

Hvis du har lært noen dataprogrammeringsspråk, har du kanskje hørt begrepet, analysere tekst. Dette brukes til å forenkle de komplekse dataverdiene til filen. Artikkelen hjelper deg med å vite hvordan du analyserer tekst ved hjelp av språket. I tillegg til dette, hvis du har møtt feil i parsetekst x, vil du vite hvordan du fikser parsefeil i artikkelen.

Innholdsfortegnelse
Hvordan analysere tekst
I denne artikkelen har vi vist en fullstendig veiledning for å analysere tekst på ulike måter og også en kort introduksjon til å analysere tekst.
Hva er å analysere tekst?
Før du går i dybden for å lære konseptene med å analysere tekst ved å bruke hvilken som helst kode. Det er viktig å vite om det grunnleggende i språket og kodingen.
NLP eller Natural Language Processing
For å analysere tekst, brukes Natural Language Processing eller NLP, som er et underfelt av Artificial Intelligence-domenet. Python-språk, som er et av språkene som tilhører kategorien, brukes til å analysere tekst.
NLP-kodene gjør det mulig for datamaskiner å forstå og behandle menneskelige språk for å gjøre dem egnet for ulike applikasjoner. For å bruke ML- eller maskinlæringsteknikker på språket, må de ustrukturerte tekstdataene konverteres til strukturerte tabelldata. For å fullføre analyseaktiviteten brukes Python-språket til å endre programkodene.
Hva er å analysere tekst?
Å analysere tekst betyr ganske enkelt å konvertere dataene fra ett format til et annet format. Formatet som filen er lagret i skal analyseres eller konverteres til en fil i et annet format for å gjøre det mulig for brukeren å bruke den i ulike applikasjoner.
- Med andre ord betyr prosessen å analysere strengen eller en tekst og konvertere til logiske komponenter ved å endre formatet på filen.
- Noen regler for Python-språket brukes for å fullføre denne vanlige programmeringsoppgaven. Når tekst analyseres, blir den gitte tekstserien brutt ned i mindre komponenter.
Hva er grunnene til å analysere tekst?
Årsakene til at teksten må analyseres er gitt i denne delen, og det er en forutsetning for kunnskap før man vet hvordan man analyserer tekst.
- Alle datastyrte data vil ikke være i samme format og kan variere avhengig av ulike applikasjoner.
- Dataformatene varierer for ulike applikasjoner, og en inkompatibel kode vil føre til denne feilen.
- Det finnes ikke noe individuelt universelt dataprogram for å velge data for alle dataformatene.
Metode 1: Gjennom DataFrame Class
DataFrame-klassen til Python-språket har alle nødvendige funksjoner for å analysere tekst. Dette innebygde biblioteket inneholder de nødvendige kodene for å analysere data av ethvert format til et annet format.
Kort introduksjon av DataFrame Class
DataFrame Class er en funksjonsrik datastruktur, som brukes som et dataanalyseverktøy. Dette er et kraftig dataanalyseverktøy som kan brukes til å analysere data med minimal innsats.
- Koden leses inn i pandas DataFrame for å utføre analysen på Python-språket.
- Klassen kommer med en rekke pakker levert av pandaene som brukes av Python-dataanalytikere.
- Funksjonen til denne klassen er en abstraksjon, en kode der den interne funksjonaliteten til funksjonen er skjult for brukerne, av NumPy-biblioteket. NumPy-biblioteket er et python-bibliotek som omfatter kommandoene og funksjonene for å arbeide med matriser.
- DataFrame-klassen kan brukes til å gjengi en todimensjonal matrise med flere rad- og kolonneindekser. Disse indeksene hjelper til med å lagre flerdimensjonale data, og kalles derfor MultiIndex. Disse må endres for å vite hvordan man fikser parsefeil.
Pandaene til Python-språket hjelper til med å utføre SQL- eller database-stil operasjoner med den største perfeksjon for å unngå feil i parse tekst x. Den inneholder også noen IO-verktøy som hjelper til med å analysere filene til CSV, MS Excel, JSON, HDF5 og andre dataformater.
Prosess for å analysere tekst ved hjelp av DataFrame Class
For å vite hvordan du analyserer tekst, kan du bruke standardprosessen ved å bruke DataFrame-klassen gitt i denne delen.
- Dechiffrer dataformatet til inndataene.
