funksjon slik at den har et gjennomsnitt (gjennomsnitt) på 0 og et standardavvik på 1. Her trekker du gjennomsnittet av funksjonen fra hvert datapunkt og deler resultatet på standardavviket.
- Min-maks-skalering: Min-maks-skalering transformerer dataene til et spesifikt område, vanligvis mellom 0 og 1. Du kan oppnå dette ved å trekke fra minimumsverdien til funksjonen fra hvert datapunkt og dele på området.
#9. Normalisering
Gjennom normalisering skaleres numeriske funksjoner til et felles område, vanligvis mellom 0 og 1. Det opprettholder de relative forskjellene mellom verdier og sikrer at alle funksjoner er på like vilkår.

#1. Funksjonsverktøy
Funksjonsverktøy er et åpen kildekode Python-rammeverk som automatisk lager funksjoner fra tidsmessige og relasjonsdatasett. Den kan brukes med verktøy du allerede bruker for å utvikle ML-rørledninger.
Løsningen bruker Deep Feature Synthesis for å automatisere funksjonsutvikling. Den har et bibliotek med funksjoner på lavt nivå for å lage funksjoner. Featuretools har også en API, som også er ideell for presis håndtering av tid.
#2. CatBoost
Hvis du ser etter et åpen kildekode-bibliotek som kombinerer flere beslutningstrær for å lage en kraftig prediktiv modell, gå for CatBoost. Denne løsningen gir nøyaktige resultater med standardparametere, slik at du ikke trenger å bruke timer på å finjustere parameterne.
CatBoost lar deg også bruke ikke-numeriske faktorer for å forbedre treningsresultatene dine. Med den kan du også forvente å få mer nøyaktige resultater og raske spådommer.
#3. Funksjonsmotor
Funksjonsmotor er et Python-bibliotek med flere transformatorer og utvalgte funksjoner som du kan bruke for ML-modeller. Transformatorene den inkluderer kan brukes til variabel transformasjon, variabeloppretting, datotidsfunksjoner, forhåndsbehandling, kategorisk koding, avgrensning eller fjerning og manglende dataimputering. Den er i stand til å gjenkjenne numeriske, kategoriske og datetime-variabler automatisk.
Feature Engineering læringsressurser
Nettkurs og virtuelle klasser

#1. Funksjonsteknikk for maskinlæring i Python: Datacamp
Denne datacampen kurs om funksjonsteknikk for maskinlæring i Python lar deg lage nye funksjoner som forbedrer ytelsen til din maskinlæringsmodell. Den vil lære deg å utføre funksjonsutvikling og datamunging for å utvikle sofistikerte ML-applikasjoner.
#2. Funksjonsteknikk for maskinlæring: Udemy
Fra Feature Engineering for Machine Learning-kursvil du lære emner inkludert imputasjon, variabelkoding, funksjonsekstraksjon, diskretisering, datotidsfunksjonalitet, uteliggere osv. Deltakerne vil også lære å jobbe med skjeve variabler og håndtere sjeldne, usynlige og sjeldne kategorier.
#3. Feature Engineering: Pluralsight
Dette Flertallssyn læringsbanen har totalt seks emner. Disse kursene vil hjelpe deg å lære viktigheten av funksjonsteknikk i ML-arbeidsflyt, måter å bruke teknikkene på og funksjonsutvinning fra tekst og bilder.
#4. Funksjonsvalg for maskinlæring: Udemy
Ved hjelp av dette Udemy kurset kan deltakerne lære funksjonsstokking, filter, wrapper og innebygde metoder, rekursiv funksjonseliminering og uttømmende søk. Den diskuterer også funksjonsvalgsteknikker, inkludert de med Python, Lasso og beslutningstrær. Dette kurset inneholder 5,5 timer med on-demand video og 22 artikler.
#5. Funksjonsteknikk for maskinlæring: God læring
Dette kurset fra Flott læring vil introdusere deg for funksjonsteknikk mens du lærer deg om oversampling og undersampling. Videre lar den deg utføre praktiske øvelser på modellinnstilling.
#6. Feature Engineering: Coursera
Bli med Coursera kurs for å bruke BigQuery ML, Keras og TensorFlow for å utføre funksjonsutvikling. Dette kurset på mellomnivå dekker også avansert funksjonsteknikk.
Digitale eller innbundne bøker

#1. Funksjonsteknikk for maskinlæring
Denne boken lærer deg hvordan du transformerer funksjoner til formater for maskinlæringsmodeller.
Den lærer deg også funksjoner ingeniørprinsipper og praktisk anvendelse gjennom trening.
#2. Funksjonsteknikk og utvalg
Ved å lese denne boken vil du lære metodene for å utvikle prediktive modeller i ulike stadier.
Fra den kan du lære teknikker for å finne de beste prediktorrepresentasjonene for modellering.
#3. Funksjonsteknikk gjort enkelt
Boken er en guide for å forbedre prediksjonskraften til ML-algoritmer.
Den lærer deg å designe og lage effektive funksjoner for ML-baserte applikasjoner ved å tilby dyptgående datainnsikt.
#4. Feature Engineering Bookcamp
Denne boken tar for seg praktiske case-studier for å lære deg funksjonsteknikker for bedre ML-resultater og oppgradert datakrangel.
Å lese dette vil sikre at du kan levere forbedrede resultater uten å bruke mye tid på å finjustere ML-parametrene.
#5. The Art of Feature Engineering
Ressursen fungerer som et viktig element for enhver dataforsker eller maskinlæringsingeniør.
Boken bruker en tilnærming på tvers av domener for å diskutere grafer, tekster, tidsserier, bilder og casestudier.
Konklusjon
Så dette er hvordan du kan utføre funksjonsutvikling. Nå som du kjenner definisjonen, trinnvise prosessen, metodene og læringsressursene, kan du implementere disse i ML-prosjektene dine og se suksessen!
Neste opp, sjekk ut artikkelen om forsterkende læring.