
Kunstig intelligens (AI) er en populær og innovativ teknologi som tar menneskelig intelligens til neste nivå. Den tilbyr kraften til nøyaktig intelligens integrert med maskiner.
Mennesker er utstyrt med tenkning, resonnement, tolkning og forståelse av kunnskap på høyt nivå. Kunnskapen vi får hjelper oss å utføre ulike aktiviteter i den virkelige verden.
Nå for tiden blir selv maskiner i stand til å gjøre så mange ting, takket være teknologi.
Nylig har bruken av AI-drevne systemer og enheter økt på grunn av deres effektivitet og nøyaktighet i å utføre komplekse oppgaver.
Nå er problemet at mens mennesker har tilegnet seg mange nivåer og typer kunnskap i livet, har maskiner problemer med å tolke den samme kunnskapen.
Derfor brukes kunnskapsrepresentasjon. Dette vil løse komplekse problemer i vår verden som er vanskelige og tidkrevende for mennesker å takle.
I denne artikkelen vil jeg forklare kunnskapsrepresentasjon i AI, hvordan det fungerer, dets typer og teknikker og mer.
La oss begynne!
Innholdsfortegnelse
Hva er kunnskapsrepresentasjon og resonnement?
Kunnskapsrepresentasjon og resonnement (KR&R) er en del av kunstig intelligens som utelukkende er dedikert til å representere informasjon om den virkelige verden i en slik form at en datamaskin kan forstå og handle deretter. Dette fører til å løse komplekse problemer, for eksempel beregning, ha en dialog på naturlig språk, diagnostisere en kritisk medisinsk tilstand, etc.
Kunnskapsrepresentasjon finner veien fra psykologi om hvordan et menneske er i stand til å løse problemer og representere kunnskap til designformalismer. Dette vil la AI forstå hvordan et menneske gjør komplekse systemer enklere mens de bygger og designer.
Det tidligste arbeidet var fokusert på generelle problemløsere, som ble utviklet av Herbert A. Simon og Allen Newell i 1959. Disse systemene brukte datastruktur for dekomponering og planlegging. Systemet starter først med et mål og dekomponerer deretter målet til delmål. Etterpå angir systemet noen konstruksjonsstrategier som kan ivareta hvert delmål.
Denne innsatsen førte deretter til en kognitiv revolusjon innen menneskelig psykologi og en fase av AI som fokuserte på kunnskapsrepresentasjon. Dette resulterte i ekspertsystemer på 1970- og 1980-tallet, rammespråk, produksjonssystemer og mer. Senere endret AI sitt primære fokus til ekspertsystemer som muligens kan matche menneskelig kompetanse, for eksempel medisinsk diagnose.
Dessuten lar kunnskapsrepresentasjon datasystemer forstå og bruke kunnskapen til å løse problemer i den virkelige verden. Den definerer også en måte du kan representere kunnskap og resonnement i AI på.
Kunnskapsrepresentasjon handler ikke bare om å lagre data i databaser; snarere gjør det intelligente maskiner i stand til å lære av menneskelig kunnskap og oppleve det samme, slik at en maskin kan oppføre seg og handle som et menneske.
Mennesker har kunnskap som er fremmed for maskiner, inkludert følelser, intensjoner, tro, sunn fornuft, vurderinger, fordommer, intuisjon og mer. Noe kunnskap er også enkel, som å vite visse fakta, generell kunnskap om hendelser, mennesker, gjenstander, språk, akademiske disipliner, etc.
Med KR&R kan du representere konseptene til mennesker i et forståelig format for maskiner og gjøre de AI-drevne systemene virkelig intelligente. Her betyr kunnskap å gi informasjon om økosystemet og lagre dem, mens resonnement betyr å ta beslutninger og handlinger fra den lagrede informasjonen basert på kunnskapen.
Hvilken kunnskap skal representeres i AI-systemer?
Kunnskapen som må presenteres i systemer for kunstig intelligens kan omfatte:
- Objekt: Objekter omgir mennesker konstant. Derfor er informasjonen om disse objektene viktig og må betraktes som en kunnskapstype. For eksempel har pianoer hvite og svarte taster, biler har hjul, busser trenger sjåfører, fly trenger piloter osv.
- Hendelser: Tallrike hendelser finner sted hele tiden i den virkelige verden. Og menneskelig oppfatning er basert på hendelser. AI må ha hendelseskunnskap for å kunne handle. Noen hendelser er hungersnød, utvikling av samfunn, kriger, katastrofer, prestasjoner og mer.
