Forståelse av Naturlig Språkbehandling (NLP) og dens Algoritmer
Menneskelig språk er komplekst og fullt av nyanser, noe som gjør det utfordrende for maskiner å forstå. Det inneholder akronymer, flertydige ord, underforståtte meninger, grammatiske regler, kontekstuelle faktorer, slang og andre språklige særegenheter.
Mange moderne forretningsprosesser og operasjoner er imidlertid avhengig av maskiner, og krever derfor en effektiv kommunikasjon mellom mennesker og datamaskiner.
Dette skapte behovet for en teknologi som kunne hjelpe maskiner med å tyde menneskelig språk og gjøre det enklere for dem å lære og forstå det.
Dette var bakgrunnen for utviklingen av Naturlig Språkbehandling (NLP) algoritmer. Disse algoritmene gir dataprogrammer evnen til å forstå menneskelig språk, både i skriftlig og muntlig form.
NLP benytter seg av en rekke algoritmer for språklig analyse. Introduksjonen av NLP-algoritmer har gjort denne teknologien til en nøkkelkomponent i kunstig intelligens (AI), som er avgjørende for å effektivt behandle ustrukturert data.
I denne artikkelen vil vi utforske NLP og noen av de mest brukte algoritmene.
La oss dykke inn!
Hva er NLP?
Naturlig Språkbehandling (NLP) er et fagfelt som kombinerer datavitenskap, lingvistikk og kunstig intelligens. Det fokuserer på interaksjonen mellom menneskelig språk og datamaskiner. NLP gir maskiner evnen til å analysere og behandle store mengder data som er knyttet til naturlig språk.
Kort sagt, NLP er en avansert teknologi som lar maskiner forstå, analysere og tolke menneskelig språk. Den gir maskinene muligheten til å forstå både tekst og talespråk. Gjennom NLP kan maskiner utføre oppgaver som oversettelse, talegjenkjenning, tekstoppsummering, temaidentifisering og mange andre oppgaver.
Det som er bemerkelsesverdig, er at NLP utfører alle disse oppgavene i sanntid ved hjelp av en rekke algoritmer, noe som øker effektiviteten. NLP kombinerer maskinlæring, dyp læring og statistiske modeller med regelbasert modellering fra beregningslingvistikk.
NLP-algoritmer tillater datamaskiner å behandle menneskelig språk i form av tekst eller talte data, og deretter tolke betydningen. Datamaskiners evne til å tolke har utviklet seg så mye at maskiner nå kan forstå menneskelige følelser og intensjoner som ligger bak en tekst. NLP kan til og med forutsi kommende ord eller setninger mens brukeren skriver eller snakker.
Denne teknologien har vært under utvikling i flere tiår, og har stadig blitt forbedret med tanke på prosessnøyaktighet. NLP har røtter i lingvistikken og var avgjørende for å skape søkemotorer for internett. Etter hvert som teknologien har utviklet seg, har bruksområdene for NLP også utvidet seg.
I dag har NLP en rekke bruksområder, inkludert finans, søkemotorer, forretningsanalyse, helsevesen og robotikk. NLP er også integrert i moderne systemer, som talestyrt GPS, kundeservicechatbots, digitale assistenter og tale-til-tekst-funksjoner.
Hvordan Fungerer NLP?
NLP er en dynamisk teknologi som benytter ulike metoder for å oversette komplekst menneskelig språk til maskinspråk. Den bruker hovedsakelig kunstig intelligens for å behandle og oversette skriftlige eller talte ord, slik at datamaskiner kan forstå dem.
Akkurat som mennesker har hjerner for å behandle informasjon, bruker datamaskiner spesielle programmer for å omdanne input til forståelig output. NLP fungerer i to hovedfaser: dataforbehandling og algoritmeutvikling.
Dataforbehandling er den første fasen, der tekstdataene forberedes og renses for å gjøre det mulig for maskinen å analysere dem. Dataene behandles slik at alle funksjonene i inputteksten fremheves, og det klargjøres for bruk av maskinalgoritmer. I hovedsak forbereder dataforbehandlingsfasen dataene i et format som datamaskinen forstår.
