

Datainntak er en avgjørende del av en datasentrisk prosess, som sikrer at organisasjoner får riktig informasjon til rett tid for å forstå virksomhetens ytelse og forbedre den.
Moderne organisasjoner genererer enorme mengder data hver dag som er av høy verdi for deres virksomheter.
Ved å utføre forretningsanalyse kan organisasjoner få dypere innsikt, noe som hjelper dem å ta informerte, datadrevne beslutninger.
Disse dataene spiller også en nøkkelrolle i å forstå kunder, forutsi markedet, planlegge, forutsi trender og oppnå andre fordeler.
For å utføre visse oppgaver er det imidlertid avgjørende å trekke ut og analysere data og enkelt få tilgang til dem fra et sentralisert sted.
Det er her datainntak kommer inn.
Denne teknikken trekker ut data fra flere kilder, slik at du kan avdekke innsikt gjemt i den og bruke den videre til å utvide virksomheten din.
I denne artikkelen skal jeg snakke om datainntak og dens typer, trinnvise prosesser, arkitektur, brukstilfeller, fordeler, beste praksis og utfordringer.
Her går vi!
Innholdsfortegnelse
Hva er datainntak?
Datainntak er prosessen med å samle inn data fra en eller flere kilder og importere dem til et datavarehus for umiddelbar bruk. Det er et av de mest essensielle trinnene i arbeidsflyten for dataanalyse.

Data kan inntas i batcher eller streames i sanntid. Når dataene flyttes til det målrettede nettstedet, lagres de riktig og brukes deretter til analyse.
Datakildene kan være datainnsjøer, databaser, IoT-enheter, SaaS-applikasjoner, lokale databaser og andre plattformer som kan ha relevante og viktige data.
Datainntak er en enkel prosess som tar data fra en opprinnelse, renser den og videresender dem til en destinasjon hvor en bedrift kan bruke, få tilgang til og analysere dataene.
Datainntak gjør det mulig for organisasjoner å ta datadrevne beslutninger fra den økende kompleksiteten og volumet av data som de produserer hver dag.
Når en organisasjon samler inn data, forblir den i sin opprinnelige og rå tilstand, den samme som den er i kilden. Du må utføre en transformasjonsoperasjon når det er behov for å transformere eller analysere dataene til et lesbart format som er kompatibelt med forskjellige applikasjoner.
Det primære målet med datainntak er å flytte et stort sett med data fra ett sted til et annet effektivt ved hjelp av programvareautomatisering. Den inntar bare data, ikke transformerer dem. For mange organisasjoner fungerer det som et kritisk verktøy som lar dem administrere frontenden av dataene.
Det er flere måter å innta data i datamarkedet. I henhold til dine spesielle behov og designkrav, kan du velge hvilken som helst inntaksmetode som fungerer best for deg.
Hvordan fungerer datainntak?
Datainntak samler inn data fra flere kilder der dataene opprinnelig ble lagret eller generert. Den laster eller overfører data til destinasjonen eller oppsamlingsområdet. Datainntakspipelinen bruker lette transformasjoner der det er nødvendig for å filtrere ut eller optimalisere dataene før de sendes til en meldingskø, datalager eller destinasjon.
Datainntak utfører også komplekse transformasjoner, inkludert sortering, sammenføyninger og aggregater for spesifikke applikasjoner, rapporterings- og analysesystemer med supplerende rørledninger.
For å forstå trinn-for-trinn-prosessen med datainntak, må du dykke ned i arkitekturen.
