Apache Kafka og RabbitMQ er to populære meldingsformidlere som muliggjør en frakoblet kommunikasjon mellom ulike applikasjoner. Men hva er de essensielle egenskapene, og hvordan skiller de seg fra hverandre? La oss dykke ned i konseptene.
RabbitMQ
RabbitMQ er en åpen kildekode meldingsmegler for kommunikasjon og datautveksling mellom ulike parter. Den er utviklet i Erlang, noe som gir den en lett og effektiv struktur. Erlang-språket, utviklet av Ericsson, er spesielt designet med tanke på distribuerte systemer.
Den regnes som en mer tradisjonell meldingsformidler, basert på et publiser-abonner-mønster. Den kan likevel håndtere kommunikasjon synkront eller asynkront, avhengig av konfigureringen. Den sikrer også pålitelig levering og korrekt rekkefølge av meldinger mellom produsenter og konsumenter.
RabbitMQ støtter protokoller som AMQP, STOMP, MQTT, HTTP og WebSockets. Den bruker tre hovedmodeller for meldingsutveksling: emne, fanout og direkte:
- Direkte og individuell utveksling basert på et emne eller tema [topic].
- Alle konsumenter tilkoblet en kø mottar en [fanout] melding.
- Hver konsument mottar en dedikert [direct] melding.
Her er de sentrale komponentene i RabbitMQ:
Produsenter
Produsenter er applikasjoner som genererer og sender meldinger til RabbitMQ. Dette kan være enhver applikasjon som er i stand til å koble seg til RabbitMQ og publisere meldinger.
Konsumenter
Konsumenter er applikasjoner som mottar og behandler meldinger fra RabbitMQ. Dette kan være enhver applikasjon som kan koble seg til RabbitMQ og abonnere på meldinger.
Utvekslinger
Utvekslinger tar imot meldinger fra produsenter og dirigerer dem til de riktige køene. Det finnes flere typer utvekslinger, inkludert direkte, fanout, emne og overskriftsutvekslinger, hver med sine egne rutingsregler.
Køer
Køer er lagringsplassen for meldinger til de blir konsumert av konsumenter. De opprettes enten av applikasjoner eller automatisk av RabbitMQ når en melding publiseres til en utveksling.
Bindinger
Bindinger definerer relasjonen mellom utvekslinger og køer. De spesifiserer rutingsreglene for meldinger som utvekslingene bruker for å sende meldinger til de riktige køene.
Arkitekturen til RabbitMQ
RabbitMQ benytter en pull-modell for meldingslevering. I denne modellen ber konsumentene aktivt om meldinger fra megleren. Meldinger publiseres til utvekslinger, som deretter dirigerer meldingene til de korrekte køene basert på rutingsnøkler.
Arkitekturen til RabbitMQ er bygget på en klient-tjener-modell og består av flere komponenter som samarbeider for å tilby en pålitelig og skalerbar meldingsplattform. AMQP-konseptet sørger for komponentene Exchanges, Queues, Bindings, samt utgivere og abonnenter. Utgivere publiserer meldinger til utvekslinger.
Utvekslinger tar disse meldingene og distribuerer dem til 0 til n køer basert på spesifikke regler (bindinger). Meldingene som er lagret i køene kan deretter hentes av konsumenter. I en forenklet form, er prosessen for meldingshåndtering i RabbitMQ slik:
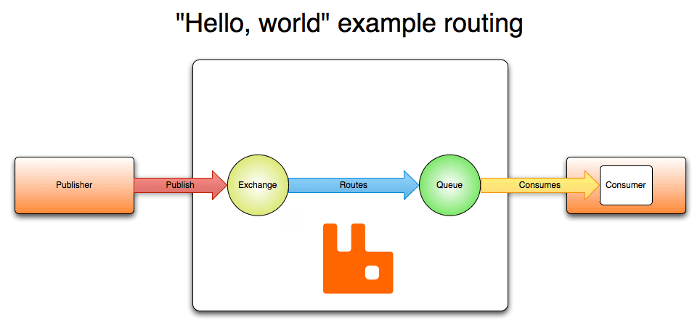
Bildekilde: VMware
- Utgivere sender meldinger til en utveksling.
- Utvekslingen sender meldinger til køer og andre utvekslinger.
- Når en melding mottas, sender RabbitMQ en bekreftelse til avsenderen.
