Du har sikkert støtt på begrepet ICMP, og dersom du har et visst teknisk innsyn, er du antagelig kjent med at det relateres til internett.
ICMP er i virkeligheten en protokoll, på samme måte som IP, TCP og UDP (som vi har omtalt tidligere), og spiller en sentral rolle for at internettilkoblinger skal fungere optimalt.
ICMP er særlig viktig for å oppdage og håndtere tilkoblingsproblemer. La oss ikke røpe for mye med det samme. Les videre for å forstå hva ICMP er og hvordan den bidrar til å opprettholde stabile og velfungerende tilkoblinger.

Hva er ICMP?
Internet Control Message Protocol, ofte referert til med akronymet ICMP, er en fundamental protokoll for å diagnostisere problemer knyttet til nettverkstilkoblinger.
Protokollen benyttes av et mangfold av nettverksenheter, deriblant rutere, modem og servere, for å informere andre enheter i nettverket om mulige tilkoblingsutfordringer.
Som nevnt er ICMP en protokoll på linje med TCP og UDP. Men i motsetning til disse to, anvendes ikke ICMP primært for å overføre data mellom systemer. Den er heller ikke vanlig i sluttbrukerapplikasjoner, med mindre det dreier seg om diagnostiske verktøy.
ICMPs opprinnelige design ble skissert av Jon Postel, en sentral bidragsyter til utviklingen av internett. Den første standarden for ICMP ble publisert i april 1981 i RFC 777.
Den opprinnelige definisjonen har gjennomgått flere endringer for å nå dagens form. Den stabile versjonen av protokollen ble publisert i september 1981 i RFC 792, også forfattet av Postel.
Hvordan fungerer ICMP?
Kort fortalt brukes ICMP til å rapportere feil ved å analysere hvor raskt data når sin destinasjon.
I et enkelt scenario er to enheter tilkoblet internett og utveksler informasjon ved hjelp av datapakker. ICMP genererer feilmeldinger og sender dem til avsenderen dersom pakkene ikke når frem.
Dersom du for eksempel sender en datapakke som er for stor for en ruter, vil ruteren forkaste pakken og generere en feilmelding som informerer avsenderen om at pakken ikke nådde destinasjonen.
Dette er en passiv funksjon, da du ikke trenger å gjøre noe for å motta disse feilmeldingene. Men ICMP har også mer aktive funksjoner som kan benyttes til nettverksfeilsøking.
I motsetning til TCP og UDP, krever ikke ICMP en etablert forbindelse for å sende meldinger. En TCP-tilkobling krever en håndtrykksprosedyre før dataoverføring kan starte. Med ICMP kan meldingen sendes uten en slik tilkobling. Videre krever ikke ICMP en port for å sende meldinger, i motsetning til TCP og UDP, som benytter porter for å rute informasjon. ICMP bruker ikke porter og tillater heller ikke målretting mot spesifikke porter.
ICMP-meldinger transporteres via IP-pakker, men er ikke direkte inkludert i dem. De «haiker» på disse pakkene og oppstår kun dersom IP-pakkene ikke når destinasjonen. Ofte er omstendighetene som genererer en ICMP-pakke, avledet av informasjonen i den mislykkede IP-pakkens hode.
Siden ICMP inkluderer data fra den mislykkede pakkens IP-hode, kan nettverksanalyseverktøy finne nøyaktig hvilke IP-pakker som ikke ble levert. IP-hodet er imidlertid ikke den eneste informasjonen i en ICMP-pakke.
En ICMP-pakke består av et IP-hode, et ICMP-hode og de første åtte bytene av nyttelasten.
