Big Data og Hadoop: Forbered deg til jobbintervjuet
En undersøkelse fra Forbes indikerer at imponerende 90% av verdens bedrifter benytter seg av Big Data-analyse for å generere investeringsrapporter. Dette understreker viktigheten av Big Data i dagens næringsliv.
I takt med at Big Data blir stadig mer utbredt, ser vi en tilsvarende økning i antall jobbmuligheter innenfor Hadoop. Dette skaper et marked med stor etterspørsel etter kompetente fagfolk.
For å assistere deg i å lande en Hadoop-ekspertrolle, har vi samlet et sett med relevante intervjuspørsmål og tilhørende svar. Denne artikkelen er utformet for å gi deg den nødvendige tryggheten og forberedelsen du trenger for å imponere i intervjuprosessen.
Er det ikke motiverende å vite at stillinger innen Hadoop og Big Data er lukrative? 🤔 La oss se på noen tall:
- Ifølge Indeed.com kan en Big Data Hadoop-utvikler i USA forvente en gjennomsnittlig årslønn på $144 000.
- Itjobswatch.co.uk rapporterer at en Big Data Hadoop-utvikler i Storbritannia tjener rundt £66 750 i snitt.
- I India anslår Indeed.com at en Hadoop-utvikler kan forvente en gjennomsnittlig årslønn på 16 000 000 INR.
Lønnsnivået er absolutt attraktivt! La oss nå dykke dypere inn i Hadoop-verdenen.
Hva er Hadoop?
Hadoop er et anerkjent rammeverk utviklet i Java. Det benytter seg av programmeringsmodeller for å håndtere, lagre og analysere enorme datamengder.
Arkitekturen tillater effektiv oppskalering fra en enkelt server til mange maskiner, noe som gir både lokal databehandling og lagring. I tillegg er Hadoop kjent for sin pålitelighet. Dette skyldes dens evne til å oppdage og håndtere feil i applikasjonslaget, noe som resulterer i svært tilgjengelige tjenester.
La oss nå gå rett til de ofte stilte intervjuspørsmålene om Hadoop, og se på de mest relevante svarene.
Hadoop Intervjuspørsmål og Svar
Hva er lagringsenheten i Hadoop?
Svar: Hadoops lagringsenhet er kjent som Hadoop Distributed File System (HDFS).
Hvordan skiller Network Attached Storage seg fra Hadoop Distributed File System?
Svar: HDFS, Hadoops primære lagringsstruktur, er et distribuert filsystem. Det er designet for å lagre enorme filer over råvaremaskinvare. NAS (Network Attached Storage), derimot, er en datalagringsserver på filnivå, som gir heterogene klientgrupper tilgang til data.
Mens NAS-datalagring er plassert på spesialisert maskinvare, distribuerer HDFS datablokkene over alle maskiner i en Hadoop-klynge. Dette gjør at HDFS kan utnytte ressurser mer effektivt.
NAS benytter avanserte lagringsenheter, noe som kan være kostbart. Råvaremaskinvaren som brukes i HDFS er derimot mer kostnadseffektiv.
NAS lagrer data separat fra beregninger, noe som gjør det mindre egnet for MapReduce. HDFS er designet for å fungere sømløst med MapReduce-rammeverket, hvor beregningene flyttes til dataene, istedenfor omvendt.
Forklar MapReduce i Hadoop og Shuffling
Svar: MapReduce refererer til to distinkte operasjoner som Hadoop-programmer utfører for å sikre stor skalerbarhet over hundrevis eller tusenvis av servere i en Hadoop-klynge. Shuffling, på den annen side, er prosessen med å overføre data fra kartleggingsprosessen til den aktuelle reduseringsprosessen i MapReduce.
