Data warehouse. Data lake. Et hus ved sjøen. Om ingen av disse uttrykkene gir deg noe, er jobben din trolig ikke relatert til data.
Likevel er det et nokså urealistisk utgangspunkt, siden det virker som at alt i dag er knyttet til data. Eller som ledere gjerne beskriver det:
- Datasentrisk og datadrevet virksomhet.
- Data hvor som helst, når som helst, på alle måter.
Den mest betydningsfulle ressursen
Data ser ut til å ha blitt den mest verdifulle ressursen for stadig flere selskaper. Jeg husker at store virksomheter alltid genererte store mengder data, terabyte med nye data hver måned. Dette var for 10-15 år siden. Nå kan du enkelt generere den samme mengden data i løpet av få dager. Det kan stilles spørsmål ved om dette er nødvendig, selv om det finnes innhold noen faktisk vil bruke. Og svaret er ofte nei 😃.
Ikke alt innhold vil ha noen nytte, og noe er ikke engang relevant. Jeg har ofte sett på nært hold hvordan bedrifter genererer enorme mengder data, som bare blir ubrukelig etter vellykket innlasting.
Men dette er ikke lenger tilfellet. Datalagring – nå i skyen – er rimelig, datakildene øker eksponentielt, og i dag kan ingen forutse hva de vil trenge om ett år når nye tjenester tas i bruk. Da kan selv de gamle dataene vise seg å være verdifulle.
Derfor er strategien å lagre så mye data som mulig. Men også i en så effektiv form som mulig. Slik at dataene ikke bare kan lagres effektivt, men også hentes, gjenbrukes, transformeres og distribueres videre.
La oss se på tre forskjellige måter for å oppnå dette i AWS:
- Athena Database – en rimelig og effektiv, men enkel måte å bygge en data lake i skyen.
- Redshift Database – en avansert skyversjon av et data warehouse, som har potensial til å erstatte de fleste lokale løsninger, uten å klare å holde tritt med den eksponensielle økningen i data.