- Konsumenter opprettholder en konstant TCP-forbindelse til RabbitMQ og angir hvilken kø de skal motta meldinger fra.
- RabbitMQ dirigerer meldingene til konsumentene.
- Konsumentene sender bekreftelser om mottak (suksess eller feil).
- Ved vellykket mottak slettes meldingen fra køen.
Apache Kafka
Apache Kafka er en distribuert, åpen kildekode meldingsløsning utviklet av LinkedIn i Scala. Den er i stand til å behandle og lagre meldinger med en publiser-abonner-modell med høy skalerbarhet og ytelse.

For å lagre hendelser eller mottatte meldinger, distribueres emnene mellom noder ved hjelp av partisjoner. Den kombinerer publiser-abonner og meldingskø mønstre, og den sikrer også rekkefølgen på meldinger for hver konsument.
Kafka er spesielt designet for å håndtere høy datagjennomstrømning og lav latens for datastrømmer i sanntid. Dette oppnås ved å minimere logikk på serversiden (megler), samt ved spesifikke implementeringsdetaljer.
For eksempel bruker Kafka ikke RAM i det hele tatt, men skriver data umiddelbart til serverens filsystem. Siden alle data skrives sekvensielt, oppnås en lese-skriveytelse som er sammenlignbar med RAM.
Her er de viktigste konseptene som gjør Kafka skalerbar, høyytelses og feiltolerant:
Emne
Et emne er en måte å merke eller kategorisere en melding på. Tenk deg et skap med ti skuffer; hver skuff kan representere et emne, og skapet er Apache Kafka-plattformen. I tillegg til å kategorisere, grupperer den også meldinger. En annen analogi kan være databaser.
Produsent
Produsenten er den som kobler seg til en meldingsplattform og sender en eller flere meldinger om et spesifikt emne.
Konsument
Konsumenten er den som kobler seg til en meldingsplattform og mottar en eller flere meldinger om et spesifikt emne.
Megler
Megleren i Kafka-plattformen er i praksis Kafka selv, som administrerer emnene og definerer hvordan meldinger, logger, osv. lagres.
Klynge
Klyngen er et sett med meglere som kommuniserer, eller ikke, for å oppnå bedre skalerbarhet og feiltoleranse.
Loggfil
Hvert emne lagrer sine data i et loggformat, strukturert og sekvensielt. Loggfilen er filen som inneholder informasjon om et spesifikt emne.
Partisjoner
Partisjoner er lagene som deler meldingene innenfor et emne. Denne partisjoneringen sikrer fleksibiliteten, feiltoleransen og skalerbarheten til Apache Kafka. Hvert emne kan ha flere partisjoner på forskjellige steder.
Arkitekturen til Apache Kafka
Kafka baserer seg på en push-modell for meldingslevering. I denne modellen sendes meldinger aktivt til konsumentene. Meldinger publiseres til emner som er delt opp i partisjoner og distribuert over ulike meglere i klyngen.
Konsumenter kan deretter abonnere på ett eller flere emner og motta meldinger etterhvert som de produseres om disse emnene.
I Kafka er hvert emne delt opp i en eller flere partisjoner, og det er i disse partisjonene at hendelsene lagres.
Hvis det er mer enn én megler i klyngen, vil partisjonene fordeles jevnt over alle meglerne (så langt det er mulig). Dette gjør det mulig å skalere belastningen for skriving og lesing i et emne til flere meglere samtidig. Siden det er en klynge, bruker den ZooKeeper for synkronisering.
Kafka mottar, lagrer og distribuerer data. En melding er data generert av en systemnode, som kan være en hendelse eller annen informasjon. Den sendes til klyngen, og klyngen lagrer den i en partisjon for emnet.
Hver melding har en sekvensiell offset, og konsumenten kan kontrollere offseten som de bruker. Dette gjør det mulig å behandle emnet på nytt basert på offset.