Gi et innblikk i Apache Pig-arkitekturen
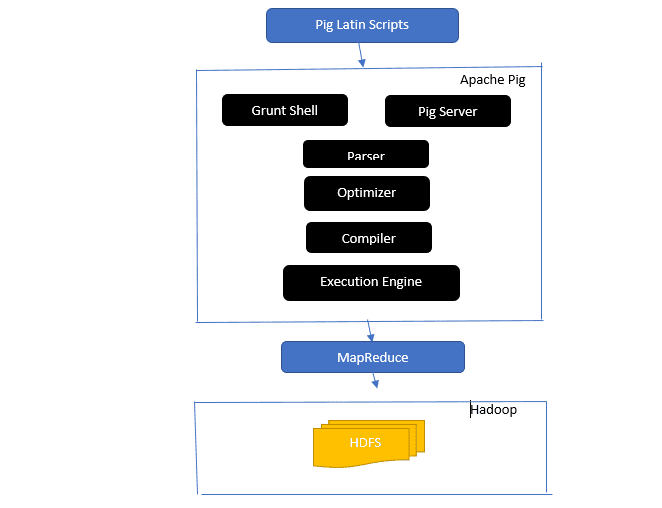
Svar: Apache Pig-arkitekturen omfatter en Pig Latin-tolk som behandler og analyserer store datasett ved hjelp av Pig Latin-skript.
Apache Pig inneholder også en rekke datasett som utfører dataoperasjoner som «join», «load», «filter», «sort» og «group».
Pig Latin-språket bruker utførelsesmekanismer som Grant-skall, UDF-er (brukerdefinerte funksjoner) og innebygde funksjoner for å lage Pig-skript som utfører de nødvendige oppgavene.
Pig forenkler programmereres arbeid ved å konvertere disse skrevne skriptene til sekvenser av MapReduce-jobber.
Komponentene i Apache Pig-arkitekturen inkluderer:
- Parser: Denne komponenten håndterer Pig-skriptene ved å sjekke syntaks og utføre typekontroll. Parserens utdata representerer Pig Latins utsagn og logiske operatorer, og er kjent som DAG (Directed Acyclic Graph).
- Optimizer: Optimalisereren utfører logiske optimaliseringer på DAG, som for eksempel projeksjon og pushdown.
- Kompilator: Denne komponenten kompilerer den optimaliserte logiske planen fra optimalisereren til en serie med MapReduce-jobber.
- Utførelsesmotor: Her foregår selve utførelsen av MapReduce-jobbene, som resulterer i ønsket output.
- Utførelsesmodus: Apache Pig har primært to utførelsesmoduser; lokal modus og MapReduce-modus.
Hva er de fem V-ene til Big Data?
Svar: De fem V-ene representerer de viktigste egenskapene til Big Data. De inkluderer:
- Verdi: Big Data har som mål å gi betydelige fordeler, fra høy avkastning på investeringen (ROI) for organisasjoner som bruker Big Data i sin datahåndtering. Big Data genererer denne verdien gjennom innsiktsavdekking og mønstergjenkjenning, noe som resulterer i sterkere kundeforhold og mer effektiv drift.
- Variasjon: Dette refererer til mangfoldet av datatyper som samles inn, som kan inkludere CSV-filer, videoer, lyd og mer.
- Volum: Dette definerer den massive mengden og størrelsen på data som håndteres og analyseres av en organisasjon. Disse dataene vokser eksponentielt.
- Hastighet: Dette er den høye hastigheten som data genereres og behandles.
- Sannhet: Sannhet refererer til hvor «usikker» eller «unøyaktig» dataen kan være, som et resultat av ufullstendig eller inkonsistent informasjon.
Forklar ulike datatyper i Pig Latin.
Svar: Datatypene i Pig Latin omfatter atomiske datatyper og komplekse datatyper.
Atomiske datatyper er de grunnleggende datatypene som brukes i mange programmeringsspråk, og inkluderer:
- Int: Dette er en 32-bits signert heltallsvariabel. Eksempel: 13
- Long: Definerer et 64-bits heltall. Eksempel: 10L
- Float: Dette er en 32-bits flytende-tallsverdi. Eksempel: 2.5F
- Double: Definerer en 64-bits flytende-tallsverdi. Eksempel: 23.4
- Boolean: En boolsk verdi, enten «true» eller «false».