- Databricks – en kombinasjon av en data lake og et data warehouse i én løsning, med noen ekstra fordeler.
Data Lake med AWS Athena
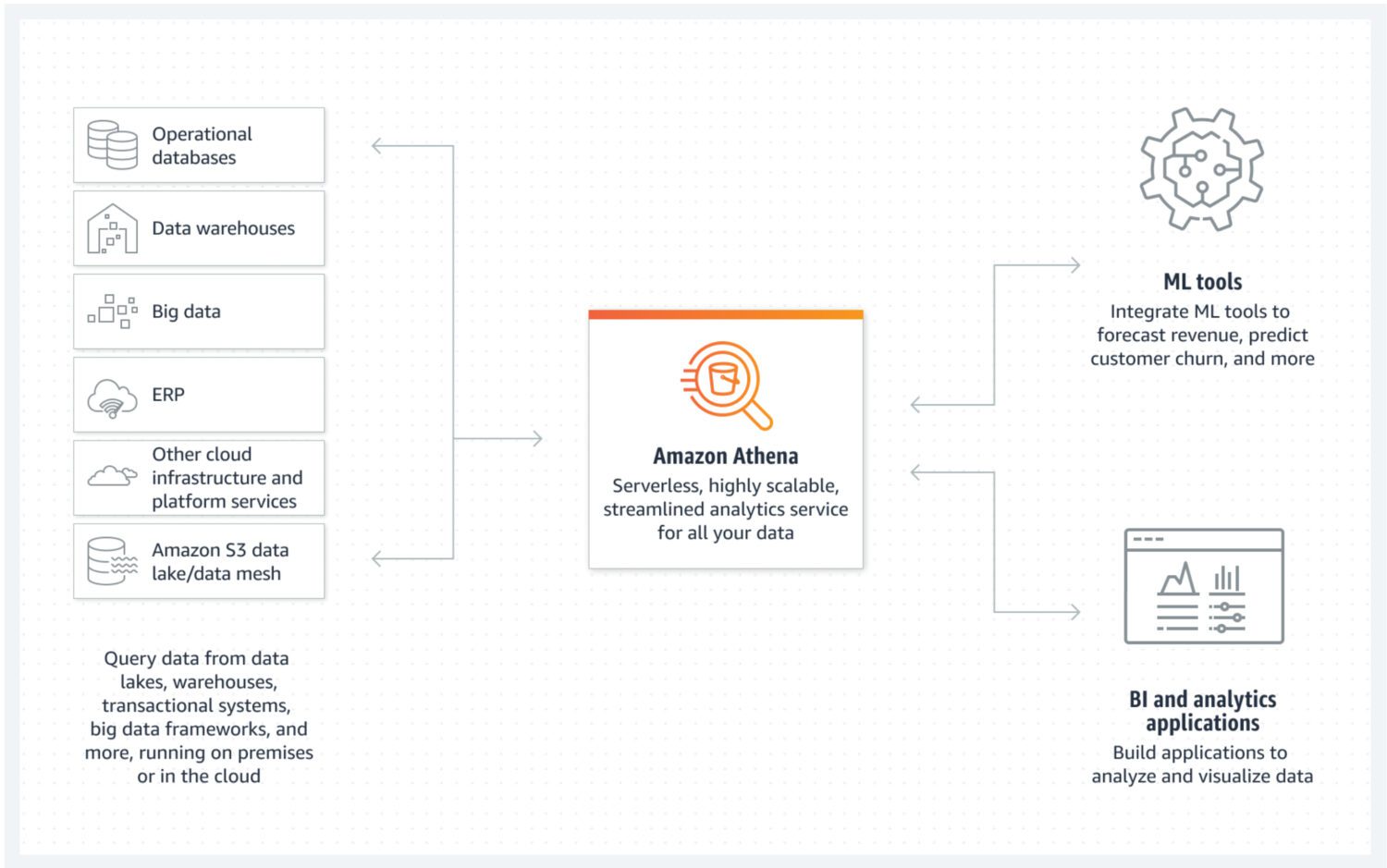
Kilde: aws.amazon.com
En data lake er et sted hvor du kan lagre inngående data i ustrukturert, semistrukturert eller strukturert form. Dataene lastes inn raskt, og endres ikke etter lagring. De skal være så atomære og uforanderlige som mulig. Bare dette vil sikre det største potensialet for gjenbruk i senere faser. Hvis denne egenskapen til dataene går tapt rett etter den første innlastingen i en data lake, er det ingen måte å gjenopprette denne informasjonen.
AWS Athena er en database med lagring direkte på S3-bøtter, uten serverklynger i bakgrunnen. Dette gjør det til en svært rimelig data lake-tjeneste. Strukturerte filformater som parkett eller CSV-filer (kommaseparerte verdier) opprettholder dataorganisasjonen. S3-bøtten inneholder filene, og Athena henviser til dem hver gang data velges fra databasen.
Athena støtter ikke alle funksjoner som ellers anses som standard, som for eksempel oppdateringserklæringer. Derfor må du se på Athena som et enkelt alternativ. På den annen side forhindrer den modifikasjon av den atomære data lake-en, rett og slett fordi du ikke kan 😐.
Den støtter indeksering og partisjonering, som gjør den brukbar for å effektivt utføre valgte setninger og for å lage logisk separate databiter (for eksempel atskilt med dato eller nøkkelkolonner). Den kan også enkelt skaleres horisontalt, ved å legge til nye bøtter i infrastrukturen.

Fordeler og ulemper
Fordeler:
- At Athena er rimelig (består bare av S3-bøtter og SQL-brukskostnader per bruk) er den største fordelen. Hvis du vil bygge en kostnadseffektiv data lake i AWS, er dette løsningen.