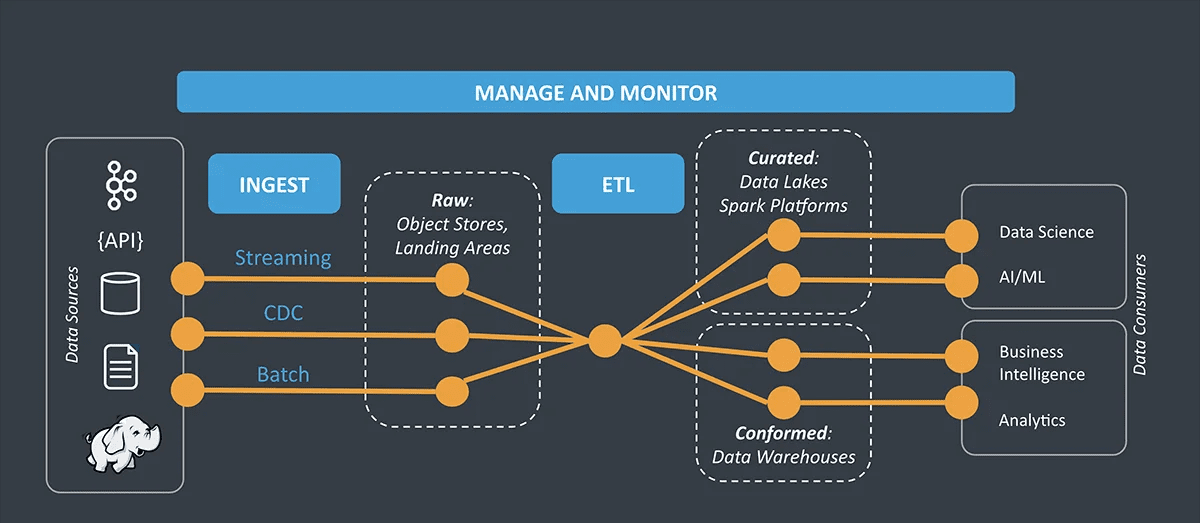 Kilde: Strømsett
Kilde: Strømsett
Arkitektur for datainntak
Arkitekturen for datainntak forteller deg om dataflyten i følgende lag:
- Datainnsamlingslag: Det samler inn data fra forskjellige kilder og lagrer det i datavarehuset ditt. Dette laget definerer hvordan data overføres eller analyseres til andre lag i inntaksarkitekturen. Det hjelper også med å bryte ned dataene for analytisk behandling.
- Databehandlingslag: Dette laget samler inn data fra forrige lag for å behandle overføringen av data som er lagret. Den definerer destinasjonen du vil sende dataene til og grupperer dem deretter.
- Datalagringslag: Når dataene er gruppert, lagres de på et effektivt sted for videre overføring.
- Dataspørringslag: Dette er det analytiske laget i datainntaksarkitekturen. Her spørres data slik at laget kan trekke ut verdifull innsikt.
- Datavisualiseringslag: Datavisualisering er det siste laget som omhandler datapresentasjon. Den viser dataene i et forståelig og visuelt format for organisasjonen din for å få sanntidsinnsikt.
Fordeler med datainntak

La oss diskutere noen av fordelene med datainntak:
- Tilgjengelighet: Når en organisasjon implementerer en datainntaksprosess, kan data være tilgjengelig og lett tilgjengelig for organisasjonen. Siden data samles inn fra flere kilder og overføres til et lagringssted, kan alle med gyldig autorisasjon enkelt få tilgang til dataene for analyse.
- Ensartethet: En god praksis for datainntak forbedrer datakvaliteten ved å gjøre flere datatyper om til en enhetlig datatype. Til dette er det lettere å manipulere og forstå data for fremtidig analyse.
- Forbedret produktivitet: Datainntak lar deg bruke data til å bli mer produktiv. Dette hjelper dataingeniører med å bli mer fleksible og lar dem utvikle kraften til å skalere.
- Forbedret beslutningstaking: Datainntaksprosessen lar organisasjoner ta bedre og mer informerte beslutninger ved å bruke sanntidsdata. I tillegg kan du utlede analyser som er nyttige for å ta taktiske beslutninger og spore KPIer og potensielle mål.
- Forbedret brukeropplevelse: Organisasjoner bruker nyere data for å betjene sine verdifulle kunder. Datadrevet analyse lar dem bygge effektive verktøy og applikasjoner for kunder.
Typer datainntak
Det er tre typer datainntak – batchbehandling, sanntidsdatainntak og lambdabasert datainntak. Valget av å velge en av dem avhenger i stor grad av typen virksomhet, IT-infrastruktur, budsjett, tidslinje og mål som skal oppnås. Bedrifter velger også sin modell og verktøy basert på datakildene de bruker.
