
En forvirringsmatrise er et verktøy for å evaluere ytelsen til klassifiseringstypen for overvåkede maskinlæringsalgoritmer.
Innholdsfortegnelse
Hva er en forvirringsmatrise?
Vi mennesker oppfatter ting annerledes – til og med sannhet og løgner. Det som kan virke som en 10 cm lang strek for meg, kan virke som en 9 cm strek for deg. Men den faktiske verdien kan være 9, 10 eller noe annet. Det vi tipper er den forutsagte verdien!
Hvordan den menneskelige hjernen tenker
Akkurat som hjernen vår bruker vår egen logikk for å forutsi noe, bruker maskiner forskjellige algoritmer (kalt maskinlæringsalgoritmer) for å komme frem til en forutsagt verdi for et spørsmål. Igjen kan disse verdiene være de samme eller forskjellige fra den faktiske verdien.
I en konkurransepreget verden vil vi gjerne vite om spådommen vår er riktig eller ikke for å forstå prestasjonene våre. På samme måte kan vi bestemme ytelsen til en maskinlæringsalgoritme etter hvor mange spådommer den gjorde riktig.
Så, hva er en maskinlæringsalgoritme?
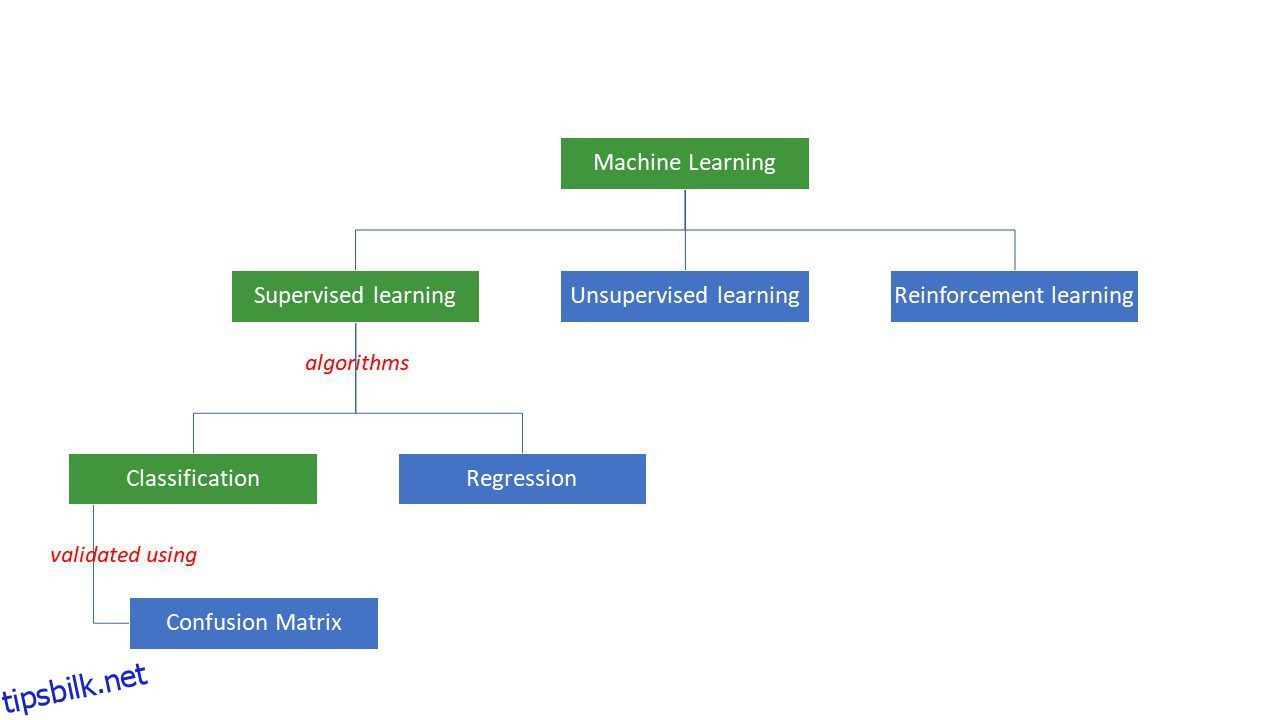
Maskiner prøver å komme frem til bestemte svar på et problem ved å bruke en viss logikk eller et sett med instruksjoner, kalt maskinlæringsalgoritmer. Maskinlæringsalgoritmer er av tre typer – overvåket, uovervåket eller forsterkning.
 Typer av maskinlæringsalgoritmer
Typer av maskinlæringsalgoritmer
De enkleste typene algoritmer overvåkes, der vi allerede vet svaret, og vi trener maskinene til å komme frem til det svaret ved å trene algoritmen med mye data – det samme som hvordan et barn vil skille mellom mennesker i forskjellige aldersgrupper ved å ser på funksjonene deres om og om igjen.