Følgende teknikker er involvert i denne fasen:
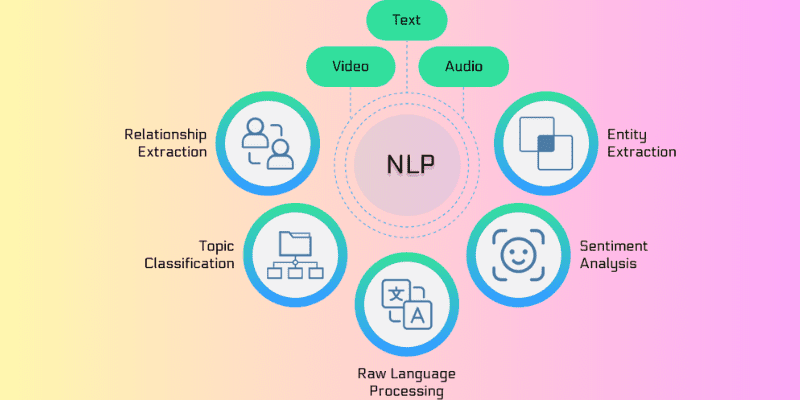
Kilde: Amazinum
- Tokenisering: Inputteksten deles opp i mindre enheter, eller tokens, for å gjøre den mer håndterlig for NLP.
- Fjerning av stoppord: Vanlige ord (stoppord) som «og,» «eller,» og «i» fjernes, slik at de mest meningsbærende ordene i teksten står igjen.
- Lemmatisering og stemming: Ord reduseres til sine rotformer for å gjøre det lettere for maskiner å behandle dem.
- Ord tagging: Hvert ord i teksten identifiseres og merkes basert på sin grammatiske funksjon, for eksempel substantiv, verb eller adjektiv.
Etter at inputdataene har passert gjennom den første fasen, utvikler maskinen en algoritme der dataene kan behandles. Blant alle NLP-algoritmene som brukes for å behandle forbehandlede ord, er regelbaserte og maskinlæringsbaserte systemer mest brukt:
- Regelbaserte systemer: Disse systemene bruker språklige regler for den endelige behandlingen av ord. Dette er en eldre algoritme som fortsatt er i bruk i dag.
- Maskinlæringsbaserte systemer: Disse avanserte algoritmene kombinerer nevrale nettverk, dyp læring og maskinlæring for å utvikle sine egne regler for ordbehandling. Algoritmen bruker statistiske metoder og endrer seg etter hvert som den lærer av treningsdata.
Forskjellige Kategorier av NLP-Algoritmer
NLP-algoritmer er maskinlæringsbaserte instruksjoner som brukes under behandling av naturlig språk. De er utviklet for å bygge modeller som gjør maskiner i stand til å forstå og tolke menneskelig språk.

NLP-algoritmer kan endre form i henhold til AI-tilnærmingen og treningsdataene som brukes. Hovedformålet med disse algoritmene er å bruke forskjellige teknikker for å omdanne ustrukturert input til nyttig informasjon som maskiner kan lære av.
I tillegg til ulike teknikker, bruker NLP-algoritmer også prinsipper for naturlig språk for å gjøre input mer forståelig for maskiner. De er ansvarlige for å hjelpe maskiner med å forstå kontekstverdien av en input. Uten denne forståelsen ville maskinene ikke kunne utføre den forespurte oppgaven.
NLP-algoritmer deles inn i tre hovedkategorier, og AI-modeller velger en av disse kategoriene avhengig av dataspesialistens strategi. Disse kategoriene er:
#1. Symbolske Algoritmer
Symbolske algoritmer er en av bærebjelkene i NLP-algoritmer. De analyserer betydningen av hver inputtekst for å etablere relasjoner mellom ulike konsepter.
Symbolske algoritmer bruker symboler for å representere kunnskap og relasjonene mellom begreper. Disse algoritmene bruker logikk og tildeler mening til ord basert på kontekst. Dette kan gi høy nøyaktighet.