IP-hode – inneholder detaljer om IP-versjon, kilde- og destinasjons-IP-adresser, antall pakker sendt, protokoll som benyttes, pakkelengde, levetid (TTL), synkroniseringsdata, samt ID-numre for spesifikke datapakker
ICMP-hode – inneholder en kode som kategoriserer feilen, en underkode som beskriver feilen, og en kontrollsum
Transportlagshode – de første åtte bytene av nyttelasten (overført gjennom TCP eller UDP)
ICMP-kontrollmeldinger
Som nevnt kan verdier i det første feltet i ICMP-hodet brukes til å identifisere feil. Disse feiltypene og deres identifikatorer er:
| 0 | Ekkosvar – brukes til ping |
| 3 | Destinasjon utilgjengelig |
| 5 | Omdirigeringsmelding – indikerer en annen rute |
| 8 | Ekkoforespørsel – brukes til ping |
| 9 | Ruterannonse – rutere kunngjør tilgjengelige IP-adresser for ruting |
| 10 | Ruteroppfordring – oppdagelse eller valg av ruter |
| 11 | Tid overskredet – TTL utløpt eller gjenmonteringstid overskredet |
| 12 | Parameterproblem: Feil IP-hode – feil lengde, manglende alternativ eller pekerfeil |
| 13 | Tidsstempel |
| 14 | Tidsstempelsvar |
| 41 | Eksperimentelle mobilitetsprotokoller |
| 42 | Utvidet ekkoforespørsel – ber om utvidet ekko |
| 43 | Utvidet ekkosvar – svar på utvidet ekkoforespørsel (42) |
| 253 og 254 | Eksperimentell |
TTL-feltet (Time to Live)
TTL-feltet er et av feltene i IP-hodet som ofte genererer en ICMP-feil. Det angir maksimalt antall rutere en pakke kan passere før den når sin destinasjon.
Hver gang pakken behandles av en ruter, reduseres TTL-verdien med én. Dette fortsetter inntil enten pakken når sin destinasjon, eller TTL-verdien blir null. I sistnevnte tilfelle forkastes pakken av ruteren, og en ICMP-melding sendes til den opprinnelige avsenderen.
Dersom en pakke forkastes fordi TTL-verdien når null, skyldes det ikke feil i hodet eller ruterproblemer. TTL-feltet er designet for å forhindre useriøse pakker fra å hindre tilkoblinger, og har bidratt til verktøyet traceroute som er sentralt for feilsøking.
ICMP-bruk i nettverksdiagnostikk
ICMP er sentralt i diagnostiske verktøy for å undersøke nettverkstilkoblinger. Selv om du kanskje ikke har vært kjent med ICMP tidligere, er du sannsynligvis kjent med ping, et verktøy som sjekker om en vert er tilgjengelig.
Ping er et viktig verktøy som baserer seg på ICMP. Traceroute er et annet verktøy som benytter ICMP for å diagnostisere tilkoblingsproblemer. Pathping, en kombinasjon av ping og traceroute, er også et ICMP-basert verktøy.
Ping
Ping er et innebygd Windows-verktøy tilgjengelig via CMD. Det bruker ICMP for å feilsøke nettverksfeil, nærmere bestemt kodene 8 (ekkoforespørsel) og 0 (ekkosvar).
To ping-kommandoer kan se slik ut:
ping 168.10.26.7
ping wdzwdz.com
Ping sender en ICMP-pakke med kode 8 og venter på et svar med kode 0. Når svaret mottas, måler ping tiden det tar fra forespørsel til svar (rundturen) i millisekunder.
ICMP-pakker genereres vanligvis som følge av feil. Forespørselspakken (type 8) trenger imidlertid ikke en feil for å sendes, og ping kan motta et svar (0) uten å utløse en feil.
Du kan pinge en IP-adresse eller en vert. Ping har også flere alternativer for avansert feilsøking, som legges til kommandoen.
For eksempel vil -4-alternativet tvinge ping til å bruke IPv4, mens -6 vil tvinge frem IPv6. Se skjermbildet nedenfor for en komplett liste over alternativer.
