Hver AWS-tjeneste genererer loggdata som lagres i filer, organisert under CloudWatch-loggrupper. Disse loggruppene har ofte navn som tilsvarer tjenesten de tilhører, noe som gjør det enkelt å identifisere dem. Som standard registreres systemmeldinger og felles tilstandsinformasjon i disse loggfilene.
Det er imidlertid mulig å legge til tilpasset logginformasjon i tillegg til standardmeldingene. Når disse loggene opprettes på en gjennomtenkt måte, kan de danne grunnlaget for nyttige CloudWatch-dashbord.
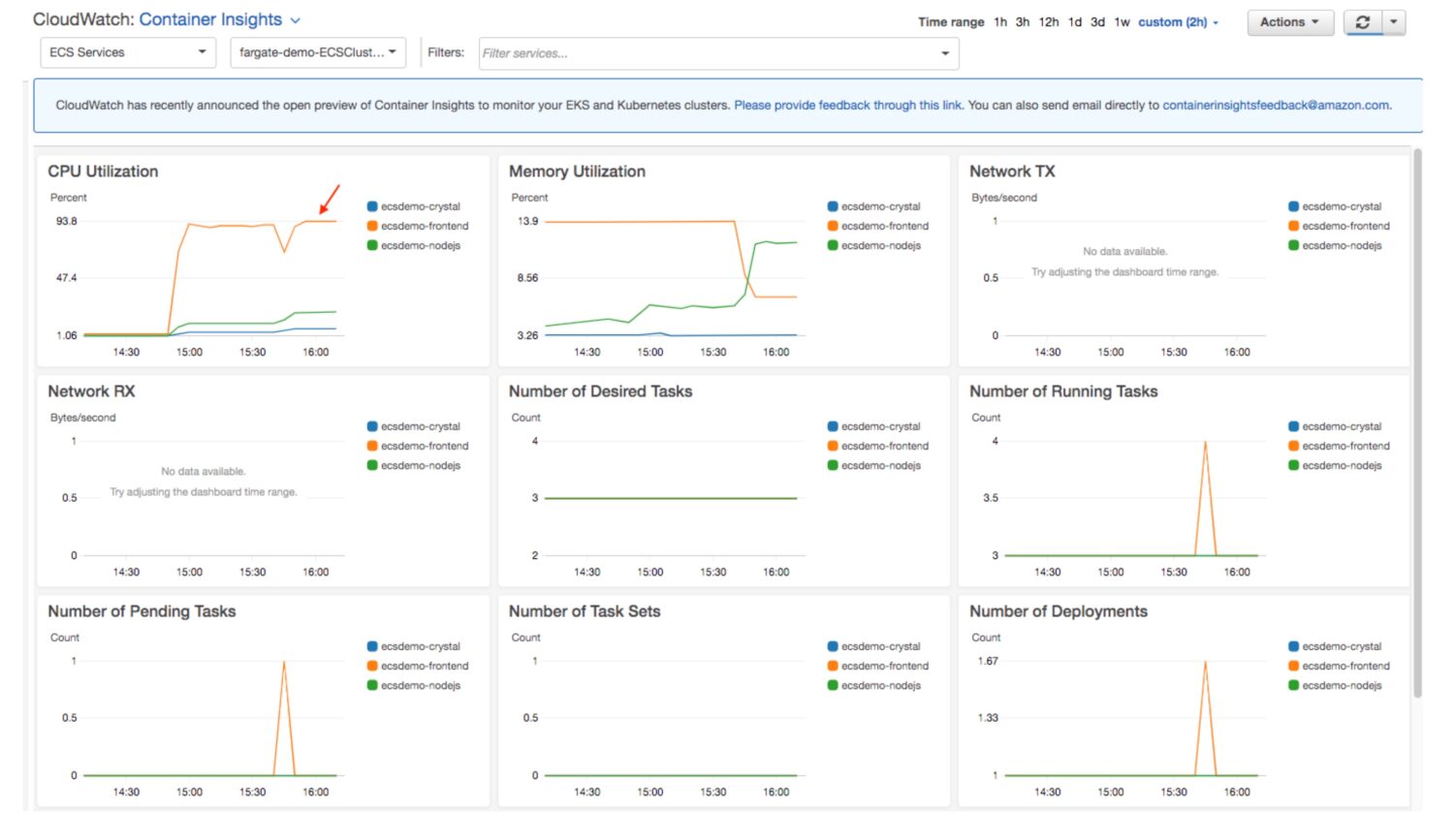
Med beregninger og strukturert informasjon kan du få detaljert innsikt i hvordan oppgaver behandles. Dashbordene trenger ikke bare inneholde standardinformasjon om tjenesten; du kan utvide dem med eget innhold, samlet i egendefinerte widgets eller beregninger.
