Introduksjon til nettskraping
Nettskraping innebærer prosessen med å hente ut informasjon fra en nettside for spesifikk bruk. Det kan være en nyttig teknikk for å samle inn data for ulike formål.
Tenk deg at du ønsker å hente ut en tabell fra en nettside, konvertere den til en JSON-fil og deretter bruke den filen til interne verktøy. Med nettskraping kan du enkelt målrette mot de spesifikke elementene på en nettside og hente ut den informasjonen du trenger. Python er et populært valg for nettskraping, da det tilbyr flere biblioteker som BeautifulSoup og Scrapy som forenkler denne prosessen.
Som utvikler eller dataforsker er det viktig å kunne hente ut data på en effektiv måte. Denne artikkelen vil vise deg hvordan du kan skrape et nettsted på en effektiv måte og få tak i den informasjonen du trenger for å manipulere den til ditt bruk. Vi vil bruke BeautifulSoup-pakken for denne opplæringen, som er et mye brukt bibliotek for skraping av data i Python.
Hvorfor velge Python for nettskraping?
Python er et foretrukket valg for mange utviklere når de skal bygge nettskrapere. Det er flere grunner til dette. Her er tre hovedgrunner til at Python er et populært valg:
Biblioteker og fellesskapsstøtte: Python har et rikt utvalg av biblioteker som BeautifulSoup, Scrapy og Selenium, som tilbyr kraftige funksjoner for å skrape nettsider effektivt. I tillegg har Python et stort fellesskap, noe som gjør det enkelt å få hjelp og ressurser når du trenger det.
Automatisering: Python er kjent for sine automatiseringsmuligheter, som er essensielle hvis du skal bygge komplekse verktøy som er avhengig av skraping. For eksempel, hvis du vil lage et verktøy som overvåker prisendringer i en nettbutikk, trenger du automatiseringsfunksjoner for å kunne spore prisene daglig og lagre dem i en database. Python gir deg verktøyene til å automatisere slike prosesser.
Datavisualisering: Dataforskere bruker ofte nettskraping for å samle inn data. Python, med biblioteker som Pandas, gjør det enkelt å visualisere data fra rådata.
Biblioteker for nettskraping i Python
Det finnes flere biblioteker i Python som forenkler nettskraping. La oss se nærmere på tre av de mest populære:
1. BeautifulSoup
BeautifulSoup er et populært bibliotek for nettskraping som har hjulpet utviklere med å skrape nettsider siden 2004. Det tilbyr enkle metoder for å navigere, søke og endre analysetreet, og håndterer koding for innkommende og utgående data. Det er velholdt og har et stort fellesskap.
2. Scrapy
Scrapy er et annet populært rammeverk for datautvinning, med over 43 000 stjerner på GitHub. Det kan også brukes til å skrape data fra API-er og har innebygd støtte for funksjoner som å sende e-poster.
3. Selenium
Selenium er i hovedsak et verktøy for nettleserautomatisering, men kan også brukes til nettskraping. Det bruker WebDriver-protokollen for å kontrollere nettlesere, og har vært på markedet i nesten 20 år. Med Selenium kan du automatisere og skrape data fra nettsider.
Utfordringer med nettskraping i Python
Det er flere utfordringer man kan møte når man skraper data fra nettsider. Disse inkluderer trege nettverk, anti-skraping verktøy, IP-basert blokkering og captcha-blokkering, som kan forårsake problemer.
Det er imidlertid mulig å omgå mange av disse utfordringene. For eksempel, for å unngå IP-blokkering, kan du implementere en tidsforsinkelse i koden din etter at forespørsler er sendt. Utviklere kan også sette opp «honningfeller» som er usynlige for mennesker, men som skrapere kan snuble over. Det er viktig å skrive kode for å unngå slike feller. Captcha er også en utfordring, da de fleste nettsteder bruker det for å beskytte seg mot bot-tilgang. For å håndtere dette kan det være nødvendig å bruke en captcha-løser.

Skraping av et nettsted med Python
Vi skal bruke BeautifulSoup til å skrape et nettsted. I dette eksempelet vil vi hente ut historiske data om Ethereum fra Coingecko og lagre tabellinformasjonen i en JSON-fil. La oss se hvordan vi kan bygge denne skraperen.