- Som en skybasert tjeneste integreres Athena enkelt med andre nyttige AWS-tjenester, som Amazon QuickSight for datavisualisering eller AWS Glue Data Catalog for å lage varige strukturerte metadata.
- Best for å kjøre ad hoc-spørringer over en stor mengde strukturerte eller ustrukturerte data, uten å vedlikeholde en hel infrastruktur rundt det.
Ulemper:
- Athena er ikke spesielt effektiv når det gjelder å raskt returnere komplekse utvalgte spørringer, særlig hvis spørringene ikke samsvarer med datamodellens forutsetninger for hvordan dataene skal hentes fra data lake-en.
- Dette gjør den også mindre fleksibel med tanke på fremtidige endringer i datamodellen.
- Athena støtter ikke noen ekstra avanserte funksjoner, og hvis du vil at noe spesifikt skal være en del av tjenesten, må du implementere det selv.
- Hvis du forventer data lake-bruk i et mer avansert presentasjonslag, er ofte det eneste alternativet å kombinere det med en annen databasetjeneste som er bedre egnet til formålet, som AWS Aurora eller AWS Dynamo DB.
Formål og praktisk anvendelse
Velg Athena hvis målet er å bygge en enkel data lake uten avanserte data warehouse-lignende funksjoner. For eksempel, hvis du ikke forventer komplekse og høyytelses analysespørringer som kjøres regelmessig over data lake-en. Prioriteten er å ha en samling uforanderlige data med enkel utvidelse av datalagring.
Du trenger ikke lenger å bekymre deg for plassmangel. Selv kostnadene for S3-bøttelagring kan reduseres ytterligere ved å implementere en datalivssykluspolicy. Dette betyr i bunn og grunn å flytte data på tvers av forskjellige typer S3-bøtter, mer rettet mot arkivformål med lavere kostnader, men tregere hentetider.
En flott funksjon med Athena er at den automatisk oppretter en fil som består av data som er en del av et resultat av SQL-spørringen din. Du kan deretter bruke denne filen til ethvert formål. Det er et godt alternativ hvis du har mange lambda-tjenester som viderebehandler dataene i flere trinn. Hvert lambda-resultat vil automatisk være i et strukturert filformat, klart for påfølgende behandling.
Athena er et godt alternativ i situasjoner der en stor mengde rådata kommer inn i skyinfrastrukturen din, og du ikke trenger å behandle den ved innlasting. Det betyr at alt du trenger er rask lagring i skyen i en lettforståelig struktur.
Et annet bruksområde er å opprette en dedikert plass for dataarkivering for en annen tjeneste. I et slikt tilfelle ville Athena DB være et rimelig sted for sikkerhetskopiering av data du ikke trenger akkurat nå, men som kan bli nødvendig i fremtiden. På dette tidspunktet vil du bare laste inn dataene og sende dem videre.