- Datetime: Representerer en dato og tid-verdi. Eksempel: 1980-01-01T00:00.00.000+00:00
Komplekse datatyper inkluderer:
- Map: En samling av nøkkel-verdi par. Eksempel: [«color’#’yellow», «number’#3]
- Bag: En samling tupler som bruker «{}»-symbolet. Eksempel: {(Henry, 32), (Kiti, 47)}
- Tuple: En ordnet sekvens av felt. Eksempel: (Alder, 33)
Hva er Apache Oozie og Apache ZooKeeper?
Svar: Apache Oozie er en Hadoop-planlegger som er ansvarlig for å planlegge og sammenkoble Hadoop-jobber til et enkelt logisk arbeid.
Apache ZooKeeper koordinerer med ulike tjenester i et distribuert miljø. Det sparer utviklerne tid ved å tilby enkel tilgang til tjenester som synkronisering, gruppering, konfigurasjonsvedlikehold og navngiving. Apache ZooKeeper gir også støtte for køer og ledervalg.
Hva er rollene til Combiner, RecordReader og Partitioner i en MapReduce-operasjon?
Svar: Combiner fungerer som en minireduksjon. Den mottar data fra kartoppgaver, bearbeider disse, og sender deretter resultatet videre til reduksjonsfasen.
RecordReader kommuniserer med InputSplit og konverterer data til nøkkel-verdi-par, som deretter kan leses av kartleggeren.
Partitioner er ansvarlig for å bestemme antall reduserende oppgaver som kreves for å oppsummere data og for å bekrefte hvordan kombineringsutgangene sendes til reduseringselementet. Partitioner kontrollerer også nøkkelpartisjonering av de mellomliggende kartutgangene.
Nevn ulike leverandørspesifikke distribusjoner av Hadoop.
Svar: Det finnes flere leverandører som utvider funksjonaliteten til Hadoop, inkludert:
- IBM Open Platform
- Cloudera CDH Hadoop Distribution
- MapR Hadoop Distribution
- Amazon Elastic MapReduce
- Hortonworks Data Platform (HDP)
- Pivotal Big Data Suite
- Datastax Enterprise Analytics
- Microsoft Azure HDInsight (skybasert Hadoop-distribusjon)
Hvorfor er HDFS feiltolerant?
Svar: HDFS oppnår feiltoleranse ved å replikere data på tvers av forskjellige DataNodes. Dette tillater henting av data fra andre noder hvis en node krasjer.
Skille mellom føderasjon og høy tilgjengelighet.
Svar: HDFS-føderasjon tilbyr feiltoleranse, noe som sikrer kontinuerlig dataflyt selv om en node krasjer. Høy tilgjengelighet krever at to separate maskiner konfigureres med en aktiv NameNode og en sekundær NameNode, som kjører på henholdsvis den første og andre maskinen.
En føderasjon kan ha et ubegrenset antall urelaterte navnenoder, mens høy tilgjengelighet bare har to relaterte navnenoder – en aktiv og en standby – som jobber kontinuerlig.
Navnenodene i en føderasjon deler en metadatapool, der hver NameNode har sin dedikerte pool. I høy tilgjengelighet kjører de aktive NameNodene hver for seg mens standby-NameNodes forblir inaktive og oppdaterer metadataene med jevne mellomrom.
Hvordan finne statusen til blokker og filsystemhelse?
Svar: Du kan bruke kommandoen «hdfs fsck /» på både rotnivå og en individuell katalog for å sjekke statusen til HDFS-filsystemet.
Eksempel på bruk av «hdfs fsck» kommandoen:
hdfs fsck / -files --blocks --locations> dfs-fsck.log
Forklaring av kommandoen:
- -filer: Skriver ut filene som sjekkes.