- Bestem utdataene til dataene som CSV eller kommadelt verdi.
- Skriv på koden en primitiv datatype som liste eller dikt.
Merk: Å skrive koden på en tom DataFrame kan være kjedelig og komplisert. Pandaene tillater å lage data på DataFrame-klassen fra disse datatypene. Derfor kan dataene i den primitive datatypen enkelt analyseres til det nødvendige dataformatet.
- Analyser dataene ved hjelp av dataanalyseverktøyet, pandas DataFrame, og skriv ut resultatet.
Alternativ I: Standardformat
Standardmetoden for å formatere en fil med et bestemt dataformat som CSV er forklart her.
- Lagre filen med dataverdiene lokalt på din PC. Du kan for eksempel navngi filen data.txt.
- Importer filen i pandaer med et spesifikt navn og importer dataene til en annen variabel. For eksempel blir språkets pandaer importert til navnet pd i koden som er gitt.
- Importen skal ha en fullstendig kode med detaljene i navnet på inndatafilen, funksjonen og inndatafilformatet.
Merk: Her brukes variabelen med navnet res for å utføre lesefunksjonen til dataene i filen data.txt ved å bruke pandaene importert i pd. Dataformatet til inndatateksten er spesifisert i CSV-formatet.
- Kall den navngitte filtypen og analyser den analyserte teksten på det trykte resultatet. For eksempel vil kommandoen res etter kommandolinjekjøringen hjelpe til med å skrive ut den analyserte teksten.
Et eksempelkode for prosessen forklart ovenfor er gitt nedenfor og vil hjelpe deg med å forstå hvordan du analyserer tekst.
import pandas as pd res = pd.read_csv(‘data.txt’) res
I dette tilfellet, hvis du legger inn dataverdiene i filen data.txt som f.eks [1,2,3]vil den bli analysert og vist som 1 2 3.
Alternativ II: strengmetode
Hvis teksten som er gitt til koden bare inneholder strenger eller alfategn, kan spesialtegnene i strengen som komma, mellomrom osv. brukes til å skille og analysere teksten. Prosessen ligner på de vanlige interne strengoperasjonene. For å finne ut hvordan du fikser parsefeil, må du følge prosessen med å analysere teksten ved å bruke dette alternativet er forklart nedenfor.
- Dataene trekkes ut fra strengen og alle spesialtegnene som skiller teksten blir notert.
For eksempel, i koden gitt nedenfor, identifiseres spesialtegnene i strengen min_streng, som er «,» og «:». Denne prosessen må gjøres nøye for å unngå feil i parse tekst x.
- Teksten i strengen deles individuelt basert på verdiene og plasseringen til spesialtegnene.
For eksempel er strengen delt inn i tekstdataverdier basert på spesialtegnene som identifiseres ved hjelp av split-kommandoen.
- Dataverdiene til strengen skrives ut alene som den analyserte teksten. Her brukes print-setningen til å skrive ut den analyserte dataverdien til teksten.
Eksempelkoden for prosessen forklart ovenfor er gitt nedenfor.
my_string = ‘Names: Tech, computer’
sfinal = [name.strip() for name in my_string.split(‘:’)[1].split(‘,’)]
print(“Names: {}”.format(sfinal))
I dette tilfellet vil resultatet av den analyserte strengen vises som vist nedenfor.
Names: [‘Tech’, ‘computer’]
For å få bedre klarhet og vite hvordan man analyserer tekst mens man bruker strengteksten, brukes en for-løkke og koden endres som følger.