Data Warehouse med AWS Redshift
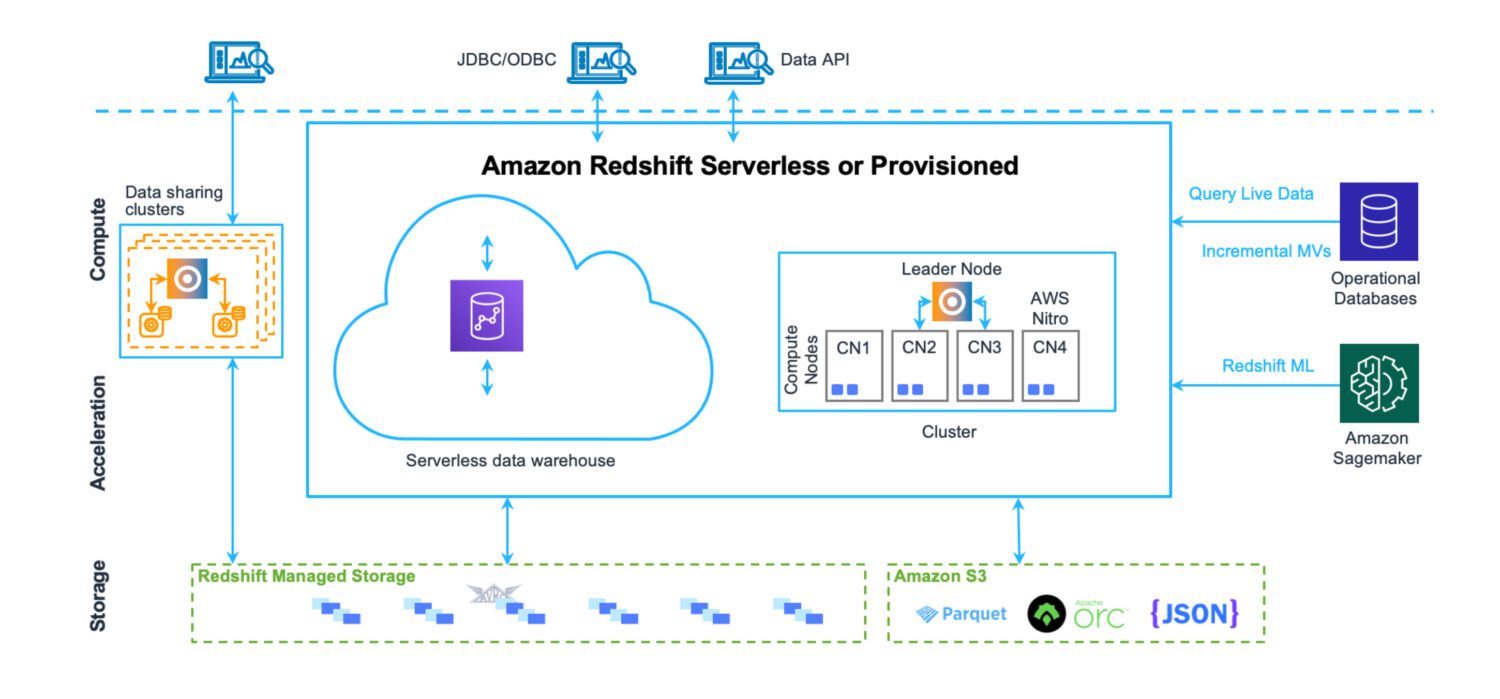
Kilde: aws.amazon.com
Et data warehouse er et sted hvor data lagres på en strukturert måte, som er enkel å laste inn og hente ut. Hensikten er å kjøre et stort antall svært komplekse spørringer og slå sammen mange tabeller via komplekse koblinger. Ulike analyseverktøy er på plass for å beregne forskjellig statistikk fra eksisterende data. Det endelige målet er å utlede fremtidige prognoser og fakta som kan brukes i virksomheten fremover, ved hjelp av eksisterende data.
Redshift er et fullverdig data warehouse-system, med klyngeservere for finjustering og skalering – både horisontalt og vertikalt – og et datalagringssystem som er optimalisert for rask tilbakemelding på komplekse spørringer. Du kan i dag også kjøre Redshift i serverløs modus. Det er ingen filer på S3 eller lignende. Dette er en standard databaseklyngeserver med sitt eget lagringsformat.
Den har verktøy for ytelsesovervåking, sammen med tilpassbare dashbordberegninger du kan bruke for å finjustere ytelsen for ditt bruksområde. Administrasjonen er også tilgjengelig via egne dashbord. Det krever litt arbeid å forstå alle mulige funksjoner og innstillinger, og hvordan de påvirker klyngen. Men det er uansett ikke like komplisert som administrasjonen av Oracle-servere i lokale løsninger.