Kunnskapsgrafer spiller en viktig rolle i å definere konsepter for inputspråk, samt forholdet mellom disse konseptene. Evnen til å definere begreper nøyaktig og forstå ordkontekst gjør denne algoritmen verdifull for å bygge Explainable AI (XAI).
Symbolske algoritmer kan imidlertid være vanskelig å utvide på grunn av ulike begrensninger.
#2. Statistiske Algoritmer
Statistiske algoritmer analyserer tekster, forstår hver av dem og henter ut betydningen. Dette er en effektiv NLP-algoritme som hjelper maskiner å lære om menneskelig språk ved å gjenkjenne mønstre og trender i tekstutvalg. Denne analysen hjelper maskiner med å forutsi det neste ordet i sanntid.
Statistiske algoritmer brukes for mange applikasjoner, fra talegjenkjenning og sentimentanalyse til maskinoversettelse og tekstforslag. De er populære fordi de kan fungere på store datasett.
I tillegg kan statistiske algoritmer identifisere om to setninger i et avsnitt er like i betydning og velge den mest hensiktsmessige setningen. Den største ulempen er at den delvis avhenger av kompleks funksjonsteknikk.
#3. Hybride Algoritmer
Denne typen NLP-algoritmer kombinerer fordelene med symbolske og statistiske algoritmer for å skape effektive resultater. Ved å fokusere på styrkene til hver tilnærming kan de redusere svakhetene ved hver enkelt metode, noe som er avgjørende for å oppnå høy nøyaktighet.
Det er flere måter å kombinere disse to tilnærmingene:
- Symbolsk støtte for maskinlæring
- Maskinlæring som støtter symbolsk
- Symbolsk og maskinlæring fungerer parallelt
Symbolske algoritmer kan støtte maskinlæring ved å hjelpe den med å trene modellen slik at den trenger mindre anstrengelse for å lære språket på egen hånd. På den annen side, hvis maskinlæring støtter symbolske metoder, kan ML-modellen lage et innledende regelsett for den symbolske algoritmen og dermed spare dataspesialisten for å bygge det manuelt.
Når symbolsk og maskinlæring fungerer sammen, kan dette gi bedre resultater fordi det kan sikre at modellene forstår et spesifikt avsnitt på riktig måte.