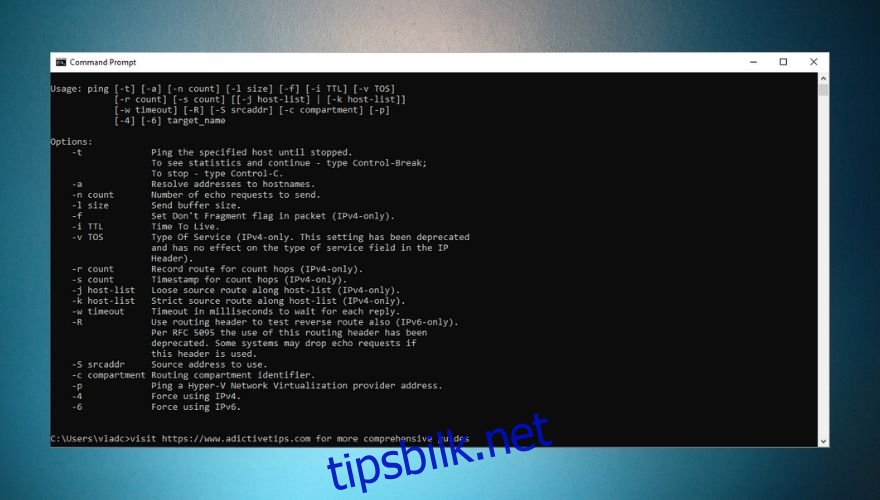
En vanlig misforståelse er at ping kan brukes til å sjekke tilgjengeligheten til spesifikke porter. ICMP utfører ikke meldingsutveksling mellom verter på samme måte som TCP eller UDP, og krever ikke portbruk.
Portskannere bruker TCP- eller UDP-pakker for å identifisere åpne porter. Verktøyene sender TCP- eller UDP-pakker til en spesifikk port og genererer en type 3 (utilgjengelig vert) undertype 3 (destinasjonsport uoppnåelig) ICMP-melding dersom porten ikke er aktiv.
Traceroute
Traceroute er et annet feilsøkingsverktøy for nettverk, som brukes til å kartlegge ruten en tilkobling tar til destinasjonen.
Dette verktøyet er nyttig for å finne ruten mellom deg og en annen maskin, og kan også hjelpe med å identifisere eventuelle problemer underveis.
Dersom en enhet i ruten har problemer med å videresende pakkene, vil traceroute vise hvilken ruter som forårsaker forsinkelser.
Traceroute fungerer ved å sende en pakke med en TTL-verdi på 0, som automatisk forkastes av den første ruteren den møter. Deretter sender ruteren en ICMP-pakke tilbake til traceroute.
Programmet leser pakkens kildeadresse og tiden det tok pakken å returnere, og sender en ny pakke med TTL-verdi på 1. Etter å ha passert første ruter, reduseres TTL-verdien til 0 ved den neste ruteren, og den forkaster pakken og sender en ICMP-pakke tilbake til traceroute.
Dette fortsetter med økende TTL-verdier, til enten destinasjonen nås, eller traceroute går tom for «hopp». Windows har som standard en maksgrense på 30 hopp, men dette kan endres.
Her er et eksempel på hvordan traceroute kan kjøres i CMD:
tracert wdzwdz.com
Traceroute har flere alternativer for mer spesifikke søk. Du kan velge IPv4 eller IPv6, hoppe over å løse adresser til vertsnavn og øke antallet hopp. Se skjermbildet for et eksempel og en liste over alternativer.
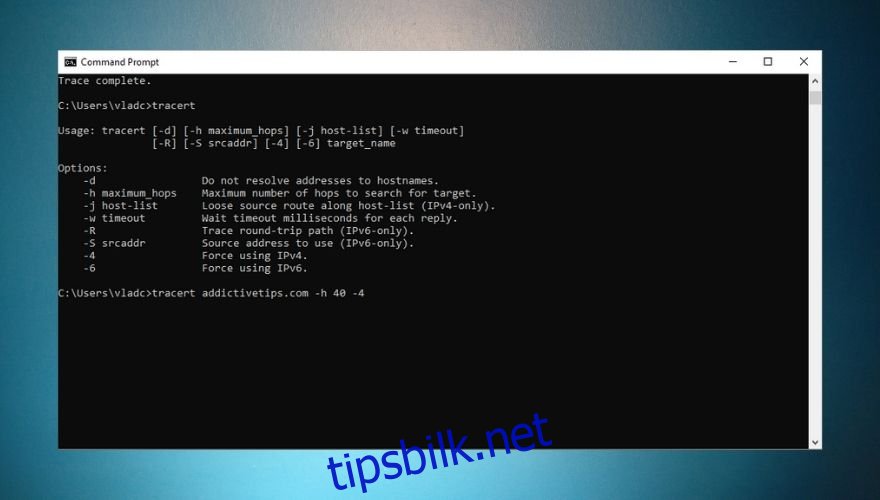
Traceroute gir sanntidsinformasjon. Dersom du opplever en nedgang i tilkoblingen, kan resultatene være misvisende, da ruten kan ha endret seg. Du kan tvinge traceroute til å følge en spesifikk rute med -j-alternativet og legge til ruteradresser, men da må du allerede vite hvilken rute som er feil.
