I dagens digitale verden genereres det utallige dataposter daglig. Disse omfatter alt fra finansielle transaksjoner og bestillinger til informasjon fra bilens sensorer. For å håndtere disse kontinuerlige datastrømmene i sanntid og pålitelig overføre hendelsesdata mellom forskjellige systemer, er Apache Kafka et kraftfullt verktøy.
Apache Kafka er en åpen kildekode-plattform for datastrømming som er i stand til å prosessere over en million meldinger per sekund. Utover sin imponerende hastighet, tilbyr Apache Kafka en høy grad av skalerbarhet, tilgjengelighet, lav forsinkelse og sikrer permanent lagring av data.
Store selskaper som LinkedIn, Uber og Netflix bruker Apache Kafka for sanntidsdatabehandling og datastrømming. Den letteste måten å begynne å utforske Apache Kafka er ved å sette den opp lokalt på din egen maskin. Dette gir deg muligheten til å se Apache Kafka-serveren i praksis og å produsere og konsumere meldinger.
Gjennom praktisk erfaring med å starte serveren, konfigurere emner (topics) og skrive Java-kode med Kafka-klienten, vil du være godt forberedt til å bruke Apache Kafka for dine egne databehandlingsbehov.
Hvordan laste ned Apache Kafka på din lokale datamaskin
Du kan laste ned den siste versjonen av Apache Kafka fra den offisielle nedlastingssiden. Den nedlastede filen vil være i .tgz-format. Etter nedlasting, må du pakke ut filen.
Hvis du bruker Linux, åpne terminalen. Naviger til mappen hvor du lagret den komprimerte Apache Kafka-filen. Kjør følgende kommando:
tar -xzvf kafka_2.13-3.5.0.tgz
Når kommandoen er fullført, vil en ny mappe med navn kafka_2.13-3.5.0 opprettes. Gå inn i denne mappen med:
cd kafka_2.13-3.5.0
Du kan nå se innholdet i mappen med `ls`-kommandoen.
For Windows-brukere er prosessen den samme. Hvis `tar`-kommandoen ikke er tilgjengelig, kan du bruke et tredjepartsverktøy som WinZip for å pakke ut arkivet.
Slik starter du Apache Kafka lokalt
Etter at Apache Kafka er lastet ned og pakket ut, er du klar for å starte den. Det kreves ingen installasjon. Du kan starte den direkte via kommandolinjen eller terminalen.
Før du begynner, forsikre deg om at du har Java 8 eller nyere installert på maskinen din. Apache Kafka krever en fungerende Java-installasjon.
#1. Start Apache Zookeeper-serveren
Det første skrittet er å starte Apache Zookeeper. Den følger med i det nedlastede arkivet. Zookeeper er en tjeneste som er ansvarlig for å håndtere konfigurasjon og synkronisering for andre tjenester.
Gå inn i katalogen hvor du pakket ut arkivet, og kjør følgende kommando:
For Linux-brukere:
bin/zookeeper-server-start.sh config/zookeeper.properties
For Windows-brukere:
bin/windows/zookeeper-server-start.bat config/zookeeper.properties
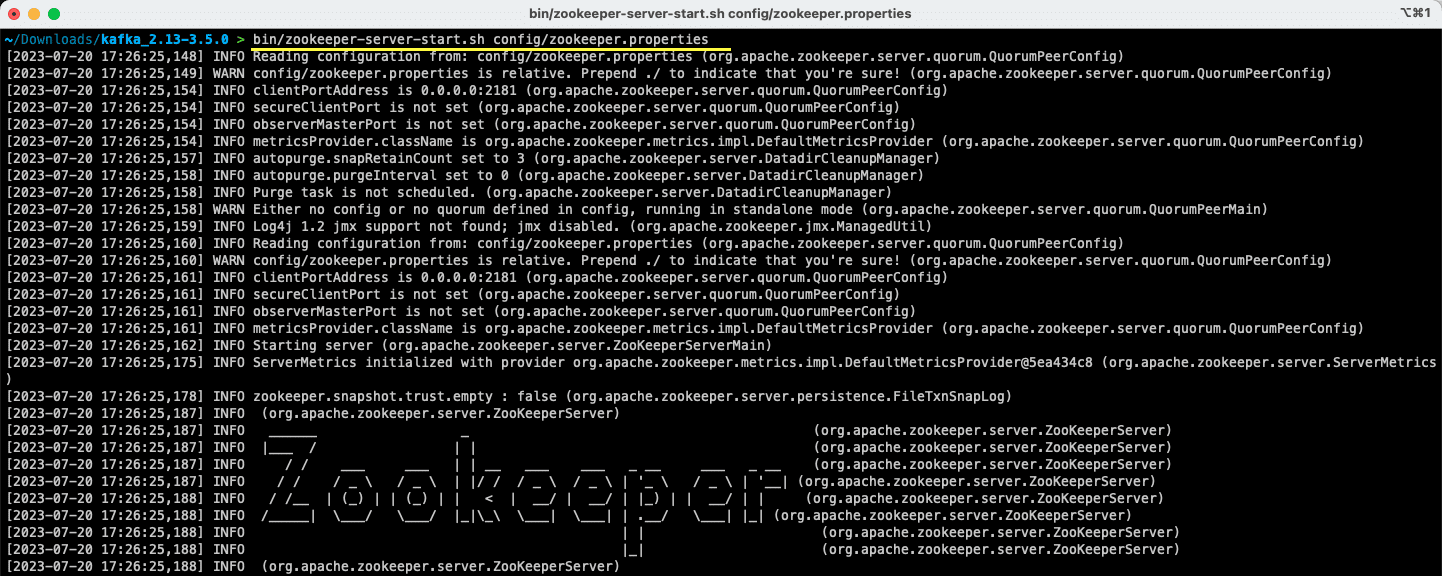
Filen `zookeeper.properties` inneholder konfigurasjonen for å kjøre Apache Zookeeper. Du kan endre egenskaper som den lokale mappen for datalagring og porten serveren skal operere på.
#2. Start Apache Kafka-serveren
Nå som Apache Zookeeper-serveren kjører, er det tid for å starte Apache Kafka-serveren.
Åpne et nytt terminal- eller kommandovindu og naviger til mappen hvor de utpakkede filene ligger. Deretter kan du starte Apache Kafka-serveren med kommandoen nedenfor:
For Linux-brukere:
bin/kafka-server-start.sh config/server.properties
For Windows-brukere:
bin/windows/kafka-server-start.bat config/server.properties
Apache Kafka-serveren er nå i gang. Hvis du ønsker å endre standardkonfigurasjonen, kan du gjøre det i filen `server.properties`. De ulike verdiene er beskrevet i den offisielle dokumentasjonen.
Slik bruker du Apache Kafka lokalt
Du er nå klar til å bruke Apache Kafka lokalt for å produsere og konsumere meldinger. Med både Apache Zookeeper- og Apache Kafka-serverne oppe og går, la oss se hvordan du kan opprette ditt første emne (topic), produsere din første melding og konsumere den.
Hvordan oppretter du et emne i Apache Kafka?
Før vi oppretter vårt første emne, la oss se på hva et emne faktisk er. I Apache Kafka er et emne en logisk dataenhet som brukes for datastrømming. Tenk på det som en kanal der data transporteres fra én komponent til en annen.
Et emne støtter flere produsenter og flere konsumenter – det betyr at mer enn ett system kan skrive til og lese fra et emne. I motsetning til andre meldingssystemer, kan en melding i et emne konsumeres mer enn én gang. Du kan også konfigurere hvor lenge meldingene skal lagres.
La oss se på et eksempel der et system (produsent) produserer data om banktransaksjoner. Et annet system (konsument) bruker disse dataene og sender ut en varsel til brukeren. For å muliggjøre denne kommunikasjonen er det nødvendig med et emne.
Åpne et nytt terminal- eller kommandovindu, og naviger til mappen hvor du pakket ut arkivet. Følgende kommando vil opprette et emne med navn `transaksjoner`:
For Linux-brukere:
bin/kafka-topics.sh --create --topic transactions --bootstrap-server localhost:9092
For Windows-brukere:
bin/windows/kafka-topics.bat --create --topic transactions --bootstrap-server localhost:9092
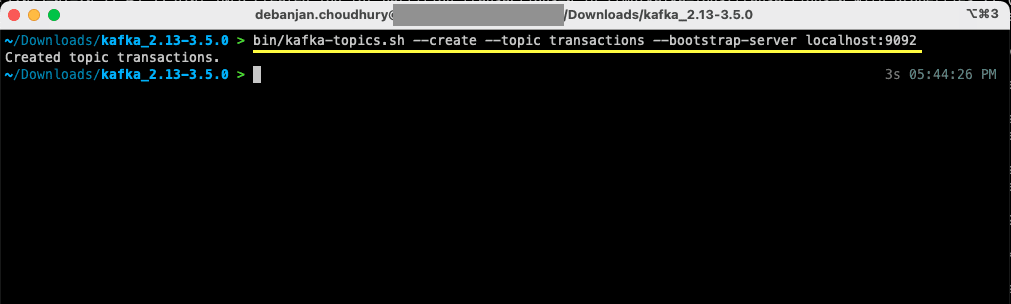
Du har nå opprettet ditt første emne, og du er klar til å begynne å produsere og konsumere meldinger.
