Regresjon og klassifisering utgjør to sentrale områder innenfor maskinlæring.
Det kan være utfordrende å differensiere mellom regresjons- og klassifiseringsalgoritmer når man begynner å utforske maskinlæring. Forståelsen av hvordan disse algoritmene opererer og når de skal anvendes er essensielt for å oppnå presise forutsigelser og effektive beslutninger.
La oss starte med å utforske begrepet maskinlæring.
Hva er maskinlæring?
Maskinlæring er en metode som gir datamaskiner evnen til å lære og ta avgjørelser uten å være eksplisitt programmert. Dette innebærer å trene en datamodell ved hjelp av et datasett, slik at modellen kan generere prediksjoner eller ta beslutninger basert på mønstre og relasjoner i dataene.
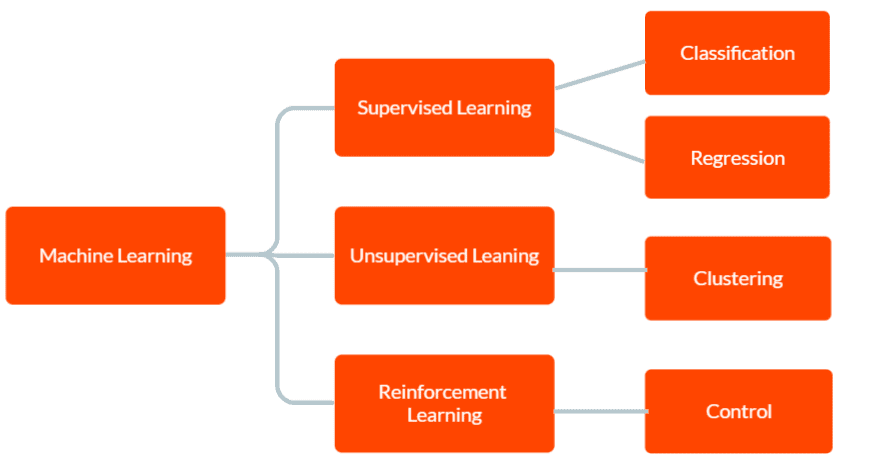
Maskinlæring deles inn i tre hovedkategorier: veiledet læring, ikke-veiledet læring og forsterkende læring.
Innen veiledet læring får modellen tilgang til merkede treningsdata, som inkluderer både inngangsdata og de tilsvarende korrekte utdataene. Målet er at modellen skal kunne forutsi utdata for nye, ukjente data, basert på de mønstrene som er identifisert i treningsdataene.
I ikke-veiledet læring er modellen ikke forsynt med merkede treningsdata. Modellen er i stedet designet for å selvstendig identifisere mønstre og sammenhenger i dataene. Dette kan brukes for å gruppere data i klynger eller for å oppdage uvanlige mønstre eller avvik.
Forsterkende læring innebærer at en agent lærer å samhandle med et miljø for å maksimere en belønning. Modellen trenes til å ta avgjørelser basert på tilbakemeldingene den mottar fra omgivelsene.
Maskinlæring finner anvendelse innenfor en rekke områder, som bilde- og talegjenkjenning, naturlig språkbehandling, svindeldeteksjon og selvkjørende biler. Teknologien har potensial til å automatisere oppgaver og forbedre beslutningsprosesser i ulike sektorer.
Denne artikkelen vil primært fokusere på klassifisering og regresjon, som begge faller inn under veiledet maskinlæring. La oss begynne!
Klassifisering i maskinlæring

Klassifisering er en maskinlæringsteknikk som innebærer å trene en modell til å tildele en bestemt kategori til en gitt inngang. Det er en veiledet læringsoppgave, noe som betyr at modellen trenes ved hjelp av et merket datasett, som inneholder eksempler på inngangsdata og de korresponderende kategoriene.
Målet med modellen er å lære sammenhengen mellom inngangsdataene og kategoriene for å kunne forutsi riktig kategori for nye, usette innganger.
Det finnes en rekke algoritmer som kan brukes for klassifisering, som logistisk regresjon, beslutningstrær og støttevektormaskiner. Valget av algoritme vil avhenge av dataenes natur og modellens ønskede ytelse.