- –plasseringer: Skriver ut plasseringen av hver blokk under sjekken.
Kommando for å sjekke statusen til blokkene:
hdfs fsck <path> -files -blocks
- <path>: Angir banen der kontrollen skal starte.
- –blokker: Skriver ut filblokkene under kontroll.
Når bruker du kommandoene «rmadmin-refreshNodes» og «dfsadmin-refreshNodes»?
Svar: Disse kommandoene er nyttige for å oppdatere nodeinformasjon enten under oppstart eller når nodeoppstarten er fullført.
«dfsadmin-refreshNodes» kommandoen kjører HDFS-klienten og oppdaterer konfigurasjonen for NameNodes. «rmadmin-refreshNodes» kommandoen utfører administrative oppgaver for ResourceManagers.
Hva er et sjekkpunkt?
Svar: Et sjekkpunkt er en operasjon som slår sammen filsystemets siste endringer med den nyeste FSImage, slik at redigeringsloggfilene forblir små nok til å fremskynde oppstartsprosessen av en NameNode. Sjekkpunkter utføres i den sekundære navnenoden.
Hvorfor bruker vi HDFS for applikasjoner med store datasett?
Svar: HDFS tilbyr en DataNode- og NameNode-arkitektur som implementerer et distribuert filsystem.
Disse to arkitekturene sikrer høyhastighetstilgang til data over svært skalerbare Hadoop-klynger. NameNode lagrer filsystemets metadata i RAM, som begrenser antallet filer i HDFS-filsystemet avhengig av mengden tilgjengelig minne.
Hva gjør «jps»-kommandoen?
Svar: Kommandoen Java Virtual Machine Process Status (JPS) sjekker om spesifikke Hadoop-demoner, inkludert NodeManager, DataNode, NameNode og ResourceManager, kjører. Denne kommandoen må kjøres fra rot for å sjekke driftsnodene i verten.
Hva er «spekulativ utførelse» i Hadoop?
Svar: Dette er en prosess der masternoden i Hadoop, istedenfor å fikse trege oppgaver, starter en ny instans av samme oppgave som en backup (spekulativ oppgave) på en annen node. Spekulativ utførelse er tidsbesparende, spesielt i miljøer med høy arbeidsbelastning.
Nevn de tre modusene som Hadoop kan kjøre i.
Svar: De tre primære modusene som Hadoop kan kjøre i er:
- Frittstående node: Dette er standardmodusen som kjører Hadoop-tjenestene med det lokale filsystemet og en enkelt Java-prosess.
- Pseudodistribuert node: Kjører alle Hadoop-tjenester på én enkelt node i en Hadoop-distribusjon.
- Fullt distribuert node: Kjører Hadoop-master- og slave-tjenester på separate noder.
Hva er en UDF?
Svar: UDF (User Defined Functions) lar deg kode dine egendefinerte funksjoner som du kan bruke til å prosessere kolonneverdier i en Impala-spørring.
Hva er DistCp?
Svar: DistCp eller Distributed Copy er et verktøy for å kopiere store datamengder mellom eller innenfor klynger. Ved å bruke MapReduce, implementerer DistCp effektivt den distribuerte kopieringen av store datamengder. Den håndterer også feil, gjenoppretting og rapportering.
Definer Hive metastore.
Svar: Hive metastore er en tjeneste som lagrer metadata for Apache Hive-tabellene i en relasjonsdatabase, som for eksempel MySQL. Det gir et API for å sentralt få tilgang til metadata.
Definer RDD.
Svar: RDD (Resilient Distributed Datasets) er Sparks datastruktur og en uforanderlig distribuert samling av dataelementer, som behandles på tvers av ulike klyngenoder.
Hvordan kan innfødte biblioteker inkluderes i YARN-jobber?
