

MapReduce tilbyr en effektiv, raskere og kostnadseffektiv måte å lage applikasjoner på.
Denne modellen bruker avanserte konsepter som parallell prosessering, datalokalitet, etc., for å gi mange fordeler til programmerere og organisasjoner.
Men det er så mange programmeringsmodeller og rammeverk tilgjengelig på markedet at det blir vanskelig å velge.
Og når det kommer til Big Data, kan du ikke bare velge hva som helst. Du må velge slike teknologier som kan håndtere store databiter.
MapReduce er en flott løsning på det.
I denne artikkelen skal jeg diskutere hva MapReduce egentlig er og hvordan det kan være nyttig.
La oss begynne!
Innholdsfortegnelse
Hva er MapReduce?
MapReduce er en programmeringsmodell eller programvareramme innenfor Apache Hadoop-rammeverket. Den brukes til å lage applikasjoner som er i stand til å behandle massive data parallelt på tusenvis av noder (kalt klynger eller rutenett) med feiltoleranse og pålitelighet.
Denne databehandlingen skjer i en database eller et filsystem der dataene er lagret. MapReduce kan fungere med et Hadoop-filsystem (HDFS) for å få tilgang til og administrere store datavolumer.
Dette rammeverket ble introdusert i 2004 av Google og er populært av Apache Hadoop. Det er et behandlingslag eller en motor i Hadoop som kjører MapReduce-programmer utviklet på forskjellige språk, inkludert Java, C++, Python og Ruby.
MapReduce-programmene i cloud computing kjører parallelt, og er derfor egnet for å utføre dataanalyse i stor skala.
MapReduce tar sikte på å dele opp en oppgave i mindre, flere oppgaver ved å bruke funksjonene «kart» og «reduser». Den vil kartlegge hver oppgave og deretter redusere den til flere tilsvarende oppgaver, noe som resulterer i mindre prosessorkraft og overhead på klyngenettverket.
Eksempel: Tenk deg at du lager et måltid til et hus fullt av gjester. Så hvis du prøver å tilberede alle rettene og gjøre alle prosessene selv, vil det bli hektisk og tidkrevende.
Men anta at du involverer noen av dine venner eller kolleger (ikke gjester) for å hjelpe deg med å tilberede måltidet ved å distribuere forskjellige prosesser til en annen person som kan utføre oppgavene samtidig. I så fall vil du tilberede måltidet mye raskere og enklere mens gjestene fortsatt er i huset.
MapReduce fungerer på en lignende måte med distribuerte oppgaver og parallell prosessering for å muliggjøre en raskere og enklere måte å fullføre en gitt oppgave.
Apache Hadoop lar programmerere bruke MapReduce til å utføre modeller på store distribuerte datasett og bruke avansert maskinlæring og statistiske teknikker for å finne mønstre, lage spådommer, oppdage korrelasjoner og mer.
Funksjoner i MapReduce
Noen av hovedfunksjonene til MapReduce er:
- Brukergrensesnitt: Du vil få et intuitivt brukergrensesnitt som gir rimelige detaljer om hvert rammeaspekt. Det vil hjelpe deg med å konfigurere, bruke og justere oppgavene dine sømløst.

- Nyttelast: Applikasjoner bruker Mapper- og Reducer-grensesnitt for å aktivere kartet og redusere funksjoner. Mapper tilordner inngangsnøkkelverdi-par til mellomliggende nøkkelverdi-par. Reducer brukes til å redusere mellomliggende nøkkel-verdi-par som deler en nøkkel til andre mindre verdier. Den utfører tre funksjoner – sortere, blande og redusere.
- Partitioner: Den kontrollerer delingen av de mellomliggende kartutdatatastene.
- Reporter: Det er en funksjon for å rapportere fremgang, oppdatere tellere og angi statusmeldinger.
- Tellere: Det representerer globale tellere som en MapReduce-applikasjon definerer.
- OutputCollector: Denne funksjonen samler inn utdata fra Mapper eller Reducer i stedet for mellomutganger.