Vanlige bruksområder for klassifisering inkluderer deteksjon av spam, sentimentanalyse og svindeldeteksjon. Inndataene i disse tilfellene kan være tekst, numeriske verdier eller en kombinasjon av begge. Kategoriene kan være binære (f.eks. spam eller ikke spam) eller multiple (f.eks. positiv, nøytral eller negativ følelse).
For eksempel, vurder et datasett med kundeanmeldelser av et produkt. Inndataene kan være selve teksten i anmeldelsen, og kategorien kan være en vurdering (f.eks. positiv, nøytral eller negativ). Modellen vil da bli trent på et datasett med merkede anmeldelser og deretter være i stand til å forutsi vurderingen av en ny anmeldelse den ikke har sett tidligere.
Typer av ML-klassifiseringsalgoritmer
Det finnes ulike typer klassifiseringsalgoritmer innenfor maskinlæring:
Logistisk regresjon
Dette er en lineær modell som brukes for binær klassifisering. Den anvendes for å forutsi sannsynligheten for at en hendelse skal inntreffe. Formålet med logistisk regresjon er å identifisere de optimale koeffisientene (vektene) som minimerer avviket mellom den forutsagte sannsynligheten og det observerte resultatet.
Dette oppnås gjennom bruk av en optimaliseringsalgoritme, slik som gradientnedstigning, for å justere koeffisientene til modellen best mulig reflekterer treningsdataene.
Beslutningstrær
Dette er trelignende modeller som tar avgjørelser basert på verdier av attributter. De kan brukes for både binær og multi-klasse klassifisering. Beslutningstrær har flere fordeler, inkludert deres enkelhet og evne til å tolkes.
De er også raske å trene og bruke for å lage prediksjoner, og de kan håndtere både numeriske og kategoriske data. De kan imidlertid være utsatt for overtilpasning, spesielt hvis treet blir for dypt og komplekst.
Tilfeldig skogklassifisering
Tilfeldig skogklassifisering er en ensemblemetode som kombinerer prediksjonene fra flere beslutningstrær for å generere en mer nøyaktig og stabil prediksjon. Metoden er mindre utsatt for overtilpasning enn et enkelt beslutningstre, ettersom prediksjonene til de individuelle trærne gjennomsnittsberegnes, noe som reduserer variansen i modellen.
AdaBoost
Dette er en boostingsalgoritme som adaptivt endrer vekten til feilklassifiserte eksempler i treningssettet. Det benyttes ofte i binær klassifisering.
Naive Bayes
Naive Bayes er basert på Bayes» teorem, som er en metode for å oppdatere sannsynligheten for en hendelse i lys av ny evidens. Det er en sannsynlighetsbasert klassifiseringsmetode som ofte brukes for tekstklassifisering og spamfiltrering.
K-nærmeste nabo
K-nærmeste nabo (KNN) brukes for klassifiserings- og regresjonsoppgaver. Det er en ikke-parametrisk metode som klassifiserer et datapunkt basert på kategorien til de nærmeste naboene. KNN har flere fordeler, som sin enkelhet og lette implementering. Metoden kan også håndtere både numeriske og kategoriske data og krever ingen forutsetninger om den underliggende datafordelingen.
Gradientforsterkning
Dette er ensembler av svake læringsalgoritmer som trenes sekvensielt, der hver modell forsøker å korrigere feilene til den foregående modellen. De kan brukes for både klassifisering og regresjon.
Regresjon i maskinlæring
Innen maskinlæring er regresjon en form for veiledet læring der målet er å forutsi en avhengig variabel basert på en eller flere inngangsattributter (også kalt prediktorer eller uavhengige variabler).
Regresjonsalgoritmer brukes for å modellere forholdet mellom innganger og utganger og for å generere prediksjoner basert på dette forholdet. Regresjon kan benyttes for både kontinuerlige og kategoriske avhengige variabler.