Søk i loggfilene
Kilde: aws.amazon.com
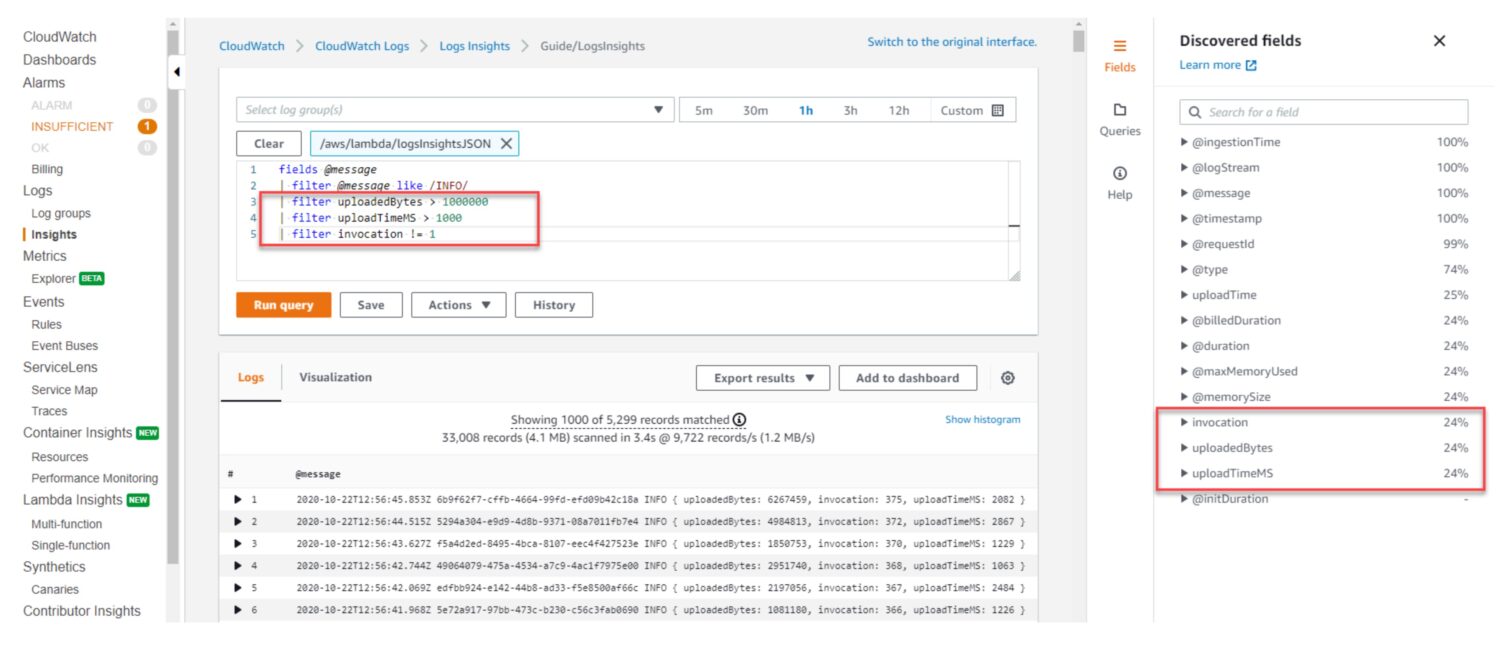
AWS CloudWatch Log Insights gir deg muligheten til å søke i og analysere loggdata fra dine AWS-ressurser i sanntid. Det fungerer litt som et databasevisning. Du definerer søket på dashbordet, og systemet vil utføre søket hver gang du besøker dashbordet, eller i et angitt tidsintervall.
Systemet bruker et spørringsspråk som kalles CloudWatch Logs Insights, som er basert på en undergruppe av SQL. Dette språket lar deg søke etter og filtrere loggdata. Du kan søke etter spesifikke logghendelser, tilpasset loggtekst eller nøkkelord, og filtrere loggdata basert på bestemte felt. Det viktigste er at du kan samle loggdata fra en eller flere loggfiler for å generere oppsummerte beregninger og visualiseringer.
Når du kjører en spørring, vil CloudWatch Log Insights analysere loggdataene i den aktuelle loggruppen. Systemet vil deretter returnere de tekstene fra filene som stemmer overens med dine søkekriterier.
Eksempel på loggfilsøk
La oss se på noen enkle søk for å forstå konseptet.