Beste NLP-Algoritmer
Det finnes mange NLP-algoritmer som hjelper en datamaskin med å forstå og etterligne menneskelig språk. Her er noen av de beste NLP-algoritmene som er i bruk i dag:
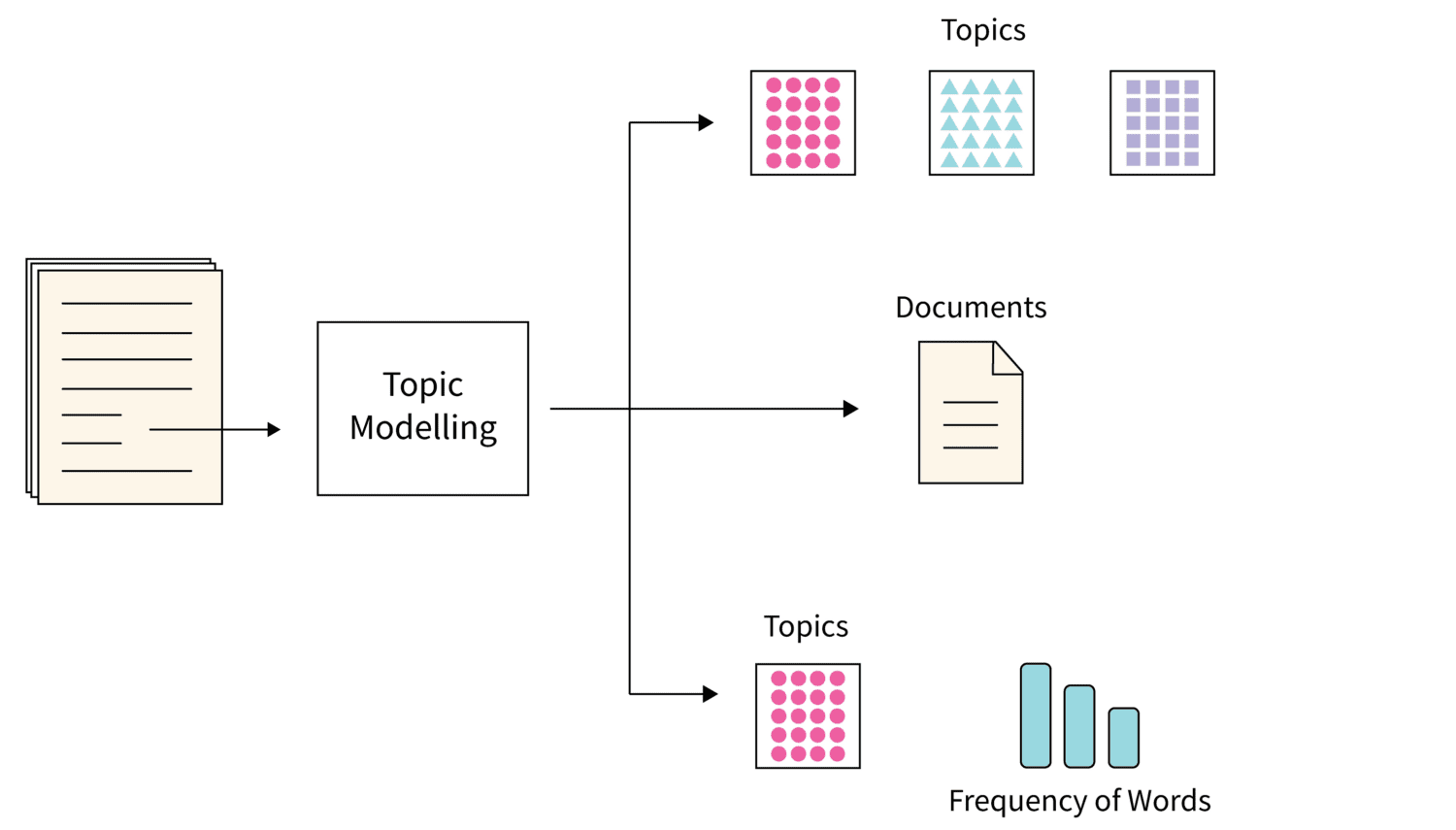
#1. Temamodellering
 Bildekilde: Scaler
Bildekilde: Scaler
Temamodellering er en algoritme som bruker statistiske NLP-teknikker for å finne temaer eller hovedemner i store mengder tekstdokumenter.
I hovedsak hjelper det maskiner med å identifisere det underliggende emnet som definerer et bestemt tekstsett. Siden hver tekstsamling inneholder mange emner, bruker denne algoritmen en rekke teknikker for å finne hvert emne ved å vurdere bestemte ordsett.
Latent Dirichlet Allocation (LDA) er et populært valg for emnemodellering. Det er en uovervåket maskinlæringsalgoritme som hjelper med å samle og organisere arkiver med store mengder data på en måte som ikke er mulig med menneskelig annotering.
#2. Tekstoppsummering
Tekstoppsummering er en avansert NLP-teknikk som algoritmer bruker for å oppsummere en tekst på en kortfattet og flytende måte. Det er en rask prosess der all verdifull informasjon hentes ut uten å lese hvert ord i teksten.
Oppsummering kan gjøres på to måter:
- Ekstraksjonsbasert oppsummering: Maskinen trekker ut hovedordene og -frasene fra dokumentet uten å endre originalteksten.
- Abstraksjonsbasert oppsummering: I denne prosessen lages nye ord og uttrykk fra tekstdokumentet, som gjenspeiler all informasjon og intensjon.
#3. Sentimentanalyse
Sentimentanalyse er en NLP-algoritme som hjelper maskiner med å forstå meningen eller intensjonen bak en tekst fra en bruker. Den er mye brukt i ulike AI-modeller fordi det hjelper virksomheter å forstå hva kundene mener om produktene eller tjenestene deres.
Ved å forstå intensjonen bak kunders tekst- eller talte data kan AI-modeller identifisere kundens følelser og hjelpe bedrifter med å tilpasse seg.