- RecordWriter: Den skriver datautdataene eller nøkkelverdiparene til utdatafilen.
- DistributedCache: Den distribuerer effektivt større, skrivebeskyttede filer som er applikasjonsspesifikke.
- Datakomprimering: Applikasjonsskriveren kan komprimere både jobbutdata og mellomkartutdata.
- Dårlig posthopping: Du kan hoppe over flere dårlige poster mens du behandler kartinndataene dine. Denne funksjonen kan kontrolleres gjennom klassen – SkipBadRecords.
- Feilsøking: Du vil få muligheten til å kjøre brukerdefinerte skript og aktivere feilsøking. Hvis en oppgave i MapReduce mislykkes, kan du kjøre feilsøkingsskriptet og finne problemene.
MapReduce Architecture
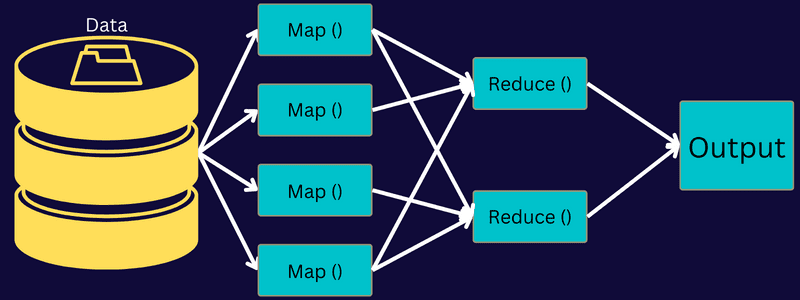
La oss forstå arkitekturen til MapReduce ved å gå dypere inn i komponentene:
- Jobb: En jobb i MapReduce er den faktiske oppgaven MapReduce-klienten ønsker å utføre. Den består av flere mindre oppgaver som kombineres for å danne den endelige oppgaven.
- Job History Server: Det er en demonprosess for å lagre og lagre alle historiske data om en applikasjon eller oppgave, for eksempel logger generert etter eller før utføring av en jobb.
- Klient: En klient (program eller API) bringer en jobb til MapReduce for utførelse eller behandling. I MapReduce kan én eller flere klienter kontinuerlig sende jobber til MapReduce Manager for behandling.
- MapReduce Master: En MapReduce Master deler opp en jobb i flere mindre deler, og sikrer at oppgavene skrider frem samtidig.
- Jobbdeler: Underjobbene eller jobbdelene oppnås ved å dele hovedjobben. De jobbes med og kombineres til slutt for å lage den endelige oppgaven.
- Inndata: Det er datasettet som mates til MapReduce for oppgavebehandling.
- Utdata: Det er det endelige resultatet oppnådd når oppgaven er behandlet.
Så det som egentlig skjer i denne arkitekturen er at klienten sender inn en jobb til MapReduce Master, som deler den inn i mindre, like deler. Dette gjør at jobben kan behandles raskere ettersom mindre oppgaver tar kortere tid å få behandlet i stedet for større oppgaver.
Pass imidlertid på at oppgavene ikke er delt inn i for små oppgaver, for hvis du gjør det, kan det hende du må møte en større overhead med å administrere splittelser og kaste bort betydelig tid på det.
Deretter gjøres jobbdelene tilgjengelige for å fortsette med Kart og Reduser-oppgavene. Videre har oppgavene Kart og Reduser et passende program basert på brukssaken som teamet jobber med. Programmereren utvikler den logikkbaserte koden for å oppfylle kravene.