Som standard logger hver tjeneste noen viktige tjenestefeil, selv om du ikke har opprettet en egen tilpasset logg for feil. Med en enkel spørring kan du telle antall feil i applikasjonsloggene dine i løpet av den siste timen:
fields @timestamp, @message | filter @message like /ERROR/ | stats count() by bin(1h)
Eller her ser du hvordan du kan overvåke den gjennomsnittlige responstiden til API-et ditt den siste dagen:
fields @timestamp, @message | filter @message like /API response time/ | stats avg(response_time) by bin(1d)
Siden CPU-bruk er standardinformasjon som logges av tjenesten i CloudWatch, kan du også samle inn denne typen beregninger:
fields @timestamp, @message | filter @message like /CPUUtilization/ | stats avg(value) by bin(1h)
Disse spørringene kan tilpasses dine spesifikke behov og kan brukes til å lage egendefinerte beregninger og visualiseringer i CloudWatch Dashboards. Du legger inn widgeten på dashbordet og plasserer koden inni for å definere hva som skal hentes.
Her er noen av widgetene som kan brukes i CloudWatch Dashboards og fylles med data fra Log Insights:
- Tekstwidgets – Viser tekstbasert informasjon, for eksempel resultatet av en CloudWatch Insights-spørring.
- Loggspørringswidgeter – Viser resultatene av en CloudWatch Insights-loggspørring, for eksempel antall feil i applikasjonsloggene dine.
Hvordan lage nyttig logginformasjon for dashbord
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
For å bruke CloudWatch Insights-spørringer effektivt i CloudWatch Dashboards, er det lurt å følge noen gode fremgangsmåter når du oppretter CloudWatch-logger for tjenestene dine. Her er noen tips:
#1. Bruk strukturert logging
Bruk et loggformat med et forhåndsdefinert skjema for å logge data i et strukturert format. Dette gjør det lettere å søke i og filtrere loggdata ved hjelp av CloudWatch Insights-spørringer.
Det betyr i praksis at du bør standardisere loggene dine på tvers av forskjellige tjenester i din arkitektur. Det er svært nyttig å ha dette definert i utviklingsstandardene.
For eksempel kan du definere at hvert problem knyttet til en bestemt databasetabell skal logges med en startmelding som: «[TABELLNAVN] Advarsel / Feil: <melding>».
Eller du kan skille fullstendige datajobber fra deltadatajobber med prefikser som «[FULL/DELTA]» for bare å velge meldinger knyttet til disse spesifikke dataprosessene.
Du kan bestemme at når du behandler data fra et bestemt kildesystem, skal navnet på systemet være et prefiks for hver relatert loggoppføring. Det er mye lettere å filtrere slike meldinger og lage beregninger over dem i etterkant.
#2. Bruk konsekvente loggformater
Bruk konsekvente loggformater på tvers av alle dine AWS-ressurser for å gjøre det enklere å søke i og filtrere loggdata ved hjelp av CloudWatch Insights-spørringer.
Dette henger sammen med det forrige punktet. Jo mer standardisert loggformatet er, jo lettere er det å bruke loggdataene. Utviklere kan da forholde seg til formatet og bruke det intuitivt.
Dessverre bryr de fleste prosjekter seg ikke om noen standarder rundt logging. Mange prosjekter oppretter ikke engang egendefinerte logger i det hele tatt. Det er sjokkerende, men også svært vanlig.
Jeg har ofte lurt på hvordan folk kan jobbe uten en god tilnærming til feilhåndtering. Og hvis noen har prøvd å gjøre feilhåndtering med unntak, har de som regel gjort det feil.
Et konsekvent loggformat er derfor svært verdifullt. Det er ikke mange som har det.
#3. Inkluder relevant metadata
Inkluder metadata i loggdataene dine, for eksempel tidsstempler, ressurs-ID-er og feilkoder. Dette gjør det enklere å søke i og filtrere loggdata ved hjelp av CloudWatch Insights-spørringer.
#4. Aktiver loggrotasjon
Aktiver loggrotasjon for å hindre at loggdataene dine blir for store og for å gjøre det lettere å søke i og filtrere loggdata ved hjelp av CloudWatch Insights-spørringer.
Å ikke ha loggdata er én ting, men å ha for mye av det uten struktur er like frustrerende. Hvis du ikke kan bruke dataene dine, er det like greit å ikke ha dem i det hele tatt.
#5. Bruk CloudWatch Logs Agents
Hvis du ikke ønsker å bygge ditt eget tilpassede loggsystem, så bruk i det minste CloudWatch Logs-agenter. De sender automatisk loggdata fra dine AWS-ressurser til CloudWatch-logger. Dette gjør det enklere å søke i og filtrere loggdata ved hjelp av CloudWatch Insights-spørringer.