La oss dykke dypere inn i hver av dem mer detaljert.
#1. Batchbehandling
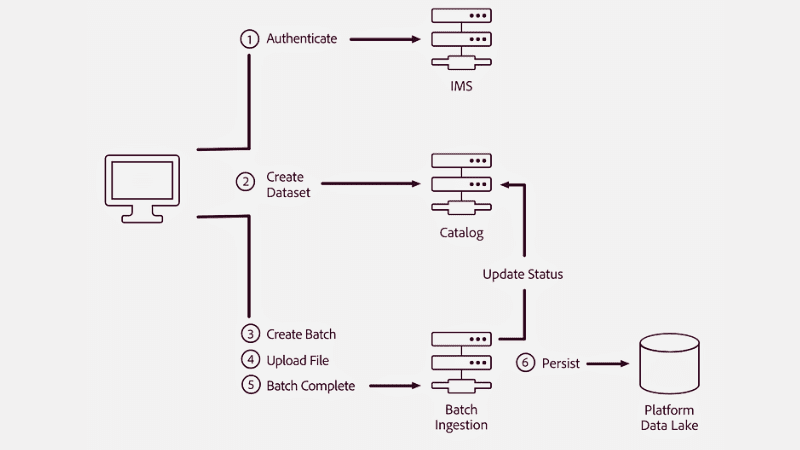 Kilde: Adobe Experience League
Kilde: Adobe Experience League
Det er den vanligste inntaksmetoden. Her samler og grupperer inntakslaget data som kommer fra flere kilder trinnvis. Den overfører deretter dataene i bunter til en applikasjon, et system eller et sted der det er nødvendig.
Overføringen av data er basert på aktivering av politiske forhold via triggerhendelser, analog bestilling eller eksisterende tidsplaner for å sikre at data overføres. Batchbehandling er nyttig for organisasjoner som trenger å samle spesifikke data hver dag med aktiviteter som krever oppmøteskjema, rapportgenerering osv.
Denne tilnærmingen er rimeligere og anses i mange tilfeller som en eldre tilnærming.
#2. Sanntidsdatainntak
Sanntidsdatainntak er også kjent som strømbehandling. Det innebærer innsamling og overføring av data fra en gitt kilde i sanntid til destinasjonen. Her er det ingen gruppering; i stedet vil du finne at data hentes, lastes og behandles så snart inntakslaget finner nye data.
For å implementere sanntidsdatainntak, er det en vanlig løsning kalt Change Data Structure (CDC). Denne typen datainntak er imidlertid dyrere enn batchinntak. Dette er fordi det krever at du overvåker kilder konstant for å gjenkjenne nye data og sikre at de reflekteres riktig i den målrettede plattformen.
Hvis du kutter kostnadsdelen, er denne metoden svært nyttig for selskaper som ønsker å kjøre analyser med ferske data hver gang for å ta operative beslutninger.
Hvis du for eksempel ønsker å ta beslutninger om aksjemarkedet, er sanntidsdatainntak det beste alternativet. Denne metoden er også nyttig for å overvåke infrastrukturen din.
#3. Lambda-basert datainntak
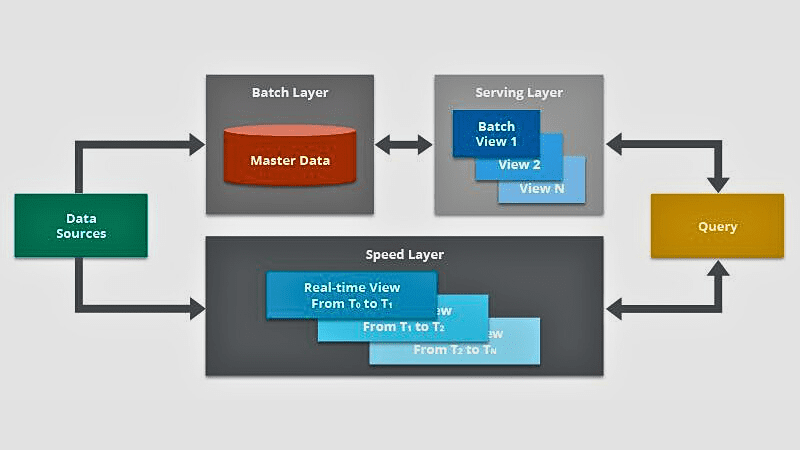 Kilde: Hasselcast
Kilde: Hasselcast
Denne metoden er kombinasjonen av to typer datainntak, dvs. batchbehandling og sanntidsinntak.