Hvordan produsere en melding til Apache Kafka?
Med Apache Kafka-emnet klart, kan du nå produsere din første melding. Åpne et nytt terminal- eller kommandovindu, eller bruk det samme vinduet du brukte til å opprette emnet. Sørg for at du er i riktig mappe hvor du pakket ut arkivet. Du kan bruke kommandolinjen til å produsere en melding til emnet med følgende kommando:
For Linux-brukere:
bin/kafka-console-producer.sh --topic transactions --bootstrap-server localhost:9092
For Windows-brukere:
bin/windows/kafka-console-producer.bat --topic transactions --bootstrap-server localhost:9092
Etter at du har kjørt kommandoen, vil terminalen vente på input. Skriv inn din første melding og trykk Enter.
> This is a transactional record for $100
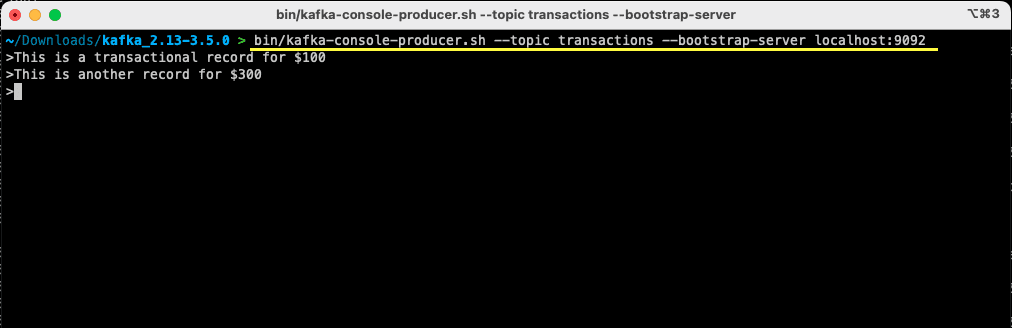
Du har produsert din første melding til Apache Kafka lokalt. Nå er du klar til å konsumere denne meldingen.
Hvordan konsumere en melding fra Apache Kafka?
Forutsatt at emnet er opprettet og du har produsert en melding til Kafka-emnet, kan du nå konsumere den meldingen.
Apache Kafka lar deg knytte flere konsumenter til samme emne. Hver konsument kan være en del av en konsumentgruppe – en logisk identifikator. Hvis du for eksempel har to tjenester som trenger å konsumere de samme dataene, kan de ha forskjellige konsumentgrupper.
Men hvis du har to instanser av samme tjeneste, vil du unngå å konsumere og prosessere den samme meldingen to ganger. I det tilfellet vil begge instansene tilhøre samme konsumentgruppe.
I terminal- eller kommandovinduet, sørg for at du er i riktig mappe. Bruk følgende kommando for å starte konsumenten:
For Linux-brukere:
bin/kafka-console-consumer.sh --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer
For Windows-brukere:
bin/windows/kafka-console-consumer.bat --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer

Du vil se meldingen du tidligere produserte, vises i terminalen. Du har nå brukt Apache Kafka til å konsumere din første melding.
`kafka-console-consumer`-kommandoen aksepterer flere argumenter. La oss gå gjennom betydningen av hver enkelt:
- `–topic` spesifiserer emnet som skal konsumeres.
- `–from-beginning` instruerer konsollkonsumenten til å lese meldinger fra starten av emnet.
- `–bootstrap-server` angir adressen til Apache Kafka-serveren.
- `–group` lar deg spesifisere konsumentgruppen.
- Hvis en konsumentgruppe ikke angis, vil den genereres automatisk.
Når konsollkonsumenten kjører, kan du prøve å produsere nye meldinger. Du vil se at de blir konsumert og vises i terminalen.
Nå som du har opprettet et emne og vellykket produsert og konsumert meldinger, la oss se hvordan du integrerer dette med en Java-applikasjon.