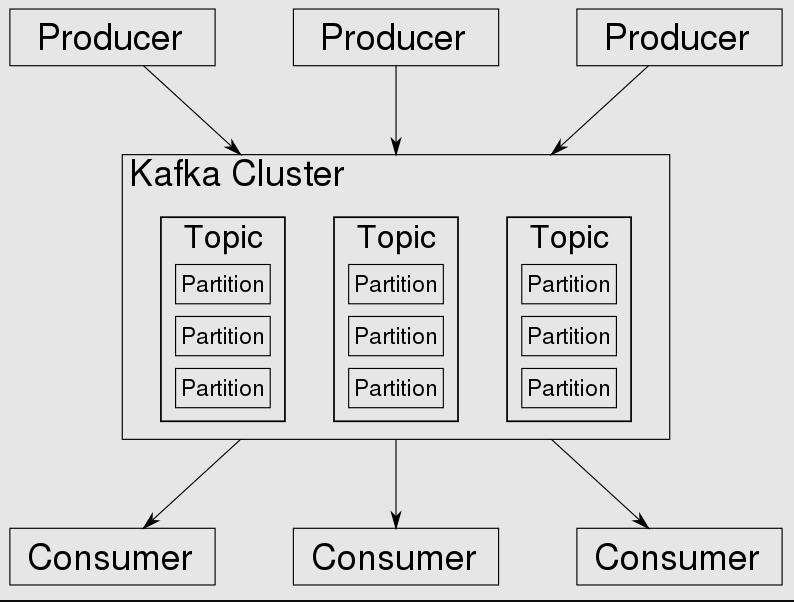
Bildekilde: Wikipedia
Logikk, som for eksempel administrering av den sist leste meldings-IDen til en konsument eller bestemmelsen av hvilken partisjon nye data skal skrives til, er flyttet til klienten (produsent eller konsument).
I tillegg til konseptene produsent og konsument, finnes det også emne, partisjon og replikering. Et emne beskriver en kategori med meldinger. Kafka oppnår feiltoleranse ved å replikere data i et emne, og skalerer ved å partisjonere emnet over flere servere.
RabbitMQ vs. Kafka
De viktigste forskjellene mellom Apache Kafka og RabbitMQ stammer fra fundamentalt ulike modeller for meldingslevering implementert i disse systemene.
Apache Kafka opererer etter en pull-modell, der konsumenter selv henter meldingene de trenger fra emnet.
RabbitMQ bruker derimot push-modellen, og sender de nødvendige meldingene til mottakerne. Her er hvordan Kafka skiller seg fra RabbitMQ:
#1. Arkitektur
En av de største forskjellene er arkitekturen. RabbitMQ bruker en tradisjonell meglerbasert meldingskøarkitektur, mens Kafka bruker en distribuert strømmeplattformarkitektur. RabbitMQ bruker også en pull-basert meldingsleveringsmodell, mens Kafka bruker en push-basert modell.
#2. Lagre meldinger
RabbitMQ legger meldingen i en FIFO-kø (First Input – First Output) og overvåker statusen til meldingen. Kafka derimot, legger meldingen til en logg (skriver til disk), og lar mottakeren hente den nødvendige informasjonen fra emnet. RabbitMQ sletter meldingen etter at den er levert til mottakeren, mens Kafka lagrer meldingen til den skal ryddes opp i loggen.
Kafka lagrer dermed nåværende og tidligere systemtilstander og kan brukes som en pålitelig kilde til historisk data, i motsetning til RabbitMQ.
#3. Lastbalansering
RabbitMQ reduserer ventetiden takket være sin pull-modell. Men mottakere kan bli overbelastet hvis meldinger kommer raskere inn i køen enn de kan behandle dem. Siden hver mottaker i RabbitMQ ber om/laster opp et ulikt antall meldinger, kan fordelingen av arbeidet bli ujevn, noe som kan føre til forsinkelser og tap av rekkefølge under behandling. For å unngå dette, konfigurerer hver RabbitMQ-mottaker en forhåndshentingsgrense. I Kafka utføres lastbalansering automatisk ved å omfordele mottakere på tvers av partisjonene av emnet.
#4. Ruting
RabbitMQ har fire måter å rute meldinger til forskjellige utvekslinger for køer, noe som gir et kraftig og fleksibelt sett med meldingsmønstre. Kafka implementerer kun én måte å skrive meldinger til disk, uten ruting.