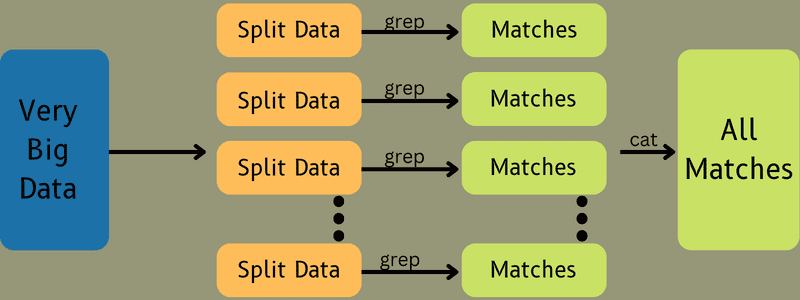
Etter dette mates inndataene til kartoppgaven slik at kartet raskt kan generere utdata som et nøkkelverdi-par. I stedet for å lagre disse dataene på HDFS, brukes en lokal disk til å lagre dataene for å eliminere sjansen for replikering.
Når oppgaven er fullført, kan du kaste utdataene. Derfor vil replikering bli en overkill når du lagrer utdataene på HDFS. Utdata fra hver kartoppgave vil bli matet til reduksjonsoppgaven, og kartutdata vil bli gitt til maskinen som kjører reduksjonsoppgaven.
Deretter vil utdata bli slått sammen og sendt til reduseringsfunksjonen definert av brukeren. Til slutt vil den reduserte utgangen bli lagret på en HDFS.
Dessuten kan prosessen ha flere kart- og reduksjonsoppgaver for databehandling avhengig av sluttmålet. Kart- og reduksjonsalgoritmene er optimalisert for å holde tids- eller romkompleksiteten minimal.
Siden MapReduce først og fremst involverer Map- og Reduce-oppgaver, er det relevant å forstå mer om dem. Så la oss diskutere fasene til MapReduce for å få en klar ide om disse emnene.
Faser av MapReduce
Kart
Inndataene blir kartlagt til utdata- eller nøkkelverdi-parene i denne fasen. Her kan nøkkelen referere til ID-en til en adresse, mens verdien kan være den faktiske verdien til den adressen.
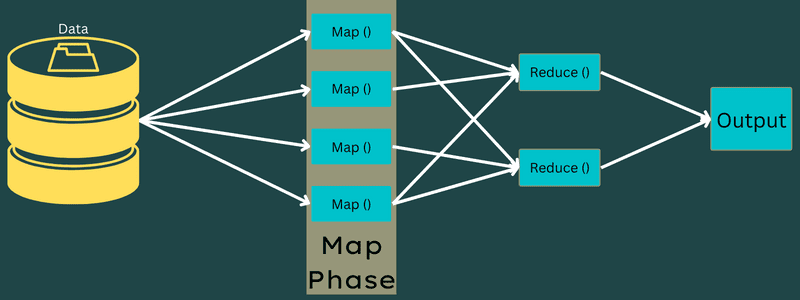
Det er bare én men to oppgaver i denne fasen – oppdelinger og kartlegging. Splitter betyr underdelene eller jobbdelene delt fra hovedjobben. Disse kalles også input splits. Så en inngangsdeling kan kalles en inngangsdel som forbrukes av et kart.
Deretter finner kartleggingsoppgaven sted. Det regnes som den første fasen mens du kjører et kartreduseringsprogram. Her vil data i hver splitt bli sendt til en kartfunksjon for å behandle og generere utdata.
Funksjonen – Map() kjøres i minnelageret på inndatanøkkelverdi-parene, og genererer et mellomliggende nøkkelverdi-par. Dette nye nøkkelverdi-paret vil fungere som input som skal mates til Reduce()- eller Reducer-funksjonen.
Redusere
De mellomliggende nøkkel-verdi-parene oppnådd i kartleggingsfasen fungerer som input for Reduser-funksjonen eller Reduser. I likhet med kartleggingsfasen er to oppgaver involvert – blande og redusere.
Så de oppnådde nøkkelverdi-parene sorteres og stokkes for å bli matet til reduksjonsenheten. Deretter grupperer eller aggregerer Reducer dataene i henhold til nøkkelverdi-paret basert på reduksjonsalgoritmen som utvikleren har skrevet.
Her kombineres verdiene fra stokkingsfasen for å returnere en utgangsverdi. Denne fasen oppsummerer hele datasettet.