Batchbehandling brukes til å samle data i batcher, mens sanntidsdatainntak brukes for å gi en annen vinkel til tidssensitive data. Lambda-basert datainntak deler inn dataene den samler inn i grupper og tar dem inn i mindre trinn, noe som gjør den effektiv for ulike applikasjoner som trenger strømmedata.
Brukstilfeller av datainntak
Organisasjoner over hele verden bruker datainntaksprosesser som en viktig del av datapipelines i sin virksomhet.
- Internet of Things (IoT): Datainntak brukes i flere IoT-systemer for å samle inn og transformere data fra et bredt spekter av tilkoblede enheter.
- Big Data Analytics: Big Data Analytics er et vanlig krav for hver organisasjon. Inntak av store datavolumer fra mange kilder er derfor nødvendig i big data-analyse, der data blir behandlet med distribuerte systemer som Spark eller Hadoop.
- Svindeloppdagelse: Organisasjoner bruker datainntaksprosessen for å oppdage svindel ved å importere og transformere data fra forskjellige kilder. Dette inkluderer kundeatferd, tredjeparts datastrømmer og transaksjoner.
- Netthandel: Netthandelsbedrifter bruker datainntaksprosessen for å motta data fra flere kilder, for eksempel kundetransaksjoner, produktkataloger, nettstedsanalyse og mer. Dette hjelper dem å vokse seg større med riktig data i sanntid.
- Personalisering: Datainntaksprosessen kan brukes til å gi brukere tilpassede opplevelser eller anbefalinger ved å trekke ut data fra forskjellige kilder, for eksempel kundeinteraksjoner, sosiale mediedata, nettstedsanalyse, etc.
- Forsyningskjedestyring: For å administrere forsyningskjeden trenger en organisasjon data fra kilder som inventar, logistikk og leverandørdata. Datainntak tar inn disse dataene fra flere kilder og behandler dem for effektiv forsyningskjedestyring.
- Sentiment- og sosiale medier-analyse: Sanntidsdatainntak hjelper bedrifter med å overvåke sosiale medier, identifisere nye trender og analysere merkesentiment effektivt ved å samle inn data fra ulike kilder. Dette fører til forbedrede kunderelasjoner, utvikling av markedsfangststrategier og effektive markedsføringsstrategier.
Utfordringer

Du kan oppleve noen utfordringer med datainntaksprosessen:
- Skalerbarhet: Du kan finne problemer med å skalere et stort sett med data mens du inntar data fra forskjellige kilder. Mengden behandlet data krever vertikal eller horisontal skalering av infrastrukturen for å håndtere den økte belastningen, og derfor oppstår komplikasjoner.
- Datakvalitet: Datakvalitet er en stor utfordring i datainntaksprosessen. Når du trekker ut data, kan du ikke alltid sikre at dataene du mottar er av høy kvalitet.
- Variert økosystem: Det er mange datakilder og typer, noe som gjør det vanskelig for teamene dine å utvikle en lydtett inntaksmodell. Noen verktøy og funksjoner støtter bare grunnleggende teknologier, slik at organisasjoner kan bruke flere verktøy som krever flere ferdighetssett.
- Kostnad: Inntakskostnad er direkte proporsjonal med datavolumer. Etter hvert som virksomheten din i dataverdier vokser, øker også de samlede kostnadene for inntak. For å få inn alle dataene, trenger du flere servere og lagringssystemer, noe som fører til en økning i inntakskostnadene.