Svar: Dette kan implementeres enten ved å bruke «-Djava.library.path» i kommandoen, eller ved å angi «LD_LIBRARY_PATH» i .bashrc-filen i følgende format:
<property> <name>mapreduce.map.env</name> <value>LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/my/libs</value> </property>
Forklar «WAL» i HBase.
Svar: Write Ahead Log (WAL) er en gjenopprettingsprotokoll som registrerer endringer i MemStore-data i HBase før disse skrives til disk. WAL gjenoppretter disse dataene hvis en RegionalServer krasjer eller før MemStore tømmes.
Er YARN en erstatning for Hadoop MapReduce?
Svar: Nei, YARN er ikke en erstatning for Hadoop MapReduce. I stedet er YARN en teknologi i Hadoop 2.0 eller MapReduce 2 som støtter MapReduce.
Hva er forskjellen mellom ORDER BY og SORT BY i Hive?
Svar: Begge kommandoene sorterer data i Hive, men resultatene ved bruk av SORT BY kan bare være delvis sortert.
SORT BY krever en redusering for å sortere radene. Hvis flere reduseringselementer er nødvendig for endelig utdata, vil resultatet kunne være delvis sortert.
ORDER BY krever kun én reduseringsenhet for en total sortering. Du kan også bruke LIMIT-nøkkelordet for å redusere den totale sorteringstiden.
Hva er forskjellen mellom Spark og Hadoop?
Svar: Både Hadoop og Spark er distribuerte behandlingsrammeverk, men deres viktigste forskjell er tilnærmingen til databehandling. Hadoop er effektiv for batchbehandling, mens Spark er designet for sanntids databehandling.
Hadoop leser og skriver hovedsakelig filer til HDFS, mens Spark benytter seg av Resilient Distributed Dataset-konseptet til å behandle data i minnet.
Hadoop har høy latens uten en interaktiv modus for behandling, mens Spark har lav latens og støtter interaktiv databehandling.
Sammenlign Sqoop og Flume.
Svar: Sqoop og Flume er Hadoop-verktøy som samler inn data fra ulike kilder og laster dem inn i HDFS.
- Sqoop (SQL-til-Hadoop) henter strukturerte data fra databaser som Teradata, MySQL, og Oracle. Flume er utviklet for å hente ustrukturerte data fra ulike kilder og laste dem inn i HDFS.
- Flume er hendelsesdrevet, mens Sqoop ikke er det.
- Sqoop benytter en koblingsbasert arkitektur hvor koblinger vet hvordan de skal koble til ulike datakilder. Flume benytter en agentbasert arkitektur hvor koden som er skrevet fungerer som agenten som henter dataen.
- Flumes distribuerte natur gjør det enkelt å samle inn og aggregere data. Sqoop er nyttig for parallelle dataoverføringer, som resulterer i flere output-filer.
Forklar BloomMapFile.
Svar: BloomMapFile er en klasse som utvider MapFile-klassen og bruker dynamiske bloom-filtre, som sørger for en rask sjekk av medlemskap for nøkler.
List opp forskjellene mellom HiveQL og PigLatin.
Svar: HiveQL er et deklarativt språk som ligner på SQL, mens PigLatin er et prosedyreorientert dataflytspråk.
Hva er datavask?
Svar: Datavask er en viktig prosess som innebærer å fjerne eller korrigere datafeil som ukorrekte, ufullstendige, skadede, dupliserte og feilformaterte data i et datasett.
Prosessen er rettet mot å forbedre datakvaliteten og sørge for mer presis, konsistent og pålitelig informasjon, som er nødvendig for effektiv beslutningstaking i en organisasjon.
Konklusjon💃
Med den økende etterspørselen etter Big Data og Hadoop-kompetanse, er det viktig å forberede seg godt til intervjuer. Denne artikkelen med Hadoop-intervjuspørsmål og -svar vil hjelpe deg med å øke sjansene dine for å lykkes i din neste jobbintervju.
Du kan også utforske andre ressurser for å lære mer om Big Data og Hadoop.
Lykke til! 👍