- Ytelse: Denne kunnskapen omhandler menneskers bestemte handlinger i ulike situasjoner. Det representerer atferdssiden av kunnskap som er ganske viktig for AI å forstå.

- Metakunnskap: Hvis vi for eksempel ser oss rundt i verden og oppsummerer all kunnskapen der ute, ser vi at den stort sett er delt inn i tre kategorier:
- Det vi allerede vet
- Det vi vet er i utgangspunktet ting vi ikke vet helt
- Hva vet vi ikke ennå
- Metakunnskap omhandler den første, dvs. det vi vet og lar AI oppfatte det samme.
- Fakta: Denne kunnskapen er basert på den faktiske beskrivelsen av vår verden. Jorden er for eksempel ikke flat, men heller ikke rund; solen vår har en glupsk appetitt, og mer.
- Kunnskapsbase: Kunnskapsbasen er hovedkomponenten i menneskelig intelligens. Dette refererer til en gruppe med relevante data eller informasjon om ethvert felt, beskrivelse og mer. For eksempel en kunnskapsbase om å designe en bilmodell.
Hvordan fungerer kunnskapsrepresentasjon?
Vanligvis gis en oppgave å utføre, et problem å løse, og å få en løsning, uformelt, som å levere pakker når de ankommer eller fikse elektriske problemer i huset.
For å løse et reelt problem, må systemdesigneren:
- Utfør oppgaven for å finne ut hvilken bedre løsning den kan gi
- Representer problemet på et språk slik at en datamaskin kan forklare det
- Bruk systemet til å datamaskin en endelig utgang, som er løsningen for brukere eller en sekvens av aktiviteter som må gjøres i økosystemet.
- Tolk det endelige resultatet som en løsning på hovedproblemet
Kunnskap er informasjonen som et menneske allerede har, men maskiner trenger å lære. Siden det er mange problemer, trenger maskinen kunnskap. Som en del av designsystemet kan du definere hvilken kunnskap som skal representeres.
Forbindelse mellom kunnskapsrepresentasjon og AI
Kunnskap spiller en viktig rolle i intelligens. Det er også ansvarlig for å lage kunstig intelligens. Når det er nødvendig å uttrykke intelligent oppførsel i AI-agentene, spiller det en nødvendig rolle. En agent er ikke i stand til å fungere nøyaktig når den mangler erfaring eller kunnskap om visse input.

For eksempel, hvis du ønsker å samhandle med en person, men ikke er i stand til å forstå språket, er det åpenbart at du ikke kan reagere godt og utføre noen handling. Dette fungerer på samme måte for agenters intelligente oppførsel. AI må ha nok kunnskap til å utføre funksjonaliteten ettersom en beslutningstaker oppdager miljøet og bruker den nødvendige kunnskapen.
Imidlertid kan AI ikke vise intellektuell atferd uten kunnskapskomponentene.
Typer kunnskap representert i AI
Nå som vi er klare på hvorfor vi trenger kunnskapsrepresentasjon i AI, la oss finne ut hvilke typer kunnskapen representert i et AI-system.
- Deklarativ kunnskap: Den representerer objektene, konseptene og fakta som hjelper deg med å beskrive hele verden rundt deg. Dermed deler den beskrivelsen av noe og uttrykker deklarative setninger.
- Prosedyrekunnskap: Prosedyrekunnskap er mindre sammenlignet med deklarativ kunnskap. Det er også kjent som imperativ kunnskap, som brukes av mobile roboter. Det er for å erklære oppnåelsen av noe. For eksempel, med bare et kart over en bygning, kan mobile roboter lage sin egen plan. Mobile roboter kan planlegge å angripe eller utføre navigering.

Dessuten brukes prosedyrekunnskap direkte på oppgaven som inkluderer regler, prosedyrer, agendaer, strategier og mer.
- Metakunnskap: Innenfor kunstig intelligens er forhåndsdefinert kunnskap kjent som metakunnskap. For eksempel faller studiet av tagging, læring, planlegging osv. inn under denne typen kunnskap.
Denne modellen endrer oppførsel med tiden og bruker andre spesifikasjoner. En systemingeniør eller kunnskapsingeniør bruker ulike former for metakunnskap, som nøyaktighet, vurdering, formål, kilde, levetid, pålitelighet, begrunnelse, fullstendighet, konsistens, anvendelighet og disambiguering.