Generelt sett er hensikten med regresjon å utvikle en modell som nøyaktig kan forutsi utdata basert på inngangsattributtene, samt å forstå det underliggende forholdet mellom disse attributtene og utdataene.
Regresjonsanalyse brukes innen ulike felt, inkludert økonomi, finans, markedsføring og psykologi, for å forstå og forutsi sammenhenger mellom ulike variabler. Det er et fundamentalt verktøy innen dataanalyse og maskinlæring og brukes til å lage prediksjoner, identifisere trender og forstå de underliggende mekanismene som driver dataene.
For eksempel, i en enkel lineær regresjonsmodell kan målet være å forutsi prisen på et hus basert på størrelse, beliggenhet og andre attributter. Størrelsen og plasseringen av huset vil være de uavhengige variablene, og prisen på huset vil være den avhengige variabelen.
Modellen vil bli trent med inndata som inkluderer størrelsen og plasseringen av flere hus sammen med deres respektive priser. Når modellen er trent, kan den brukes til å forutsi prisen på et hus gitt størrelse og plassering.
Typer av ML-regresjonsalgoritmer
Regresjonsalgoritmer finnes i en rekke former, og bruken av hver algoritme avhenger av faktorer som type attributtverdi, mønsteret til trendlinjen og antall uavhengige variabler. Regresjonsteknikker som ofte brukes inkluderer:
Lineær regresjon
Denne enkle lineære modellen brukes for å forutsi en kontinuerlig verdi basert på et sett med attributter. Den brukes til å modellere forholdet mellom attributtene og målvariabelen ved å tilpasse en linje til dataene.
Polynomregresjon
Dette er en ikke-lineær modell som brukes til å tilpasse en kurve til dataene. Den benyttes for å modellere forhold mellom attributtene og målvariabelen når forholdet ikke er lineært. Modellen er basert på å legge til høyere ordens ledd i den lineære modellen for å fange opp ikke-lineære forhold mellom de avhengige og uavhengige variablene.
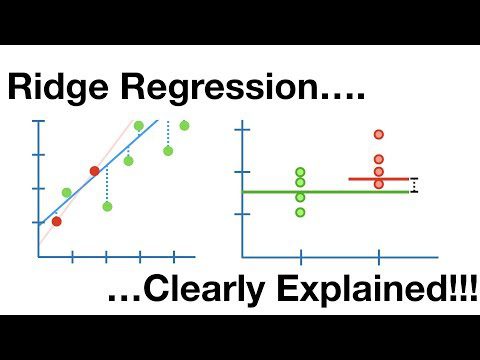
Ridge regresjon
Dette er en lineær modell som motvirker overtilpasning i lineær regresjon. Det er en regularisert versjon av lineær regresjon som legger til et straffeledd i kostnadsfunksjonen for å redusere kompleksiteten til modellen.
Støttevektorregresjon
I likhet med SVM-er er støttevektorregresjon en lineær modell som søker å tilpasse dataene ved å finne det hyperplanet som maksimerer marginen mellom de avhengige og uavhengige variablene.
I motsetning til SVM-er, som brukes for klassifisering, brukes SVR for regresjonsoppgaver, der målet er å forutsi en kontinuerlig verdi i stedet for en kategori.
Lasso regresjon
Dette er en annen regularisert lineær modell som brukes for å forhindre overtilpasning i lineær regresjon. Modellen legger til et straffeledd i kostnadsfunksjonen basert på den absolutte verdien av koeffisientene.
Bayesiansk lineær regresjon
Bayesiansk lineær regresjon er en sannsynlighetsbasert tilnærming til lineær regresjon som bygger på Bayes» teorem, som er en måte å oppdatere sannsynligheten for en hendelse basert på ny evidens.
Denne regresjonsmodellen tar sikte på å estimere den posteriore fordelingen av modellparametrene gitt dataene. Dette oppnås ved å definere en tidligere fordeling over parametrene, og deretter bruke Bayes» teorem til å oppdatere fordelingen basert på de observerte dataene.