my_string = ‘Names: Tech, computer’
s1 = my_string.split(‘:’)
s2 = s1[1]
s3 = s2.split(‘,’)
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print(“Step {}: {}”.format(idx, item))
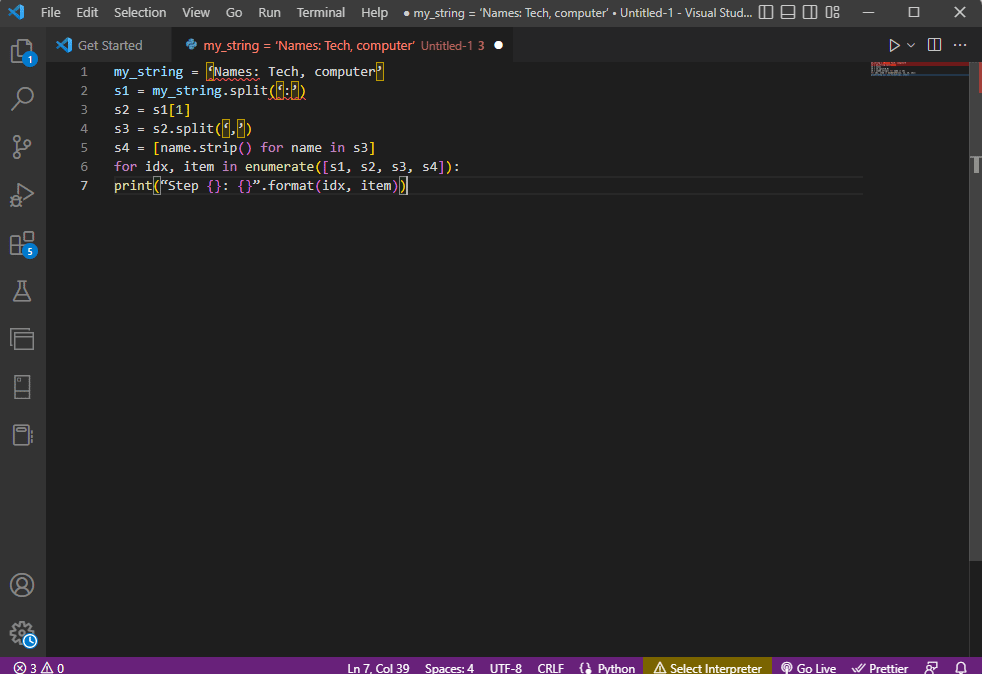
Resultatet av den analyserte teksten for hvert av disse trinnene vises som gitt nedenfor. Du kan merke deg at i trinn 0 er strengen separert basert på spesialtegnet : og tekstdataverdiene er separert basert på tegnet i ytterligere trinn.
Step 0: [‘Names’, ‘Tech, computer’] Step 1: Tech, computer Step 2: [‘ Tech’, ‘ computer’] Step 3: [‘Tech’, ‘computer’]
Alternativ III: Parsing av kompleks fil
I de fleste tilfeller inneholder fildataene som må analyseres, forskjellige datatyper og dataverdier. I dette tilfellet kan det være vanskelig å analysere filen ved å bruke metodene forklart tidligere.
Funksjonene ved å analysere de komplekse dataene i filen er å få dataverdiene til å vises i et tabellformat.
- Tittelen eller metadataene til verdiene skrives ut øverst i filen,
- Variablene og feltene skrives ut i utdataene i tabellform, og
- Dataverdiene danner en sammensatt nøkkel.
Før du fordyper deg i å lære hvordan du analyserer tekst i denne metoden, er det nødvendig å lære noen grunnleggende konsepter. Parsingen av dataverdiene gjøres basert på regulære uttrykk eller Regex.
Regex-mønstre
For å vite hvordan du fikser parsefeil, må du sørge for at regex-mønstrene i uttrykkene er riktige. Koden for å analysere dataverdiene til strengene vil involvere de vanlige Regex-mønstrene som er oppført nedenfor i denne delen.
-
«d» : samsvarer med desimaltallet i strengen,
-
«s» : samsvarer med mellomromstegn,
-
«w»: samsvarer med det alfanumeriske tegnet,
-
«+» eller «*»: utfører en grådig match ved å matche ett eller flere tegn i strengene,
-
«a-z»: samsvarer med små bokstaver i tekstdataverdiene,
-
«A-Z» eller «a-z» : samsvarer med gruppene med store og små bokstaver i strengen, og
-
«0-9» : samsvarer med de numeriske verdiene.
Vanlig uttrykk
Regelmessige uttrykksmoduler er en stor del av panda-pakken i Python-språket, og feil re kan føre til en feil i analysere tekst x. Det er et lite språk innebygd i Python for å finne strengmønsteret i uttrykket. Regulære uttrykk eller Regex er strenger med spesiell syntaks. Den lar brukeren matche mønstre i andre strenger basert på verdiene i strengene.
Regex opprettes basert på datatypen og kravet til uttrykket i strengen, for eksempel «String = (.*)n. Regex brukes før mønsteret i hvert uttrykk. Symbolene som brukes i de regulære uttrykkene er oppført nedenfor og vil hjelpe deg med å vite hvordan du analyserer tekst.