Hvordan lage Apache Kafka produsent og konsument med Java
Før du begynner, forsikre deg om at du har Java 8+ installert lokalt. Apache Kafka tilbyr sitt eget klientbibliotek som gjør tilkoblingen enkel. Hvis du bruker Maven for å håndtere avhengighetene dine, legger du til følgende avhengighet i `pom.xml`:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.5.0</version>
</dependency>
Du kan også laste ned biblioteket fra Maven-depotet og legge det til i Java-klassebanen.
Når biblioteket er tilgjengelig, åpner du et valgfritt kodeverktøy. La oss se hvordan du kan sette opp produsent og konsument med Java.
Lag en Apache Kafka Java-produsent
Med Kafka-klientbiblioteket på plass, er du klar til å lage din Kafka-produsent.
La oss opprette en klasse kalt `SimpleProducer.java`. Denne klassen skal være ansvarlig for å produsere meldinger til emnet du har opprettet tidligere. I denne klassen vil du opprette en instans av `org.apache.kafka.clients.producer.KafkaProducer`. Du vil deretter bruke denne produsenten til å sende meldingene.
For å opprette Kafka-produsenten, trenger du adressen og porten til Apache Kafka-serveren. Siden du kjører den lokalt, vil adressen være `localhost`. Gitt at du ikke har endret standardporten, vil den være `9092`. Se koden nedenfor for å lage produsenten:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
}
Du vil se at det er tre egenskaper som settes. La oss se raskt på hver enkelt:
- `BOOTSTRAP_SERVERS_CONFIG` lar deg definere hvor Apache Kafka-serveren kjører.
- `KEY_SERIALIZER_CLASS_CONFIG` forteller produsenten hvilket format som skal brukes for å sende meldingsnøklene.
- `VALUE_SERIALIZER_CLASS_CONFIG` definerer formatet for å sende den faktiske meldingen.
Siden du skal sende tekstmeldinger, er begge de to siste egenskapene satt til å bruke `StringSerializer.class`.
For å faktisk sende en melding til emnet, må du bruke `producer.send()`-metoden som tar en `ProducerRecord`. Koden nedenfor viser en metode som sender en melding til emnet og skriver ut svaret sammen med meldingsforskyvningen (offset).
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
Med all koden på plass, kan du nå sende meldinger til emnet. Du kan bruke en hovedmetode for å teste dette, som vist i koden nedenfor:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
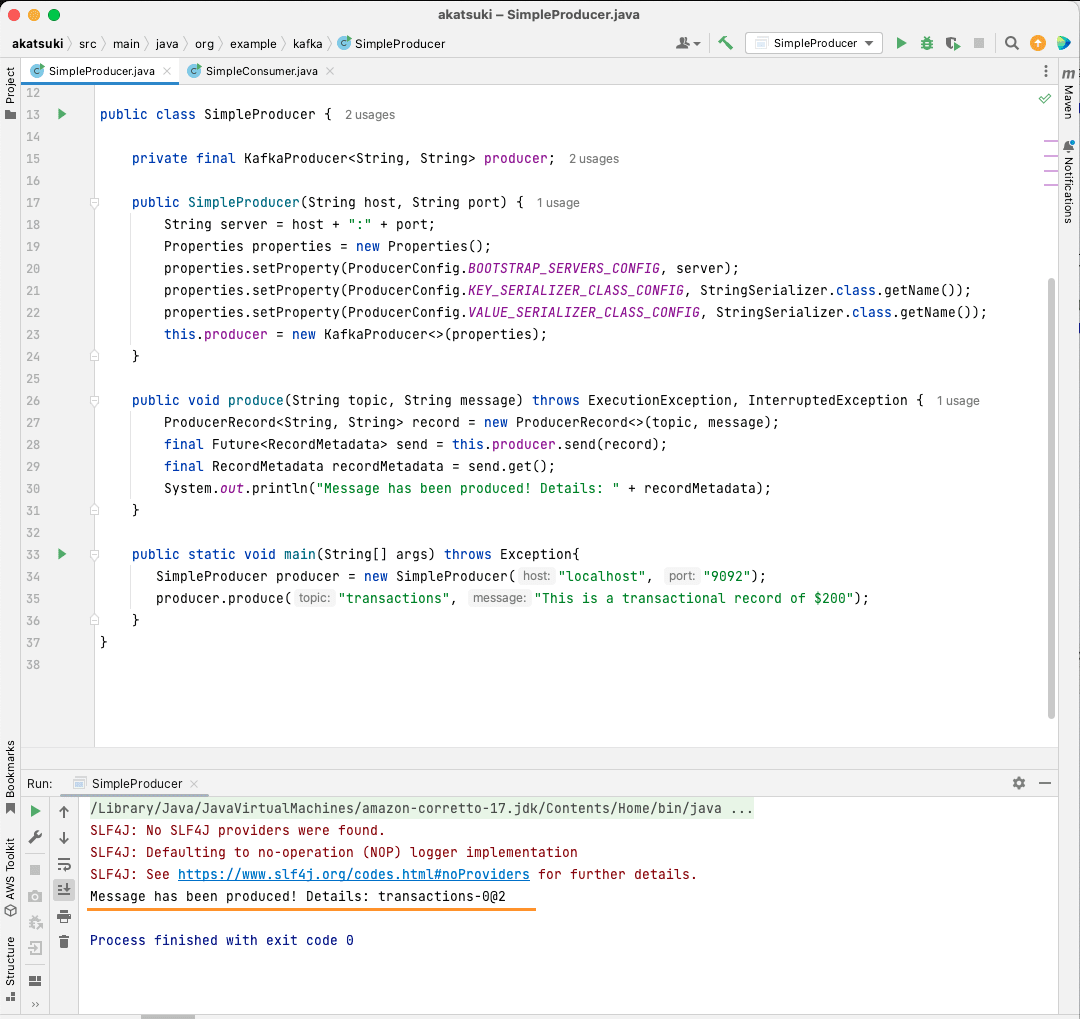
public static void main(String[] args) throws Exception{
SimpleProducer producer = new SimpleProducer("localhost", "9092");