Regresjon vs. klassifisering
Regresjon og klassifisering er to former for veiledet læring, som begge brukes til å forutsi en utgang basert på et sett med inngangsattributter. Det er imidlertid noen vesentlige forskjeller mellom de to:
| Regresjon | Klassifisering | |
| Definisjon | En form for veiledet læring som forutsier en kontinuerlig verdi | En form for veiledet læring som forutsier en kategorisk verdi |
| Output type | Kontinuerlig | Diskret |
| Evalueringsmetrikk | Gjennomsnittlig kvadratfeil (MSE), rot gjennomsnittlig kvadratfeil (RMSE) | Nøyaktighet, presisjon, gjenkalling, F1-score |
| Algoritmer | Lineær regresjon, polynomregresjon, Ridge, Lasso, Støttevektorregresjon, Bayesiansk regresjon, Beslutningstrær | Logistisk regresjon, SVM, Naive Bayes, KNN, Beslutningstrær |
| Modellkompleksitet | Mindre komplekse modeller | Mer komplekse modeller |
| Forutsetninger | Lineært forhold mellom attributter og mål | Ingen spesifikke forutsetninger om forholdet mellom attributter og mål |
| Klasseubalanse | Ikke relevant | Kan være en utfordring |
| Outliers | Kan påvirke modellens ytelse | Mindre viktig |
| Attributtegenskaper | Rangeres vanligvis | Rangeres ikke etter betydning |
| Eksempelapplikasjoner | Forutsi priser, temperaturer, mengder | Forutsi om e-post er spam, forutsi kundefrafall |
Læringsressurser
Det kan være vanskelig å velge de mest nyttige ressursene på nett for å forstå konsepter innen maskinlæring. Vi har undersøkt populære kurs fra anerkjente plattformer for å presentere anbefalinger for de beste ML-kursene om regresjon og klassifisering.
#1. Machine Learning Classification Bootcamp i Python
Dette er et kurs som tilbys på Udemy-plattformen. Det dekker en rekke klassifiseringsalgoritmer og teknikker, som beslutningstrær, logistisk regresjon og støttevektormaskiner.

Du vil også lære om temaer som overtilpasning, tradeoff mellom bias og varians, samt evaluering av modeller. Kurset benytter Python-biblioteker som scikit-learn og pandas for å implementere og evaluere maskinlæringsmodeller. Grunnleggende Python-kunnskaper er derfor nødvendig for å delta på dette kurset.
#2. Machine Learning Regresjon Masterclass i Python
I dette Udemy-kurset dekker instruktøren grunnleggende prinsipper og teorien bak ulike regresjonsalgoritmer, inkludert lineær regresjon, polynomregresjon og Lasso- og Ridge regresjonsteknikker.
Etter å ha fullført kurset, vil du kunne implementere regresjonsalgoritmer og vurdere ytelsen til trente maskinlæringsmodeller ved hjelp av forskjellige nøkkelytelsesindikatorer.
Oppsummering
Maskinlæringsalgoritmer kan være svært verdifulle i mange applikasjoner og kan bidra til å automatisere og effektivisere en rekke prosesser. ML-algoritmer bruker statistiske metoder for å lære mønstre i data og for å lage prediksjoner eller ta beslutninger basert på disse mønstrene.
De kan trenes på store mengder data og brukes til å utføre oppgaver som ville være vanskelige eller tidkrevende for mennesker å gjøre manuelt.
Hver ML-algoritme har sine styrker og svakheter, og valget av algoritme avhenger av dataenes karakter og kravene til oppgaven. Det er viktig å velge den riktige algoritmen eller kombinasjonen av algoritmer for det spesifikke problemet man forsøker å løse.
Det er viktig å velge riktig type algoritme for problemstillingen, da bruk av feil type algoritme kan føre til dårlig ytelse og unøyaktige prediksjoner. Hvis du er usikker på hvilken algoritme du skal benytte, kan det være nyttig å prøve både regresjons- og klassifiseringsalgoritmer og sammenligne ytelsen på datasettet ditt.
Jeg håper du har funnet denne artikkelen nyttig for å lære om regresjon kontra klassifisering innenfor maskinlæring. Du kan også være interessert i å lære om de beste maskinlæringsmodellene.