- Heuristisk kunnskap: Denne kunnskapen, som også er kjent som grunn kunnskap, følger tommelfingerregelprinsippet. Derfor er det svært effektivt i resonneringsprosessen, da det kan løse problemer basert på tidligere poster eller problemer som er satt sammen av eksperter. Den samler imidlertid erfaringer fra tidligere problemer og gir en bedre kunnskapsbasert tilnærming til å spesifisere problemer og iverksette tiltak.
- Strukturell kunnskap: Strukturell kunnskap er den mest enkle og grunnleggende kunnskapen som brukes og brukes til å løse komplekse problemer. Den prøver å finne en effektiv løsning ved å finne forholdet mellom objekter og konsepter. I tillegg beskriver den forholdet mellom flere konsepter, som en del av, type eller gruppering av noe.
Deklarativ kunnskap kan representeres som den beskrivende, mens prosedyrekunnskap er den som gjør. I tillegg er deklarativ kunnskap definert som eksplisitt, mens prosessuell kunnskap er taus eller implisitt. Det er deklarativ kunnskap hvis du kan artikulere kunnskapen og prosedyrekunnskap hvis du ikke kan artikulere den.
Teknikker for kunnskapsrepresentasjon i AI
Det er fire hovedteknikker der ute som representerer kunnskapen innen AI:
- Logisk representasjon
- Semantiske nettverk
- Produksjonsregler
- Rammerepresentasjon
Logisk representasjon
Logisk representasjon er den grunnleggende formen for kunnskapsrepresentasjon til maskinene hvor en definert syntaks med grunnleggende regler brukes. Denne syntaksen har ingen tvetydighet i betydningen og omhandler preposisjoner. Den logiske formen for kunnskapsrepresentasjon fungerer imidlertid som kommunikasjonsreglene. Dette er grunnen til at den kan brukes til å representere fakta for maskinene.
Logisk representasjon er av to typer:
- Proposisjonell logikk: Proposisjonell logikk er også kjent som utsagnslogikk eller proposisjonell kalkulus som fungerer i en boolsk, som betyr en metode for Sant eller Usant.
- Førsteordens logikk: Førsteordens logikk er en type logisk kunnskapsrepresentasjon som du også kan kalle First Order Predicate Calculus Logic (FOPL). Denne representasjonen av logisk kunnskap representerer predikatene og objektene i kvantifiserere. Det er en avansert modell for proposisjonell logikk.
Denne formen for kunnskapsrepresentasjon ser ut som de fleste programmeringsspråkene der man bruker semantikk for å videresende informasjon. Det er en svært logisk måte å løse problemer på. Imidlertid er den største ulempen med denne metoden den strenge karakteren til representasjonen. Generelt er det vanskelig å utføre og noen ganger ikke veldig effektivt.
Semantiske nettverk

En grafisk representasjon, i denne typen kunnskapsrepresentasjon, bærer de tilkoblede objektene som brukes med datanettverket. De semantiske nettverkene inkluderer buer/kanter (forbindelser) og noder/blokker (objekter) som beskriver forbindelsen mellom objektene.
Dette er et alternativ til First Order Predicate Calculus Logic (FOPL) representasjonsform. Relasjonene i de semantiske nettverkene er av to typer:
Det er en mer naturlig representasjonsform enn logisk på grunn av dens enkle forståelse. Den største ulempen med denne representasjonsformen er at den er beregningsmessig dyr og inkluderer ikke tilsvarende kvantifiserere som du kan finne i logisk representasjon.
Produksjonsregler
Produksjonsregler er den vanligste formen for kunnskapsrepresentasjon i AI-systemer. Det er den enkleste formen for å representere if-else regelbaserte systemer og kan derfor lett forstås. Det representerer en måte å kombinere FOPL og proposisjonell logikk på.
For å teknisk forstå produksjonsreglene, må du først forstå komponentene i representasjonssystemet. Dette systemet inkluderer et sett med regler, arbeidsminne, regelapplier og en anerkjent handlingssyklus.
For hver input sjekker AI betingelsene fra produksjonsreglene, og etter å ha funnet en bedre regel, tar den nødvendige tiltak umiddelbart. Syklusen med å velge regler basert på betingelsene og handle for å løse problemet er kjent som gjenkjennelses- og handlingssyklusen som finner sted i hver input.
Imidlertid har denne metoden noen problemer, for eksempel ineffektiv utførelse på grunn av de aktive reglene og mangel på erfaring på grunn av manglende lagring av tidligere resultater. Siden reglene er uttrykt i naturlig språk, kan kostnadene for ulempene innløses. Her kan regler enkelt endres og droppes ved behov.