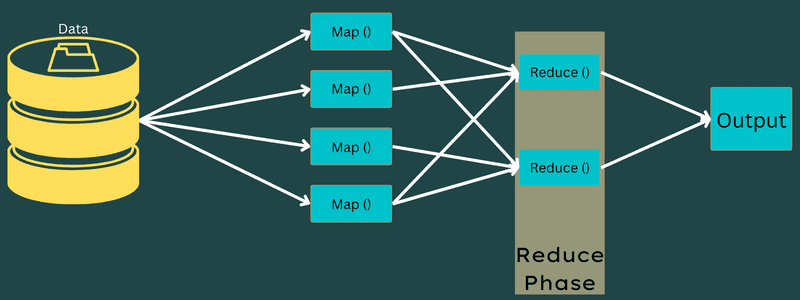
Nå kontrolleres hele prosessen med å utføre kart- og reduksjonsoppgaver av noen enheter. Disse er:
- Job Tracker: Med enkle ord fungerer en jobbsporer som en mester som er ansvarlig for å utføre en innsendt jobb fullstendig. Jobbsporingen administrerer alle jobbene og ressursene på tvers av en klynge. I tillegg planlegger jobbsporingen hvert kart som legges til på oppgavesporingen som kjører på en bestemt datanode.
- Flere oppgavesporere: Med enkle ord fungerer flere oppgavesporere som slaver som utfører oppgaven etter instruksjonene fra Job Tracker. En oppgavesporing er distribuert på hver node separat i klyngen som utfører kart- og reduksjonsoppgavene.
Det fungerer fordi en jobb vil bli delt inn i flere oppgaver som vil kjøre på forskjellige datanoder fra en klynge. Job Tracker er ansvarlig for å koordinere oppgaven ved å planlegge oppgavene og kjøre dem på flere datanoder. Deretter utfører Task Tracker som sitter på hver datanode deler av jobben og ser etter hver oppgave.
Videre sender Task Trackers fremdriftsrapporter til jobbsporeren. Oppgavesporingen sender også med jevne mellomrom et «hjerteslag»-signal til jobbsporingen og varsler dem om systemstatusen. I tilfelle feil, er en jobbsporer i stand til å omplanlegge jobben på en annen oppgavesporer.
Utdatafase: Når du kommer til denne fasen, vil du få de siste nøkkelverdi-parene generert fra Reducer. Du kan bruke en utdataformater til å oversette nøkkelverdi-parene og skrive dem til en fil ved hjelp av en plateskriver.
Hvorfor bruke MapReduce?
Her er noen av fordelene med MapReduce, og forklarer grunnene til at du må bruke den i big data-applikasjonene dine:
Parallell behandling
Du kan dele opp en jobb i forskjellige noder der hver node samtidig håndterer en del av denne jobben i MapReduce. Så å dele større oppgaver i mindre reduserer kompleksiteten. Siden forskjellige oppgaver kjører parallelt i forskjellige maskiner i stedet for en enkelt maskin, tar det betydelig mindre tid å behandle dataene.
Datalokalitet
I MapReduce kan du flytte prosessorenheten til data, ikke omvendt.
På tradisjonelle måter ble dataene brakt til behandlingsenheten for behandling. Men med den raske veksten av data begynte denne prosessen å by på mange utfordringer. Noen av dem var høyere kostnader, mer tidkrevende, belastning av masternoden, hyppige feil og redusert nettverksytelse.
Men MapReduce hjelper til med å overvinne disse problemene ved å følge en omvendt tilnærming – bringe en prosesseringsenhet til data. På denne måten blir dataene fordelt mellom forskjellige noder der hver node kan behandle en del av de lagrede dataene.
Som et resultat gir det kostnadseffektivitet og reduserer behandlingstiden siden hver node fungerer parallelt med dens tilsvarende datadel. I tillegg, siden hver node behandler en del av disse dataene, vil ingen node bli overbelastet.