Først må vi installere BeautifulSoup og Requests. Vi vil bruke Pipenv, en virtuell miljøadministrator for Python. Du kan også bruke Venv, men vi foretrekker Pipenv. Det er viktig å ha et isolert miljø for prosjektet ditt. Start Pipenv-skallet ved å kjøre kommandoen pipenv shell i prosjektmappen din. Dette vil starte et underskall i det virtuelle miljøet. Installer BeautifulSoup og Requests ved å kjøre følgende kommandoer:
pipenv install beautifulsoup4
pipenv install requests
Når installasjonen er ferdig, importerer vi pakkene til hovedfilen vår. Opprett en fil som heter main.py, og legg til følgende kode:
from bs4 import BeautifulSoup import requests import json
Neste steg er å hente innholdet fra den historiske datasiden og analysere det med HTML-parseren i BeautifulSoup:
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')
I koden over henter vi siden med get-metoden fra requests-biblioteket og lagrer det analyserte innholdet i variabelen «soup».
Den faktiske skrapeprosessen starter nå. Vi må identifisere den korrekte tabellen i DOM-en. Hvis du inspiserer nettsiden med utviklerverktøy i nettleseren, vil du se at tabellen har klassene «table table-striped text-sm text-lg-normal».
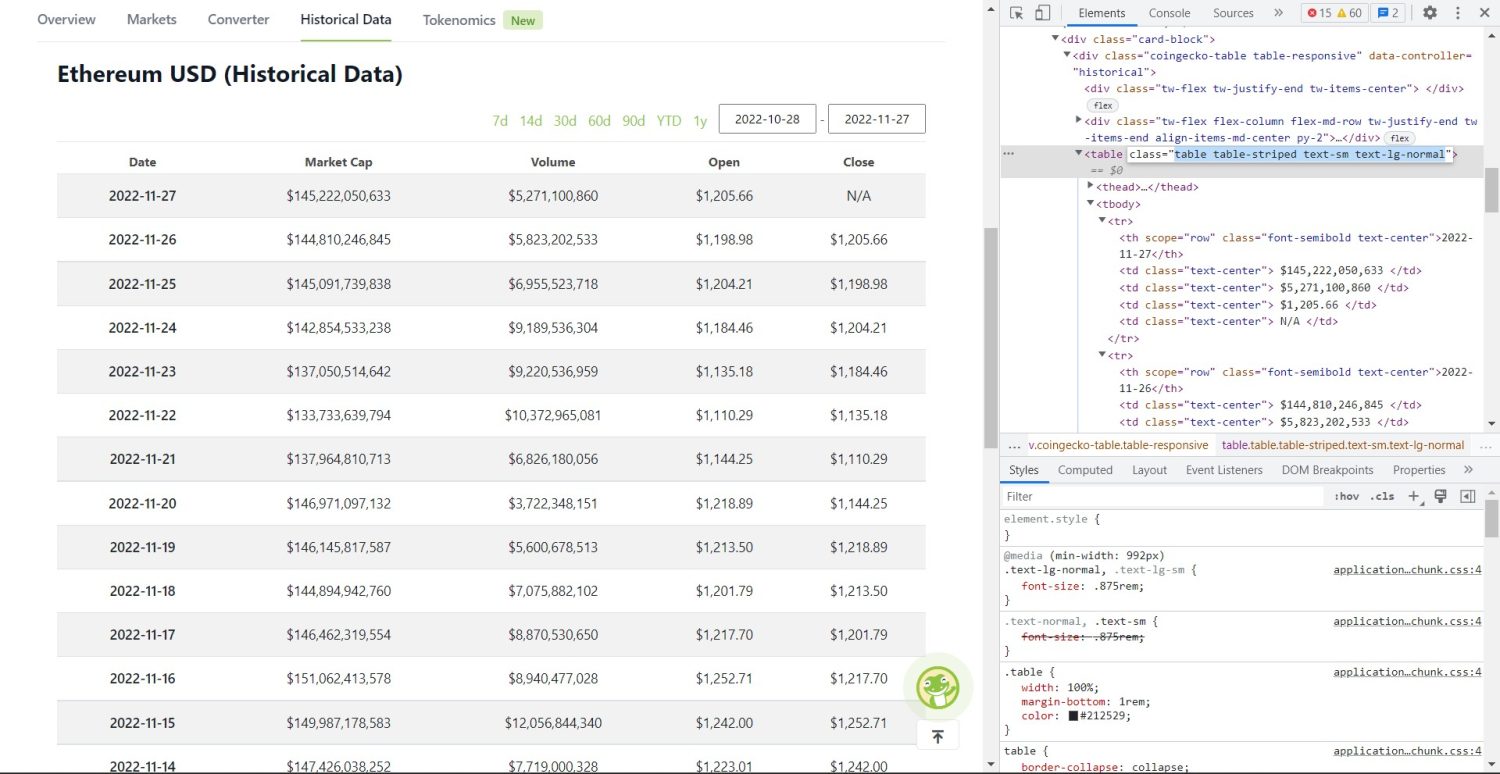
For å hente ut tabellen bruker vi finn-metoden:
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th'):
table_headings.append(th.text)
I koden over finner vi først tabellen med soup.find-metoden, og deretter bruker vi find_all-metoden for å finne alle tr-elementer i tabellen. Disse tr-elementene lagres i variabelen table_data. Tabellen har overskrifter. En ny variabel table_headings opprettes for å holde overskriftene i en liste.