Rammerepresentasjon

For å forstå rammerepresentasjonen på et grunnleggende nivå, se for deg en tabell som består av navn i kolonner og verdier i rader; den nødvendige informasjonen sendes i denne komplette strukturen. Med enkle ord er rammerepresentasjon en samling av verdier og attributter.
Dette er en AI-spesifikk datastruktur som bruker fyllstoffer (slotverdier som kan være av hvilken som helst datatype og form) og spor. Prosessen er ganske lik det typiske Database Management System (DBMS). Disse fyllstoffene og sporene danner en struktur som kalles en ramme.
Sporene, i denne formen for kunnskapsrepresentasjon, har navn eller attributter, og kunnskapen knyttet til attributtene lagres i fillers. Hovedfordelen med denne typen representasjon er at lignende data kan slås sammen i grupper for å dele kunnskapen inn i strukturer. Videre er den delt inn i understrukturer.
Denne typen er som en typisk datastruktur, og kan lett forstås, manipuleres og visualiseres. Typiske konsepter, inkludert å fjerne, slette og legge til spor, kan utføres uten problemer.
Krav til Kunnskapsrepresentasjon i AI-system
En god kunnskapsrepresentasjon inneholder noen egenskaper:
- Representasjonsnøyaktighet: Kunnskapsrepresentasjon må representere hver type nødvendig kunnskap nøyaktig.
- Inferensiell effektivitet: Det er evnen til å håndtere inferensielle kunnskapsmekanismer lett i produktive retninger ved å bruke passende guider.
- Inferensiell tilstrekkelighet: Kunnskapsrepresentasjon bør ha evnen til å manipulere noen representasjonsstrukturer for å representere ny kunnskap basert på de eksisterende strukturene.
- Anskaffelseseffektivitet: Evnen til å tilegne seg ny kunnskap ved hjelp av automatiske metoder.
AI kunnskapssyklus
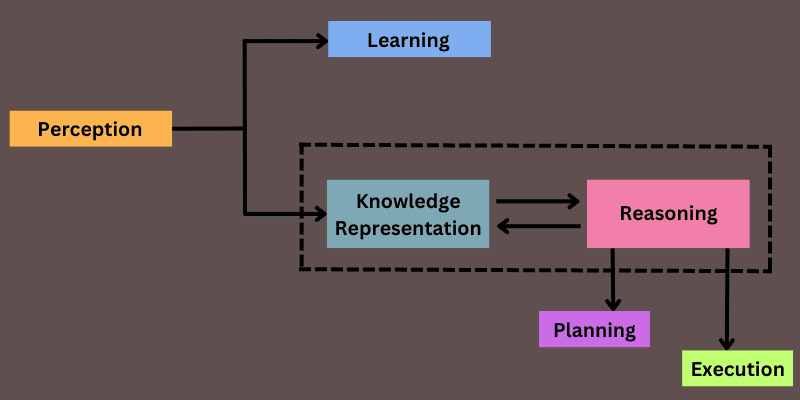
AI-systemer inkluderer noen hovedkomponenter for å vise intelligent atferd som gjør det mulig å representere kunnskap.
- Persepsjon: Det hjelper det AI-baserte systemet med å samle informasjon om miljøet ved hjelp av forskjellige sensorer og gjør det kjent med økosystemet for å effektivt samhandle med problemene.
- Læring: Den brukes til å la AI-systemer kjøre dyplæringsalgoritmer som allerede er skrevet for å få AI-systemer til å levere nødvendig informasjon fra persepsjonskomponenten til læringskomponenten for bedre læring og forståelse.
- Kunnskapsrepresentasjon og resonnement: Mennesker bruker kunnskap til å ta beslutninger. Derfor er denne blokken ansvarlig for å betjene mennesker gjennom kunnskapsdataene til AI-systemer og bruke relevant kunnskap når det er nødvendig.
- Planlegging og utførelse: Denne blokken er uavhengig. Den brukes til å hente data fra kunnskaps- og resonneringsblokker og utføre relevante handlinger.
Konklusjon
Mennesker kan få kunnskap på forskjellige måter, og det samme gjør AI-baserte maskiner. Ettersom AI utvikler seg, hjelper det å representere kunnskap til maskiner på en bedre måte deg med å løse komplekse problemer med minimal feil. Så kunnskapsrepresentasjon er en viktig egenskap for at AI-maskiner skal fungere intelligent og smart.
Du kan også se på forskjellen mellom kunstig intelligens, maskinlæring og dyp læring.