Sikkerhet

MapReduce-modellen gir høyere sikkerhet. Det bidrar til å beskytte applikasjonen din mot uautoriserte data samtidig som den forbedrer klyngesikkerheten.
Skalerbarhet og fleksibilitet
MapReduce er et svært skalerbart rammeverk. Den lar deg kjøre applikasjoner fra flere maskiner ved å bruke data med tusenvis av terabyte. Den tilbyr også fleksibiliteten til å behandle data som kan være strukturert, semi-strukturert eller ustrukturert og av alle formater eller størrelser.
Enkelhet
Du kan skrive MapReduce-programmer i et hvilket som helst programmeringsspråk som Java, R, Perl, Python og mer. Derfor er det enkelt for alle å lære og skrive programmer samtidig som de sikrer at databehandlingskravene oppfylles.
Bruk tilfeller av MapReduce
- Fulltekstindeksering: MapReduce brukes til å utføre fulltekstindeksering. Dens Mapper kan kartlegge hvert ord eller uttrykk i et enkelt dokument. Og Reducer brukes til å skrive alle de tilordnede elementene til en indeks.
- Beregning av PageRank: Google bruker MapReduce for å beregne PageRank.
- Logganalyse: MapReduce kan analysere loggfiler. Den kan dele opp en stor loggfil i ulike deler eller dele opp mens kartleggeren søker etter tilgjengelige nettsider.
Et nøkkel-verdi-par vil bli matet til reduseringen hvis en nettside blir oppdaget i loggen. Her vil nettsiden være nøkkelen, og indeksen «1» er verdien. Etter å ha gitt ut et nøkkelverdi-par til Reducer, vil ulike nettsider bli samlet. Det endelige resultatet er det totale antallet treff for hver nettside.

- Omvendt Web-Link Graph: Rammeverket finner også bruk i Reverse Web-Link Graph. Her gir Map() URL-målet og kilden og tar innspill fra kilden eller nettsiden.
Deretter samler Reduce() listen over hver kilde-URL som er knyttet til mål-URLen. Til slutt gir den ut kildene og målet.
- Ordtelling: MapReduce brukes til å telle hvor mange ganger et ord forekommer i et gitt dokument.
- Global oppvarming: Organisasjoner, myndigheter og selskaper kan bruke MapReduce til å løse problemer med global oppvarming.
Det kan for eksempel være lurt å vite om havets økte temperaturnivå på grunn av global oppvarming. For dette kan du samle tusenvis av data over hele verden. Dataene kan være høy temperatur, lav temperatur, breddegrad, lengdegrad, dato, klokkeslett, etc. dette vil ta flere kart og redusere oppgaver for å beregne output ved hjelp av MapReduce.
- Legemiddelforsøk: Tradisjonelt har dataforskere og matematikere jobbet sammen for å formulere et nytt medikament som kan bekjempe en sykdom. Med spredning av algoritmer og MapReduce kan IT-avdelinger i organisasjoner enkelt takle problemer som kun ble håndtert av Supercomputers, Ph.D. forskere, etc. Nå kan du inspisere effektiviteten til et medikament for en gruppe pasienter.
- Andre applikasjoner: MapReduce kan behandle selv store data som ellers ikke passer inn i en relasjonsdatabase. Den bruker også datavitenskapelige verktøy og lar dem kjøre over forskjellige, distribuerte datasett, noe som tidligere bare var mulig på en enkelt datamaskin.
Som et resultat av MapReduces robusthet og enkelhet, finner den applikasjoner i militæret, næringslivet, vitenskapen, etc.
Konklusjon
MapReduce kan vise seg å være et gjennombrudd innen teknologi. Det er ikke bare en raskere og enklere prosess, men også kostnadseffektiv og mindre tidkrevende. Gitt fordelene og den økende bruken, vil den sannsynligvis være vitne til høyere bruk på tvers av bransjer og organisasjoner.
Du kan også utforske noen av de beste ressursene for å lære Big Data og Hadoop.