Selv om det finnes ulike AWS-begrensninger i Redshift som setter noen grenser for hvordan den skal brukes til daglig (for eksempel harde grenser for antall samtidige aktive brukere eller økter i en databaseklynge), hjelper det faktum at operasjoner utføres raskt, til en viss grad med å omgå disse begrensningene.

Fordeler og ulemper
Fordeler:
- En skybasert datavarehustjeneste fra AWS som er enkel å integrere med andre tjenester.
- Et sentralt sted for lagring, overvåking og innhenting av ulike datakilder fra svært forskjellige kildesystemer.
- Hvis du ønsker et serverløst data warehouse uten infrastruktur for å vedlikeholde det, er det nå mulig.
- Optimalisert for analyser og rapportering med høy ytelse. I motsetning til en data lake-løsning er det en sterk relasjonsdatamodell for lagring av alle innkommende data.
- Redshift sin databasemotor har sin opprinnelse i PostgreSQL, som sikrer høy kompatibilitet med andre databasesystemer.
- Nyttige kommandoer som COPY og UNLOAD for å laste inn og ut data fra S3-bøtter.
Ulemper:
- Redshift støtter ikke et stort antall samtidige aktive økter. Øktene vil bli satt i kø og behandlet sekvensielt. Selv om dette kanskje ikke er et problem i de fleste tilfeller, da operasjonene går raskt, er det en begrensende faktor i systemer med mange aktive brukere.
- Selv om Redshift støtter mange funksjoner fra tidligere kjente Oracle-systemer, er det fortsatt ikke på samme nivå. Noen av de forventede funksjonene er kanskje ikke tilgjengelige (som DB-utløsere). Eller Redshift støtter dem i en begrenset form (som materialiserte visninger).
- Når du trenger mer avanserte, tilpassede databehandlingsjobber, må du bygge dem fra bunnen av. Ofte ved å bruke Python eller Javascript. Det er ikke like enkelt som PL/SQL i tilfellet med Oracle-systemet, der selv funksjoner og prosedyrer bruker et språk som ligner veldig på SQL-spørringer.
Formål og praktisk anvendelse
Redshift kan være ditt sentrale lagringssted for alle de forskjellige datakildene som tidligere lå utenfor skyen. Det er en god erstatning for tidligere Oracle data warehouse-løsninger. Siden det også er en relasjonsdatabase, er migrasjonen fra Oracle ganske enkel.
Hvis du har eksisterende data warehouse-løsninger mange steder som ikke er enhetlige når det gjelder tilnærming, struktur eller et forhåndsdefinert sett med vanlige prosesser som skal kjøres over dataene, er Redshift et godt valg.
Det vil gi deg muligheten til å slå sammen alle de forskjellige data warehouse-systemene fra forskjellige steder og land under ett tak. Du kan fortsatt dele dem opp per land slik at dataene er trygge og bare tilgjengelige for de som trenger dem. Samtidig gir det deg en enhetlig lagerløsning som dekker alle bedriftens data.
Et annet scenario kan være å bygge en data warehouse-plattform med omfattende støtte for selvbetjening. Det kan forstås som et sett med prosesser som enkeltbrukere kan bygge. Samtidig er de aldri en del av den felles plattformløsningen. Slike tjenester vil bare være tilgjengelige for skaperen eller gruppen som er definert av den opprettede. De vil ikke påvirke resten av brukerne på noen måte.
Se vår sammenligning mellom Data Lake og Data Warehouse.