#4. Nøkkelordekstraksjon
Nøkkelordekstraksjon er en annen populær NLP-algoritme som hjelper med å trekke ut et stort antall relevante ord og uttrykk fra et sett med tekstdata.
Det finnes ulike algoritmer for nøkkelordekstraksjon, for eksempel TextRank, Term Frequency og RAKE. Noen algoritmer bruker tilleggsord, mens andre hjelper med å trekke ut nøkkelord basert på innholdet i en gitt tekst.
Hver algoritme for nøkkelordekstraksjon bruker sine egne teoretiske metoder. Dette er nyttig for mange organisasjoner fordi det hjelper med å lagre, søke etter og hente innhold fra et stort, ustrukturert datasett.
#5. Kunnskapsgrafer
Kunnskapsgrafer er en verdifull NLP-algoritme. De bruker tripler for å lagre informasjon.
Denne algoritmen bruker en blanding av tre elementer: emne, predikat og enhet. Opprettelsen av en kunnskapsgraf er ikke begrenset til én enkelt teknikk, men krever heller bruk av flere NLP-teknikker for å gjøre den mer effektiv og detaljert. Emnetilnærmingen brukes for å trekke ut strukturert informasjon fra ustrukturerte tekster.
#6. TF-IDF
TF-IDF er en statistisk NLP-algoritme som er viktig for å evaluere betydningen av et ord i et bestemt dokument som er en del av en stor samling. Denne teknikken innebærer multiplikasjon av to verdier:
- Termfrekvens (TF): Viser hvor ofte et ord forekommer i et bestemt dokument. Stoppord har vanligvis høy termfrekvens i et dokument.
- Invers dokumentfrekvens (IDF): Viser begreper som er spesifikke for et dokument, eller ord som forekommer sjelden i hele samlingen av dokumenter.
#7. Ordskyer
Ordskyer er en unik NLP-algoritme som bruker datavisualiseringsteknikker. De viktigste ordene er uthevet og vises i en tabell.
De viktigste ordene i dokumentet vises med større skrift, mens de mindre viktige ordene vises med mindre skriftstørrelser. Noen ganger er de mindre viktige ordene nesten usynlige.
Læringsressurser
Hvis du er interessert i å lære mer om Naturlig Språkbehandling (NLP), bør du vurdere følgende kurs og bøker:
#1. Data Science: Naturlig Språkbehandling i Python

Dette kurset fra Udemy er høyt vurdert av studenter og laget av Lazy Programmer Inc. Det dekker alle aspekter ved NLP, inkludert NLP-algoritmer og sentimentanalyse. Kurset har en total varighet på 11 timer og 52 minutter og inkluderer 88 forelesninger.
#2. Naturlig Språkbehandling: NLP med Transformers i Python
Dette populære kurset fra Udemy gir innsikt i NLP med transformatormodeller, og du vil lære hvordan du finjusterer disse modellene. Kurset har 11,5 timer med on-demand video og 5 artikler. Du vil også lære om vektoriseringsteknikker og hvordan du forbehandler tekstdata for NLP.
#3. Naturlig Språkbehandling med Transformatorer
Denne boken ble utgitt i 2017 og har som mål å hjelpe dataforskere og programmerere med å lære om NLP. Du lærer å bygge og optimalisere transformatormodeller for en rekke NLP-oppgaver, og hvordan du bruker transformatorer for tverrspråklig læring.
#4. Praktisk Naturlig Språkbehandling
I denne boken forklarer forfatterne oppgavene, problemene og løsningene for NLP. Boken dekker også implementering og evaluering av ulike NLP-applikasjoner.
Konklusjon
NLP er en integrert del av dagens AI-verden og hjelper maskiner med å forstå og tolke menneskelig språk. NLP-algoritmer er nyttige for en rekke bruksområder, fra søkemotorer og IT til finans, markedsføring og mer.
I tillegg til informasjonen ovenfor har vi listet opp noen av de beste NLP-kursene og bøkene som kan hjelpe deg med å utvide din kunnskap om NLP.