Overvåkede ML-algoritmer er av to typer – klassifisering og regresjon.
Klassifiseringsalgoritmer klassifiserer eller sorterer data basert på et sett med kriterier. For eksempel, hvis du vil at algoritmen din skal gruppere kunder basert på matpreferansene deres – de som liker pizza og de som ikke liker pizza, vil du bruke en klassifiseringsalgoritme som beslutningstre, tilfeldig skog, naive Bayes eller SVM (Support Vektormaskin).
Hvilken av disse algoritmene ville gjort den beste jobben? Hvorfor bør du velge den ene algoritmen fremfor den andre?
Gå inn i forvirringsmatrise…
En forvirringsmatrise er en matrise eller tabell som gir informasjon om hvor nøyaktig en klassifiseringsalgoritme er ved klassifisering av et datasett. Vel, navnet er ikke for å forvirre mennesker, men for mange ukorrekte spådommer betyr nok at algoritmen ble forvirret😉!
Så en forvirringsmatrise er en metode for å evaluere ytelsen til en klassifiseringsalgoritme.
Hvordan?
La oss si at du brukte forskjellige algoritmer på vårt tidligere nevnte binære problem: klassifiser (segregér) folk basert på om de liker eller ikke liker pizza. For å evaluere algoritmen som har verdier nærmest det riktige svaret, vil du bruke en forvirringsmatrise. For et binært klassifiseringsproblem (liker/misliker, sant/falsk, 1/0), gir forvirringsmatrisen fire rutenettverdier, nemlig:
- Sann positiv (TP)
- True Negative (TN)
- Falsk positiv (FP)
- Falsk negativ (FN)
Hva er de fire rutenettene i en forvirringsmatrise?
De fire verdiene bestemt ved bruk av forvirringsmatrisen danner rutenettene til matrisen.
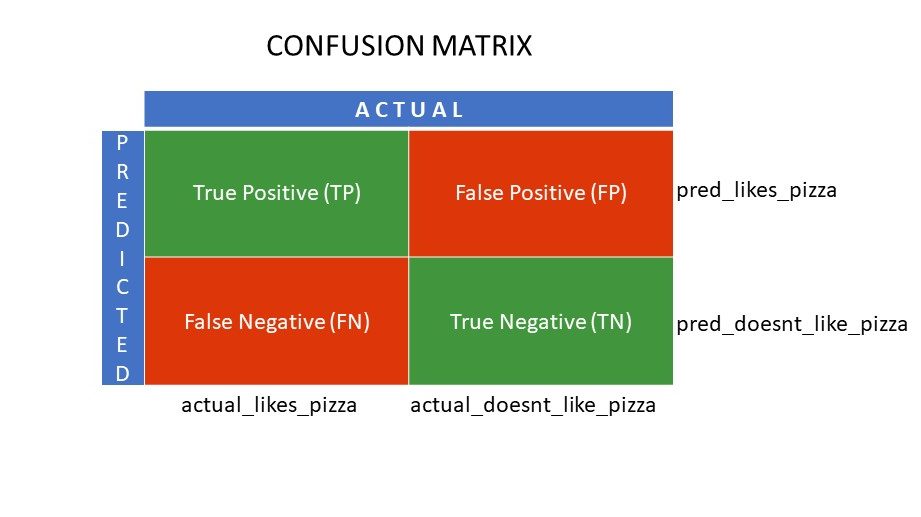 Forvirringsmatrisenett
Forvirringsmatrisenett
True Positive (TP) og True Negative (TN) er verdiene som er riktig forutsagt av klassifiseringsalgoritmen,
- TP representerer de som liker pizza, og modellen klassifiserte dem riktig,
- TN representerer de som ikke liker pizza, og modellen klassifiserte dem riktig,
Falsk Positiv (FP) og False Negative (FN) er verdiene som er feilaktig forutsagt av klassifikatoren,
- FP representerer de som ikke liker pizza (negativ), men klassifisereren spådde at de liker pizza (feil positivt). FP kalles også en type I-feil.
- FN representerer de som liker pizza (positivt), men klassifisereren spådde at de ikke gjør det (feilaktig negativ). FN kalles også Type II-feil.
For å forstå konseptet ytterligere, la oss ta et virkelighetsscenario.
La oss si at du har et datasett på 400 personer som gjennomgikk Covid-testen. Nå fikk du resultatene av forskjellige algoritmer som bestemte antall Covid-positive og Covid-negative personer.
Her er de to forvirringsmatrisene for sammenligning:
Ved å se på begge, kan du bli fristet til å si at den første algoritmen er mer nøyaktig. Men for å få et konkret resultat trenger vi noen beregninger som kan måle nøyaktigheten, presisjonen og mange andre verdier som beviser hvilken algoritme som er best.