producer.produce("transactions", "This is a transactional record of $200");
}
}
I denne koden oppretter du en `SimpleProducer` som kobler seg til Apache Kafka-serveren din lokalt. Den bruker internt `KafkaProducer` for å produsere tekstmeldinger til emnet ditt.
Lag en Apache Kafka Java-konsument
Det er på tide å lage en Apache Kafka-konsument ved hjelp av Java-klienten. Opprett en klasse kalt `SimpleConsumer.java`. Deretter oppretter du en konstruktør for klassen som initialiserer `org.apache.kafka.clients.consumer.KafkaConsumer`. For å opprette konsumenten trenger du adressen og porten der Apache Kafka-serveren kjører. I tillegg trenger du konsumentgruppen og emnet du ønsker å konsumere fra. Bruk kodebiten nedenfor:
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
}
I likhet med Kafka-produsenten, tar Kafka-konsumenten også et `Properties`-objekt. La oss se på de forskjellige egenskapene:
- `BOOTSTRAP_SERVERS_CONFIG` forteller konsumenten hvor Apache Kafka-serveren kjører.
- `GROUP_ID_CONFIG` spesifiserer konsumentgruppen.
- `AUTO_OFFSET_RESET_CONFIG` angir hvor konsumenten skal starte å lese meldinger fra.
- `KEY_DESERIALIZER_CLASS_CONFIG` forteller konsumenten typen på meldingsnøkkelen.
- `VALUE_DESERIALIZER_CLASS_CONFIG` forteller konsumenten typen på den faktiske meldingen.
Siden du i dette eksemplet bruker tekstmeldinger, er de to siste egenskapene satt til `StringDeserializer.class`.
Nå skal du konsumere meldingene fra emnet. For å holde det enkelt, vil du skrive ut meldingen til konsollen når den konsumeres. La oss se hvordan du kan gjøre dette med koden nedenfor:
private boolean keepConsuming = true;
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
Denne koden vil kontinuerlig spørre emnet. Når en konsumentpost mottas, vil meldingen skrives ut. Test konsumenten din i praksis med en hovedmetode. Dette vil starte et Java-program som fortsetter å konsumere emnet og skrive ut meldingene. Stopp Java-applikasjonen for å avslutte konsumenten.
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
public static void main(String[] args) {
SimpleConsumer simpleConsumer = new SimpleConsumer("localhost", "9092", "transactions-consumer", "transactions");
simpleConsumer.consume();
}
}
Når du kjører denne koden, vil du se at den ikke bare konsumerer meldingen som er produsert av Java-produsenten, men også de du har produsert med konsollprodusenten. Dette er fordi `AUTO_OFFSET_RESET_CONFIG` er satt til `earliest`.