- Sikkerhet: Siden dataene lagres på mange punkter i rørledningen under inntak, er de utsatt for dataeksponering og sikkerhetsrisiko. Dette gjør datainntaksprosessen sårbar, noe som vil føre til sikkerhetsbrudd. Organisasjoner finner det derfor utfordrende å opprettholde etterlevelsesstandarder og forskrifter under prosessen.
- Dataintegrasjon: Du vil finne litt problemer med å integrere data fra tredjepartskilder med inntaksrørledningen. Dette er grunnen til at du trenger et omfattende verktøy som lar deg integrere data.
- Upålitelighet: Hvis du på en eller annen måte inntar data feil, kan det være utsatt for upålitelig tilkobling. Dette resulterer i forstyrrelse av kommunikasjonen og tap av data.
Beste praksis
La oss diskutere noen dataintegreringspraksis som du kan følge for å forbedre bedriftens ytelse.
Automatisert datainntak
Automatisert datainntak kan løse mange utfordringer som følger med manuell inntak. Den erkjenner vanskeligheten og uunngåeligheten ved å transformere rådata til nyttig innsikt, spesielt når dataene stammer fra flere forskjellige kilder.
Organisasjoner kan bruke datainntaksverktøy for å automatisere tilbakevendende prosesser for innsamling av data for bedre analyser og rapporter, noe som reduserer menneskelige feil.
Opprett data SLAer
Data SLAer krever:
- Hva en bedrift trenger
- Hvilke forventninger en virksomhet må ha til dataene
- Når data kan møte forventningene
- Hvem blir berørt
- Hvordan bør man vite når SLA er oppfylt og hva vil være responsen når den brytes?
Dermed hjelper datainntaksmetoden deg med å få alle nødvendige data for å lage data-SLA-er effektivt.
Nettverksbåndbredde
Datainntaksrørledningen kan bygges på en måte som kan håndtere nettverksbåndbredde effektivt.
Trafikken er ikke alltid konstant, noen ganger øker eller reduseres den basert på sosiale og fysiske parametre. Nettverksbåndbredden avhenger også av mengden data som skal tas inn på et bestemt tidspunkt.
Heterogene systemer og teknologier

En organisasjon må sjekke om pipelinemodellen for datainntak er kompatibel med tredjepartsverktøy og -applikasjoner samt ulike operativsystemer.
Støtte for upålitelige data
Datainntakspipelinen mottar data fra flere kilder og ulike strukturer som lydfiler, loggfiler, bilder og mange flere.
Ulike strukturer trenger forskjellige hastigheter, noe som gjør at et upålitelig nettverk kan gjøre hele rørledningen upålitelig. Organisasjoner må designe en datainntakspipeline som støtter alle formatene uten å være upålitelig.
Høy presisjon
Datainntaksprosessen er direkte proporsjonal med reviderbare data. Det krever en godt utformet prosess slik at den kan endre mellomfunksjonene basert på krav.
Streaming av data
Bedrifter krever sanntids- og batchbehandlingsprosesser for datainntak for å forbedre tjenestene sine og oppnå maksimal effektivitet.
Frakobling av databaser

Noen organisasjoner, spesielt store, integrerer analyse- eller business intelligence-databasen direkte med den operative databasen. Å koble fra de analytiske og operasjonelle databasene hjelper organisasjoner med å kaste problemene inn i hverandre.
Konklusjon
Datainntak gir umiddelbar innsikt slik at du kan forstå gjeldende markedstrender, opprettholde lav ventetid og måle kundeopplevelser. Datainntakspipelinen består av ulike lag som starter fra å trekke ut og samle inn data til å visualisere og analysere det.
Med datainntak kan organisasjoner enkelt forbedre driftseffektiviteten, utføre raskere svindeloppdagelse, få sanntidsanalyser og sette i gang proaktivt vedlikehold. Bedrifter kan også bruke sanntidsdatainntak for å få oppdatert informasjon og bruke den for konkurransefortrinn og informert beslutningstaking.
Du kan også lese om dataorkestrering på en enkel måte.