En for-løkke går gjennom den første raden i tabellen. I denne raden søkes alle elementene med th, og teksten legges til listen table_headings. Hvis du skriver ut variabelen table_headings nå, vil du se:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']
Nå skal vi skrape resten av elementene, lage en ordbok for hver rad og legge dem til en liste:
table_details = []
for tr in table_data:
th = tr.find_all('th')
td = tr.find_all('td')
data = {}
for i in range(len(td)):
data.update({table_headings[0]: th[0].text})
data.update({table_headings[i+1]: td[i].text.replace('n', '')})
if data.__len__() > 0:
table_details.append(data)
Dette er den viktigste delen av koden. For hver tr i table_data søker vi først th-elementer, som er datoen i tabellen. Disse th-elementene lagres i variabelen th. På samme måte lagres alle td-elementene i variabelen td.
En tom ordbok «data» opprettes. Deretter går vi gjennom td-elementene. For hver rad oppdaterer vi først det første feltet i ordboken med det første elementet i th. Vi bruker koden table_headings[0]: th[0].text til å tilordne et nøkkelverdi-par av dato og det første elementet.
Etter det tilordnes de andre elementene ved hjelp av data.update({table_headings[i+1]: td[i].text.replace(«n», «»)}). Her trekkes teksten fra td-elementet først ut og erstatter «n» med en tom streng. Verdien tildeles deretter i+1 elementet i table_headings-listen.
Til slutt legges ordboken til table_details-listen hvis den har innhold. For å lagre verdiene i en JSON-fil bruker vi følgende kode:
with open('table.json', 'w') as f:
json.dump(table_details, f, indent=2)
print('Data saved to json file...')
Vi bruker json.dump metoden for å skrive verdiene til en JSON-fil kalt table.json. Når skrivingen er ferdig, skriver vi ut en melding i konsollen.
Kjør filen ved hjelp av følgende kommando:
python main.py
Etter en stund vil du se meldingen «Data saved to json file…» i konsollen og en ny fil kalt table.json i arbeidsmappen. Filen vil se ut som følgende:
[
{
"Date": "2022-11-27",
"Market Cap": "$145,222,050,633",
"Volume": "$5,271,100,860",
"Open": "$1,205.66",
"Close": "N/A"
},
{
"Date": "2022-11-26",
"Market Cap": "$144,810,246,845",
"Volume": "$5,823,202,533",
"Open": "$1,198.98",
"Close": "$1,205.66"
},
{
"Date": "2022-11-25",
"Market Cap": "$145,091,739,838",
"Volume": "$6,955,523,718",
"Open": "$1,204.21",
"Close": "$1,198.98"
},
// ...
// ...
]
Du har nå laget en nettskraper med Python. Du kan se hele koden i denne GitHub-repoen.
Konklusjon
Denne artikkelen har vist hvordan du kan lage en enkel Python-skraper. Vi har diskutert bruken av BeautifulSoup for å skrape data fra et nettsted. Vi har også sett på andre biblioteker og hvorfor Python er et populært valg for mange utviklere.
Du kan også se på disse nettskrapingsrammeverkene.