Beregninger som bruker forvirringsmatrise og deres betydning
De viktigste beregningene som hjelper oss med å avgjøre om klassifisereren gjorde de riktige spådommene er:
#1. Tilbakekalling/sensitivitet
Recall eller Sensitivity eller True Positive Rate (TPR) eller Probability of Detection er forholdet mellom de riktige positive prediksjonene (TP) og de totale positive (dvs. TP og FN).
R = TP/(TP + FN)
Tilbakekalling er målet for korrekte positive resultater returnert av antall korrekte positive resultater som kunne ha blitt produsert. En høyere verdi på Recall betyr at det er færre falske negativer, noe som er bra for algoritmen. Bruk Recall når det er viktig å vite de falske negativene. For eksempel, hvis en person har flere blokkeringer i hjertet og modellen viser at han har det helt fint, kan det vise seg å være dødelig.
#2. Presisjon
Presisjon er et mål på de riktige positive resultatene av alle de positive resultatene som er forutsagt, inkludert både sanne og falske positive.
Pr = TP/(TP + FP)
Presisjon er ganske viktig når de falske positive er for viktige til å bli ignorert. For eksempel, hvis en person ikke har diabetes, men modellen viser det, og legen foreskriver visse medisiner. Dette kan føre til alvorlige bivirkninger.
#3. Spesifisitet
Spesifisitet eller True Negative Rate (TNR) er korrekte negative resultater funnet ut av alle resultatene som kunne vært negative.
S = TN/(TN + FP)
Det er et mål på hvor godt klassifisereren din identifiserer de negative verdiene.
#4. Nøyaktighet
Nøyaktighet er antallet korrekte spådommer av det totale antallet spådommer. Så hvis du fant 20 positive og 10 negative verdier riktig fra en prøve på 50, vil nøyaktigheten til modellen din være 30/50.
Nøyaktighet A = (TP + TN)/(TP + TN + FP + FN)
#5. Utbredelse
Prevalens er et mål på antall positive resultater oppnådd av alle resultatene.
P = (TP + FN)/(TP + TN + FP + FN)
#6. F Score
Noen ganger er det vanskelig å sammenligne to klassifiserere (modeller) med bare Precision og Recall, som bare er aritmetiske midler for en kombinasjon av de fire rutenettene. I slike tilfeller kan vi bruke F Score eller F1 Score, som er det harmoniske gjennomsnittet – som er mer nøyaktig fordi det ikke varierer for mye for ekstremt høye verdier. Høyere F-score (maks 1) indikerer en bedre modell.
F-poengsum = 2*Presisjon*Recall/ (Recall + Presisjon)
Når det er viktig å ta vare på både falske positive og falske negative, er F1-poengsummen en god beregning. For eksempel trenger de som ikke er covid-positive (men algoritmen viste det) ikke være unødvendig isolert. På samme måte må de som er Covid-positive (men algoritmen sa at de ikke er det) isoleres.
#7. ROC-kurver
Parametre som nøyaktighet og presisjon er gode beregninger hvis dataene er balansert. For et ubalansert datasett betyr høy nøyaktighet ikke nødvendigvis at klassifikatoren er effektiv. For eksempel kan 90 av 100 studenter i en gruppe spansk. Nå, selv om algoritmen din sier at alle 100 kan spansk, vil nøyaktigheten være 90 %, noe som kan gi et feil bilde av modellen. I tilfeller med ubalanserte datasett, er beregninger som ROC mer effektive bestemmere.
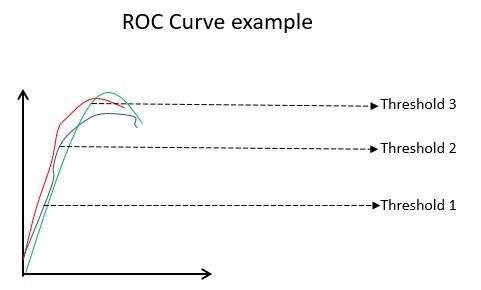 Eksempel på ROC-kurve
Eksempel på ROC-kurve
ROC (Receiver Operating Characteristic) kurve viser visuelt ytelsen til en binær klassifiseringsmodell ved ulike klassifiseringsterskler. Det er et plott av TPR (True Positive Rate) mot FPR (False Positive Rate), som beregnes som (1-spesifisitet) ved forskjellige terskelverdier. Verdien som er nærmest 45 grader (øverst til venstre) i plottet er den mest nøyaktige terskelverdien. Er terskelen for høy vil vi ikke ha mange falske positive, men vi vil få flere falske negative og omvendt.