Lakehouse med Databricks på AWS
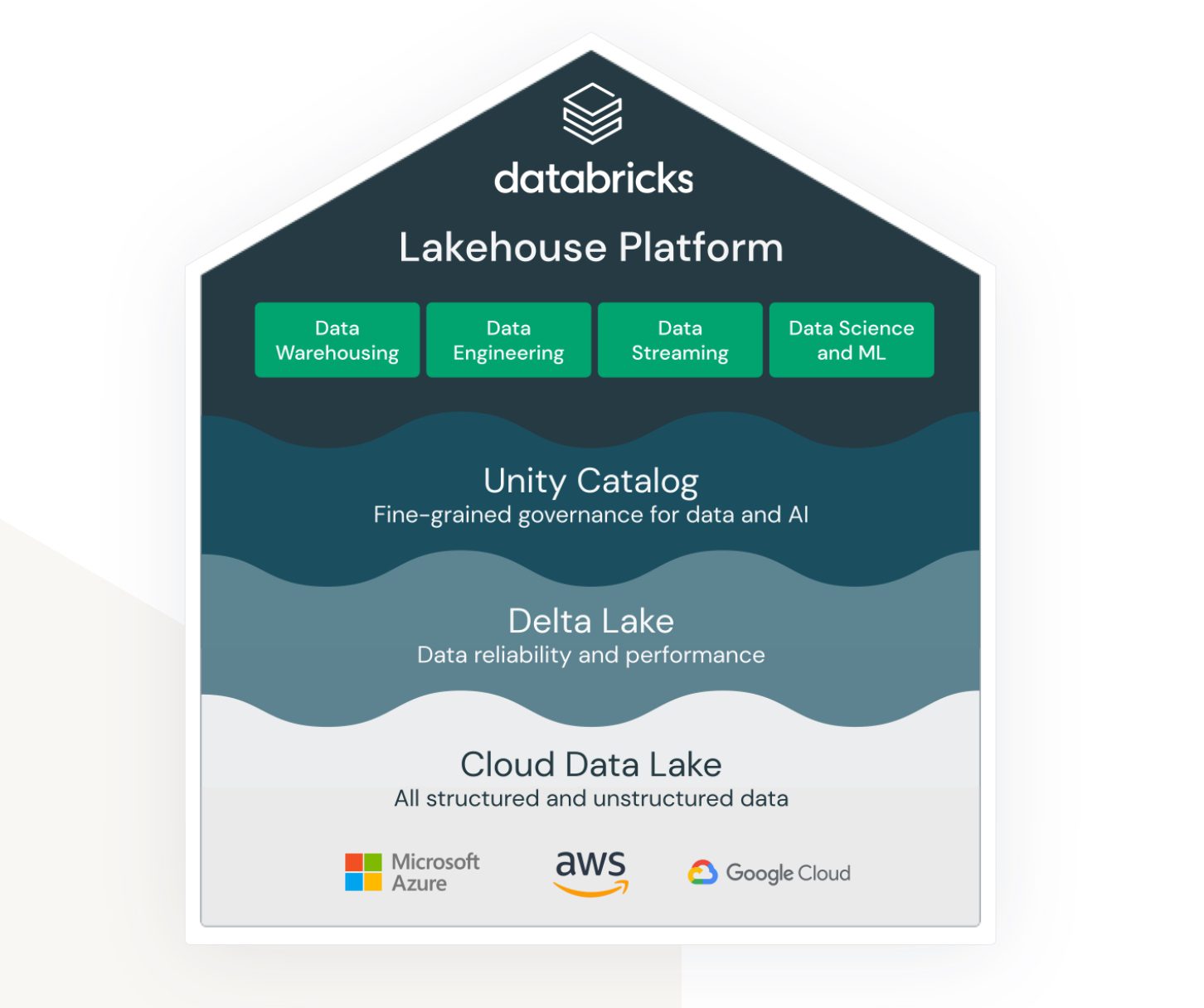
Kilde: databricks.com
Lakehouse er et begrep som er knyttet til Databricks-tjenesten. Selv om det ikke er en skybasert tjeneste fra AWS, fungerer den godt i AWS-økosystemet og gir ulike alternativer for hvordan du kobler til og integrerer den med andre AWS-tjenester.
Databricks har som mål å koble sammen (tidligere) ulike områder:
- En løsning for data lake-lagring av ustrukturerte, semistrukturerte og strukturerte data.