#5. Meldinger i riktig rekkefølge
RabbitMQ lar deg opprettholde rekkefølge i grupper av hendelser, mens Apache Kafka gir en enkel måte å opprettholde rekkefølge med skalerbarhet ved å skrive meldinger sekvensielt til en replikert logg (emne).
| Feature | RabbitMQ | Kafka |
| Arkitektur | Lagrer meldinger på en disk koblet til megler | Distribuert strømmeplattformarkitektur |
| Leveringsmodell | Pullbasert | Pushbasert |
| Lagre meldinger | Kan ikke lagre meldinger | Vedholder bestillinger ved å skrive til et emne |
| Lastbalansering | Konfigurerer en forhåndshentingsgrense | Utføres automatisk |
| Ruting | Inkluderer kun 4 måter å skrive på ruten i | Ma-ordre-grupper. til emne |
| Eksterne prosesser | Krever ikke | Krever å kjøre Zookeeper-forekomst |
| Plugins | Flere plugins | Har begrenset plugin-støtte |
Både RabbitMQ og Kafka er populære meldingssystemer, hver med sine egne styrker og bruksområder. RabbitMQ er fleksibelt, pålitelig og skalerbart, og utmerker seg i meldingskø, noe som gjør det ideelt for applikasjoner som krever pålitelig og fleksibel meldingslevering. Kafka er derimot en distribuert strømmeplattform designet for høy gjennomstrømning og sanntidsbehandling av store datamengder, som passer godt for applikasjoner som krever sanntidsbehandling og dataanalyse.
Hovedbrukstilfeller for RabbitMQ:
E-handel

RabbitMQ brukes i e-handelsapplikasjoner for å administrere dataflyten mellom ulike systemer, som lagerstyring, ordrebehandling og betalingsbehandling. Den kan håndtere store meldingsmengder og sikre at de leveres pålitelig og i riktig rekkefølge.
Helsevesen
I helsesektoren brukes RabbitMQ til datautveksling mellom ulike systemer, som elektroniske pasientjournaler (EPJ), medisinsk utstyr og kliniske beslutningsstøttesystemer. Dette kan forbedre pasientbehandlingen og redusere feil ved å sikre at riktig informasjon er tilgjengelig til rett tid.
Finansielle tjenester
RabbitMQ muliggjør sanntidsmeldinger mellom systemer, som handelsplattformer, risikostyringssystemer og betalingsgatewayer. Dette bidrar til å sikre at transaksjoner behandles raskt og sikkert.
IoT-systemer
RabbitMQ brukes i IoT-systemer for å administrere dataflyt mellom ulike enheter og sensorer. Dette bidrar til å sikre at data leveres sikkert og effektivt, selv i miljøer med begrenset båndbredde og ustabil tilkobling.
Kafka er en distribuert strømmeplattform designet for å håndtere store datamengder i sanntid.
Hovedbrukstilfeller for Kafka
Sanntidsanalyse

Kafka brukes i sanntidsanalyseapplikasjoner for å behandle og analysere data etterhvert som de genereres, slik at virksomheter kan ta beslutninger basert på oppdatert informasjon. Den kan håndtere store datamengder og skalere for å møte behovene til selv de mest krevende applikasjonene.
Loggaggregering
Kafka kan samle logger fra forskjellige systemer og applikasjoner, slik at virksomheter kan overvåke og feilsøke sanntidsproblemer. Den kan også brukes til å lagre logger for langsiktig analyse og rapportering.
Maskinlæring
Kafka brukes i maskinlæringsapplikasjoner for å strømme data til modeller i sanntid, slik at bedrifter kan gjøre spådommer og iverksette tiltak basert på oppdatert informasjon. Dette kan bidra til å forbedre nøyaktigheten og effektiviteten til maskinlæringsmodeller.
Min mening om både RabbitMQ og Kafka
Ulempen med RabbitMQs brede og varierte muligheter for fleksibel håndtering av meldingskøer er økt ressursforbruk og dermed redusert ytelse under økt belastning. Siden dette er driftsmåten for komplekse systemer, vil Apache Kafka i de fleste tilfeller være det beste verktøyet for å administrere meldinger.
Når det gjelder innsamling og aggregering av mange hendelser fra dusinvis av systemer og tjenester, med tanke på georeservasjoner, klientmålinger, loggfiler og analyser, med utsikter til økende informasjonskilder, vil jeg for eksempel foretrekke å bruke Kafka. Men hvis du bare trenger rask meldingsutveksling, vil RabbitMQ gjøre jobben helt fint.
Du kan også lese om hvordan du installerer Apache Kafka i Windows og Linux.