Generelt, når ROC-kurven for ulike modeller plottes, anses den som har størst Area Under the Curve (AUC) som den bedre modellen.
La oss beregne alle de metriske verdiene for forvirringsmatrisene for klassifisering I og klassifisering II:
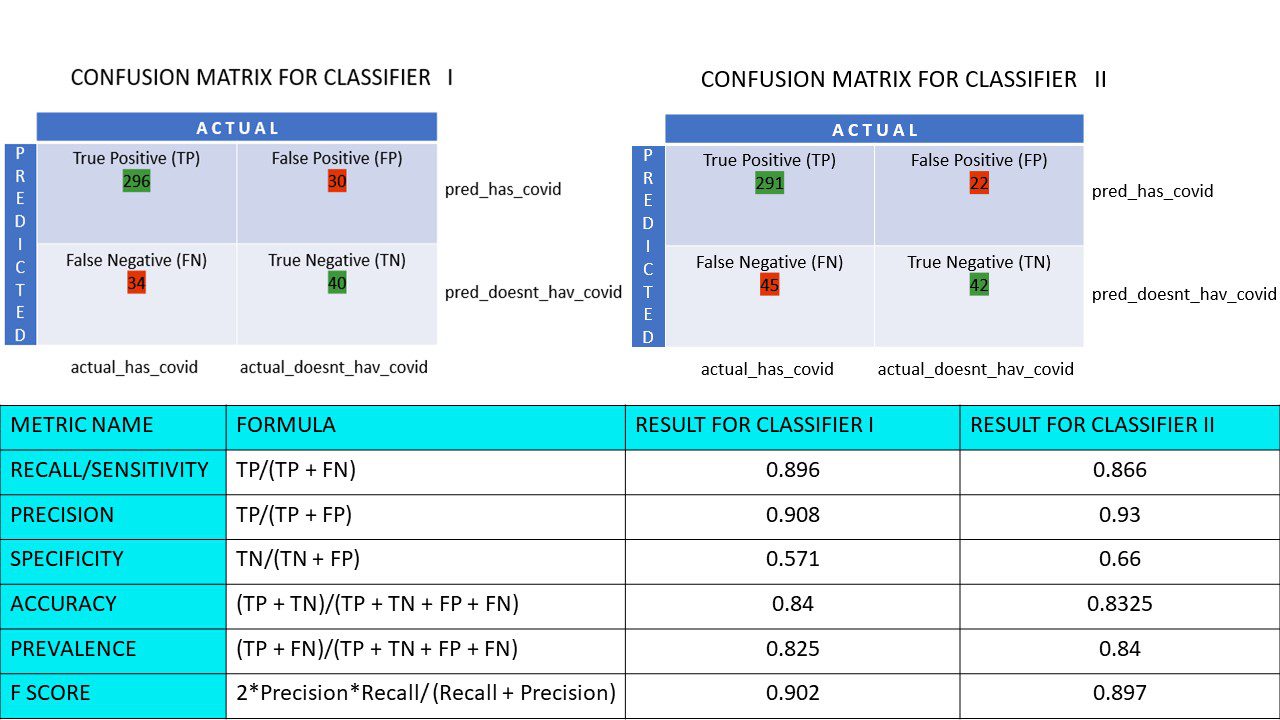 Metrisk sammenligning for klassifiserer 1 og 2 i pizzaundersøkelsen
Metrisk sammenligning for klassifiserer 1 og 2 i pizzaundersøkelsen
Vi ser at presisjonen er mer i klassifiserer II, mens nøyaktigheten er litt høyere i klassifiserer I. Basert på problemet kan beslutningstakere velge klassifiserer I eller II.
N x N forvirringsmatrise
Så langt har vi sett en forvirringsmatrise for binære klassifikatorer. Hva om det var flere kategorier enn bare ja/nei eller liker/misliker. For eksempel hvis algoritmen din skulle sortere bilder av røde, grønne og blå farger. Denne typen klassifisering kalles flerklasseklassifisering. Antall utdatavariabler bestemmer også størrelsen på matrisen. Så i dette tilfellet vil forvirringsmatrisen være 3×3.
 Forvirringsmatrise for en flerklasseklassifiser
Forvirringsmatrise for en flerklasseklassifiser
Sammendrag
En forvirringsmatrise er et flott evalueringssystem da det gir detaljert informasjon om ytelsen til en klassifiseringsalgoritme. Det fungerer bra for binære så vel som multi-klasse klassifiserere, der det er mer enn 2 parametere som skal tas vare på. Det er enkelt å visualisere en forvirringsmatrise, og vi kan generere alle de andre målene for ytelse som F Score, presisjon, ROC og nøyaktighet ved å bruke forvirringsmatrisen.
Du kan også se på hvordan du velger ML-algoritmer for regresjonsproblemer.