Eksempler på mer komplekse innsikter
CloudWatch Insights-spørringer kan være mer kompliserte enn enkle to-linjers uttalelser.
fields @timestamp, @message | filter @message like /ERROR/ | filter @message not like /404/ | parse @message /.*[(?<timestamp>[^]]+)].*"(?<method>[^s]+)s+(?<path>[^s]+).*" (?<status>d+) (?<response_time>d+)/ | stats avg(response_time) as avg_response_time, count() as count by bin(1h), method, path, status | sort count desc | limit 20
Denne spørringen gjør følgende:
- Velger logghendelser som inneholder strengen «ERROR», men ikke «404».
- Analyserer loggmeldingen for å trekke ut tidsstemplet, HTTP-metoden, banen, statuskoden og responstiden.
- Beregner gjennomsnittlig responstid og antall logghendelser for hver kombinasjon av HTTP-metode, bane, statuskode og time.
- Sorterer resultatene etter antall i synkende rekkefølge.
- Begrenser utdataene til de 20 beste resultatene.
Denne spørringen identifiserer de vanligste feilene i applikasjonen din og sporer gjennomsnittlig responstid for hver kombinasjon av HTTP-metode, bane og statuskode. Du kan bruke resultatene til å lage egendefinerte beregninger og visualiseringer i CloudWatch Dashboards for å overvåke ytelsen til nettapplikasjonen og feilsøke problemer.
Et annet eksempel er å søke etter Amazon S3-tjenestemeldinger:
fields @timestamp, @message | filter @message like /REST.API.REQUEST/ | parse @message /.*"(?<method>[^s]+)s+(?<path>[^s]+).*" (?<status>d+) (?<response_time>d+)/ | stats avg(response_time) as avg_response_time, count() as count by bin(1h), method, path, status | sort count desc | limit 20
- Spørringen velger logghendelser som inneholder strengen «REST.API.REQUEST».
- Deretter analyseres loggmeldingen for å trekke ut HTTP-metoden, banen, statuskoden og responstiden.
- Den beregner gjennomsnittlig responstid og antall logghendelser for hver kombinasjon av HTTP-metode, bane og statuskode, og sorterer resultatene etter antall i synkende rekkefølge.
- Begrenser utdataene til de 20 beste resultatene.
Du kan bruke resultatene fra denne spørringen til å lage en linjegraf i et CloudWatch Dashboard som viser gjennomsnittlig responstid for hver kombinasjon av HTTP-metode, bane og statuskode over tid.
Bygge dashbordet
For å fylle ut beregningene og visualiseringene i CloudWatch Dashboards med utdata fra CloudWatch Insights-loggspørringer, kan du navigere til CloudWatch-konsollen og følge veiviseren for å bygge innholdet ditt.
Slik ser koden for et CloudWatch Dashboard ut når det inneholder beregninger basert på data fra CloudWatch Insights-spørringer:
{
"widgets": [
{
"type": "metric",
"x": 0,
"y": 0,
"width": 12,
"height": 6,
"properties": {
"metrics": [
[
"AWS/EC2",
"CPUUtilization",
"InstanceId",
"i-0123456789abcdef0",
{
"label": "CPU Utilization",
"stat": "Average",
"period": 300
}
]
],
"view": "timeSeries",
"stacked": false,
"region": "us-east-1",
"title": "EC2 CPU Utilization"
}
},
{
"type": "log",
"x": 0,
"y": 6,
"width": 12,
"height": 6,
"properties": {
"query": "fields @timestamp, @message
| filter @message like /ERROR/
| stats count() by bin(1h)
",
"region": "us-east-1",
"title": "Application Errors"
}
}
]
}
Dette CloudWatch-dashbordet inneholder to widgets:
- En metrisk widget som viser gjennomsnittlig CPU-bruk for en EC2-forekomst over tid. CloudWatch Insights Query fyller widgeten. Den velger CPU-bruksdata for en bestemt EC2-forekomst og samler dem i intervaller på 5 minutter.
- En loggwidget som viser antall applikasjonsfeil over tid. Den velger logghendelser som inneholder strengen «ERROR» og samler dem per time.
Dette er en fil i JSON-format som definerer dashbordet og beregningene. Den inneholder også selve innsiktsspørringen som en egenskap.
Du kan bruke koden og distribuere den til den AWS-kontoen du trenger. Hvis tjenestene og loggmeldingene er konsistente på tvers av alle dine AWS-kontoer og stadier, vil dashbordet fungere på alle kontoene uten at du trenger å endre kildekoden for dashbordet.
Siste ord
Å bygge en solid loggstruktur har alltid vært en god investering for systemets pålitelighet. Nå kan den tjene et enda større formål. Du kan få nyttige dashbord med beregninger og visualiseringer bare som en bieffekt av det.
Med en oppgave som bare må gjøres én gang, med litt ekstra arbeid, kan utviklingsteamet, testteamet og produksjonsbrukerne alle dra nytte av den samme løsningen.
Deretter kan du sjekke ut de beste AWS-overvåkingsverktøyene.