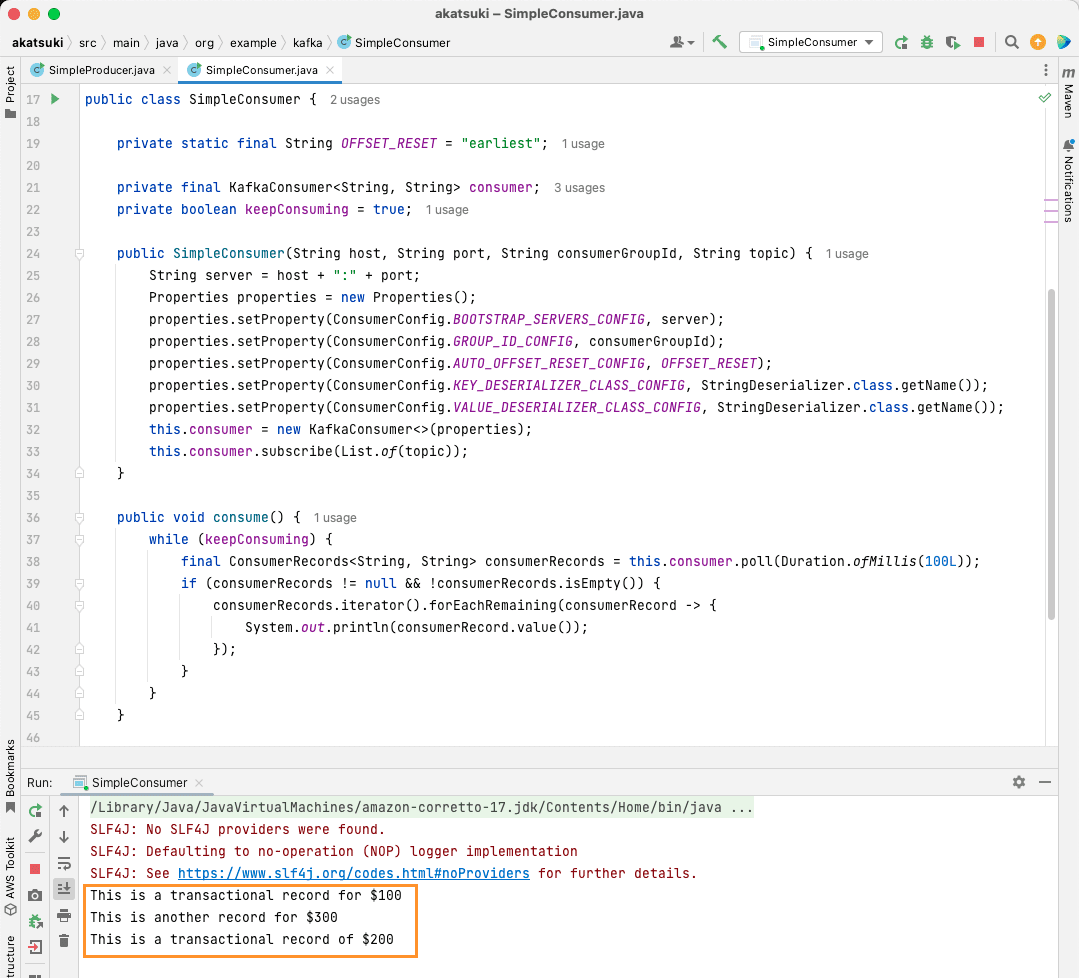
Når `SimpleConsumer` kjører, kan du bruke konsollprodusenten eller `SimpleProducer`-applikasjonen til å produsere flere meldinger til emnet. Du vil se at de blir konsumert og skrevet ut i konsollen.
Oppfyll alle dine databehov med Apache Kafka
Apache Kafka lar deg enkelt håndtere alle dine databehandlingsbehov. Med et Apache Kafka-oppsett lokalt, kan du utforske alle funksjonene Kafka tilbyr. I tillegg lar den offisielle Java-klienten deg effektivt skrive, koble til og kommunisere med Apache Kafka-serveren din.
Apache Kafka er et allsidig, skalerbart og høytytende system for datastrømming, og det kan være en «game changer» for deg. Du kan bruke den i lokal utvikling eller integrere den i dine produksjonssystemer. Akkurat som det er enkelt å sette den opp lokalt, er det heller ikke en stor oppgave å konfigurere Apache Kafka for større applikasjoner.
Hvis du ser etter plattformer for datastrømming, kan du se på de beste strømmeplattformene for sanntidsanalyse og -behandling.