Dersom du ikke foretrekker kommandolinjeverktøy, finnes det flere tredjepartsløsninger med grafisk brukergrensesnitt (GUI). SolarWinds Traceroute NG er et eksempel på en slik gratis løsning.
Pathping
Pathping er en kombinasjon av ping og traceroute, som benytter meldingstypene ekkoforespørsel (8), ekkosvar (0) og tid overskredet (11).
Pathping brukes for å identifisere tilkoblingsnoder med høy latenstid og pakketap. Funksjonaliteten til begge verktøyene samlet i én kommando er svært praktisk for nettverksadministratorer.
En ulempe med pathping er at den kan ta tid å fullføre (25 sekunder per hopp for ping-statistikk). Pathping viser både ruten til destinasjonen og tur-retur-tidene.
I motsetning til ping og traceroute, pinger pathping hver ruter i ruten gjentatte ganger. Dersom en ruter har deaktivert ICMP, stopper pathping å hente informasjon. Ping kan fortsatt nå en ruter uten ICMP-funksjoner, og traceroute vil hoppe til neste ruter og vise stjerner for alle ikke-ICMP-rutere.
Pathping er et innebygd Windows-verktøy, som kan brukes via en kommandolinje.
Eksempel på bruk av pathping:
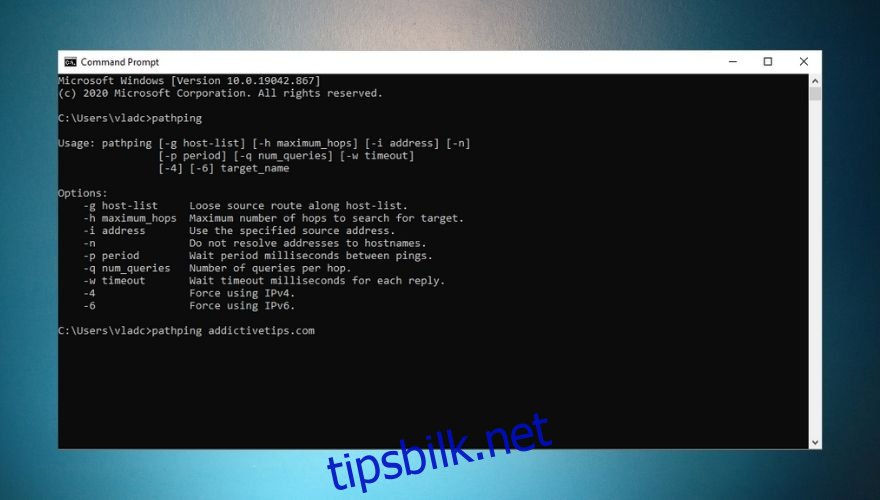
pathping wdzwdz.com -h 40 -w 2 -4
Kommandoen viser ruten til nettstedet og tur-retur-tider. I eksemplet øker det maksimale antall hopp fra 30 til 40, legger til en tidsavbruddsverdi på 2 millisekunder, og tvinger frem IPv4. Se skjermbildet for en oversikt og en liste over alternativer.
ICMP-anvendbarhet i cyberangrep
ICMP muliggjør effektiv feilsøking, men kan også utnyttes i cyberangrep, som ping-flom, DDoS, Ping of Death, Smurf Attacks eller ICMP-tunneler.
Noen av disse angrepene brukes i dag som proof of concept (PoC), mens andre brukes av ondsinnede aktører til å skade systemer eller av sikkerhetseksperter for å teste sårbarheter.
Vi starter med pingflom, som fortsatt er mye brukt, og forklarer hvordan den benytter ICMP for å gjøre skade.
Pingflom
Det å sende ekkoforespørsler og motta ekkosvar virker ufarlig. Men hva om man sender et stort antall ICMP-ekkoforespørsler uten å vente på svar? I et slikt DoS-angrep (Denial of Service) vil målenheten oppleve etterslep og eventuelt brudd i tilkoblingen.