- En løsning for data warehouse-strukturert og raskt tilgjengelig spørringsdata (også kalt Delta Lake).
- En løsning som støtter analyse og maskinlæring over data lake-en.
- Datastyring for alle de ovennevnte områdene med sentralisert administrasjon og ferdige verktøy for å støtte produktiviteten for ulike typer utviklere og brukere.
Det er en plattform som dataingeniører, SQL-utviklere og maskinlæringsdataforskere kan bruke samtidig. Hver av gruppene har også et sett med verktøy de kan bruke for å utføre sine oppgaver.
Databricks tar sikte på en universell løsning, og prøver å kombinere fordelene med en data lake og et data warehouse til én løsning. I tillegg gir den verktøy for å teste og kjøre maskinlæringsmodeller direkte over allerede bygde datalagre.

Fordeler og ulemper
Fordeler:
- Databricks er en svært skalerbar dataplattform. Den skalerer avhengig av arbeidsmengden, og gjør det automatisk.
- Det er et samarbeidsmiljø for dataforskere, dataingeniører og forretningsanalytikere. Å ha muligheten til å gjøre alt dette på samme sted og sammen er en stor fordel. Ikke bare fra et organisatorisk perspektiv, men det hjelper også å spare kostnader som ellers er nødvendige for separate miljøer.
- AWS Databricks integreres sømløst med andre AWS-tjenester, som Amazon S3, Amazon Redshift og Amazon EMR. Dette lar brukere enkelt overføre data mellom tjenester og dra nytte av hele spekteret av AWS-skytjenester.
Ulemper:
- Databricks kan være komplisert å sette opp og administrere, særlig for brukere som er nye innen stordata. Det krever et betydelig nivå av teknisk ekspertise for å få mest mulig ut av plattformen.
- Selv om Databricks er kostnadseffektivt med sin betal-som-du-går-prismodell, kan det fortsatt være dyrt for store databehandlingsprosjekter. Kostnadene ved å bruke plattformen kan raskt øke, særlig hvis brukere trenger å skalere opp ressursene.
- Databricks tilbyr en rekke forhåndsbygde verktøy og maler, men dette kan også være en begrensning for brukere som trenger mer tilpasning. Plattformen er kanskje ikke egnet for brukere som krever mer fleksibilitet og kontroll over arbeidsflytene for stordata.
Formål og praktisk anvendelse
AWS Databricks er best egnet for store selskaper med store datamengder. Her kan det dekke kravet om å laste inn og sette sammen ulike datakilder fra eksterne systemer.
Ofte er kravet å levere data i sanntid. Dette betyr at fra det øyeblikket dataene vises i kildesystemet, skal prosessene fange dem opp umiddelbart og behandle og lagre dataene i Databricks med minimal forsinkelse. Hvis forsinkelsen er mer enn ett minutt, regnes det som tilnærmet sanntidsbehandling. Begge scenarioene er ofte mulig med Databricks-plattformen. Dette er hovedsakelig på grunn av det omfattende utvalget av adaptere og sanntidsgrensesnitt som kobles til ulike andre AWS-tjenester.
Databricks kan også enkelt integreres med Informatica ETL-systemer. Når organisasjonssystemet allerede bruker Informatica-økosystemet, er Databricks et godt kompatibelt tillegg til plattformen.
Avsluttende ord
Ettersom datamengdene fortsetter å vokse eksponentielt, er det godt å vite at det finnes løsninger som effektivt kan håndtere det. Det som en gang var et mareritt å administrere og vedlikeholde, krever nå minimalt med administrativt arbeid. Teamet kan fokusere på å skape verdi fra dataene.
Avhengig av dine behov, velg den tjenesten som passer best. Mens AWS Databricks er noe du sannsynligvis må holde deg til etter at valget er tatt, er de andre alternativene mer fleksible, selv om de er mindre kapable, særlig deres serverløse modus. Det er enkelt å migrere til en annen løsning senere.