Angrepet er mest effektivt dersom angriperen har mer båndbredde enn offeret, og dersom offeret sender ekkosvar på alle forespørslene, og dermed forbruker både innkommende og utgående båndbredde.
Angriperen kan legge til et «flood»-alternativ til ping-kommandoen, men dette er sjeldent og ikke innebygd i operativsystemets verktøy. For eksempel har ikke Windows» ping et slikt alternativ, men tredjepartsverktøy kan ha det.
Et pingflomangrep kan være katastrofalt som et DDoS-angrep (Distributed Denial of Service). Et DDoS-angrep bruker flere systemer til å angripe én enkelt enhet med pakker samtidig.
En måte å beskytte seg mot pingflom er å deaktivere ICMP-funksjoner på ruteren. Du kan også bruke en brannmur for å beskytte en webserver mot slike angrep.
Ping of Death
Dette angrepet sender en feilaktig ping til en måldatamaskin. Pakken inneholder for mye fyllstoff i nyttelasten til at den kan behandles.
Før pakken sendes, deles den i mindre deler, da overføring i sin opprinnelige form ville være umulig. Datamaskinen som er angrepet mottar bitene og forsøker å sette dem sammen. Dersom den sammensatte pakken er større enn tilgjengelig minne, kan sammensettingen resultere i bufferoverløp, systemkrasj og potensielt skadelig kode.
Ping of Death er ikke lenger en nyhet, da mange sikkerhetssystemer kan identifisere og blokkere denne type angrep.
Smurfeangrep
Et Smurf-angrep angriper ikke en enhet direkte, men benytter andre enheter på samme nettverk for å utføre et DDoS-angrep mot en enkelt enhet.
Angriperen trenger målets IP-adresse og nettverkets IP-kringkastingsadresse. Angriperen legger til offerets IP-adresse til ICMP-pakker (forfalsker den) og sender dem til nettverket ved hjelp av en IP-kringkastingsadresse.
De fleste enheter koblet til samme nettverk vil sende et svar til kildens IP-adresse (som er erstattet med målets adresse), som kan bli overveldet med trafikk dersom nettverket er stort nok.
Dette kan føre til at målets datamaskin bremses eller blir ubrukelig for en periode dersom angrepet er kraftig nok.
Du kan unngå et Smurf-angrep ved å slå av ICMP-funksjoner på gateway-ruteren eller svarteliste forespørsler fra nettverkets kringkastings-IP-adresse.
Twinge-angrep
Et Twinge-angrep bruker et program til å sende en flom av falske ICMP-pakker for å skade et system. ICMP-pakkene bruker tilfeldige falske IP-adresser, men kommer i realiteten fra én kilde (angriperens maskin).
ICMP-pakkene inneholder angivelig en signatur som avslører at angrepet koordineres med Twinge.
Dette angrepet kan være ødeleggende dersom det er godt planlagt. Å slå av ICMP på gateway-ruteren og installere en brannmur eller et inntrengningsdeteksjonssystem kan bidra til beskyttelse.
ICMP-tunnel
Rutere skanner som standard kun ICMP-pakkehoder. Dette åpner for at pakker med ekstra data kan omgå deteksjon så lenge de inneholder en ICMP-seksjon. Dette kalles ICMP- eller ping-tunnel. Standard ping-verktøy kan ikke tunnelere gjennom brannmurer, da ICMP-tunneler må tilpasses spesifikt til nettverkene.
Det finnes flere ressurser på nett som angripere kan bruke for å etterligne en slik tunnel, og dermed gi seg selv fri passasje gjennom private nettverk. Å slå av ICMP-funksjoner på gateway-ruteren, bruke brannmurer og håndheve svartelisteregler er viktig for å unngå denne typen angrep.
ICMP – Konklusjon
ICMP brukes ikke til å utveksle informasjon mellom tilkoblede enheter som TCP og UDP, men er likevel svært viktig. ICMP er en fleksibel protokoll som bidrar til at internett fungerer slik vi kjenner det.
ICMP informerer systemer om det er problemer med tilkoblingen til et annet system. ICMP er også sentralt i feilsøkingsverktøy som ping, pathping og traceroute. Dessverre bidrar ICMP også til at ondsinnede aktører kan utføre DoS-angrep og andre infiltrasjonsforsøk mot sårbare enheter.