-
. : for å hente et hvilket som helst tegn fra dataene,
-
* : bruk null eller flere data fra forrige uttrykk,
-
(.*) : for å gruppere en del av det regulære uttrykket innenfor parentes,
-
n : Lag et nytt linjetegn på slutten av linjen i koden,
-
d : lag en kort integralverdi i området 0 til 9,
-
+ : bruk en eller flere data fra forrige uttrykk, og
-
| : lag et logisk utsagn; brukt for eller uttrykk.
RegexObjects
RegexObject er en returverdi for kompileringsfunksjonen og brukes til å returnere et MatchObject hvis uttrykket samsvarer med samsvarsverdien.
1. MatchObject
Siden den boolske verdien til MatchObject alltid er True, kan du bruke en if-setning for å identifisere de positive samsvarene i objektet. Ved bruk av if-setningen, brukes gruppen som refereres til av indeksen for å finne samsvaret til objektet i uttrykket.
-
group() returnerer én eller flere undergrupper av samsvar,
-
gruppe(0) returnerer hele kampen,
-
gruppe(1) returnerer den første undergruppen i parentes, og
- Mens vi refererer til flere grupper, bør vi bruke en python-spesifikk utvidelse. Denne utvidelsen brukes til å spesifisere navnet på gruppen der treffet skal finnes. Den spesifikke utvidelsen er gitt i gruppen i parentes. For eksempel vil uttrykket (?P
regex1) referere til den spesifikke gruppen med navnet group1 og se etter samsvar i det regulære uttrykket, regex1. For å lære hvordan du fikser parsefeil, må du sjekke om gruppen er pekt riktig.
2. Metoder for MatchObject
Mens du finner hvordan du analyserer tekst, er det viktig å vite at MatchObject har to grunnleggende metoder som er oppført nedenfor. Hvis MatchObject blir funnet i det spesifiserte uttrykket, vil det returnere sin forekomst, ellers vil det returnere Ingen.
- Match(string)-metoden brukes til å finne samsvarene til strengen i begynnelsen av det regulære uttrykket, og
- Søk(streng)-metoden brukes til å skanne gjennom strengen for å finne plasseringen for et samsvar i det regulære uttrykket.
Regulære uttrykksfunksjoner
Regex-funksjoner er kodelinjer som brukes til å utføre en bestemt funksjon som spesifisert av brukeren fra settet med dataverdier som er anskaffet.
Merk: For å skrive funksjonene brukes råstrenger for regulære uttrykk for å unngå feil i parse tekst x. Dette gjøres ved å legge til subscript r før hvert mønster i uttrykket.
De vanlige funksjonene som brukes i uttrykkene er forklart nedenfor.
1. re.findall()
Denne funksjonen returnerer alle mønstrene i strengen hvis et samsvar blir funnet, og returnerer en tom liste hvis det ikke finnes noe samsvar. For eksempel funksjonen, string = re.findall(«[aeiou]», regex_filename) brukes til å finne vokalforekomsten i filnavnet.
2. re.split()
Denne funksjonen brukes til å dele strengen i tilfelle et samsvar med et tegn spesifisert som mellomrom er funnet. I tilfelle ingen samsvar blir funnet, returnerer den en tom streng.
3. re.sub()
Funksjonen erstatter den matchede teksten med innholdet i den gitte erstatningsvariabelen. I motsetning til andre funksjoner, hvis det ikke finnes noe mønster, returneres den opprinnelige strengen.
4. re.search()
En av de grunnleggende funksjonene for å hjelpe til med å lære å analysere tekst er søkefunksjonen. Det hjelper med å søke etter mønsteret i strengen og returnere matchobjektet. Hvis søket mislykkes med å identifisere samsvaret, returneres ingen verdi.
5. re.compile(pattern)
Denne funksjonen brukes til å kompilere regulære uttrykksmønstre til et RegexObject, som ble diskutert tidligere.
Andre krav
De oppførte kravene er en tilleggsfunksjon som brukes av avanserte programmerere i dataanalyse.
- For å visualisere det regulære uttrykket brukes regexper, og
- For å teste det regulære uttrykket brukes regex101.
Prosess for å analysere tekst
Metoden for å analysere teksten i dette komplekse alternativet er beskrevet som gitt nedenfor.
- Det fremste trinnet er å forstå inndataformatet ved å lese innholdet i filen. For eksempel brukes funksjonene with open og read() til å åpne og lese innholdet i filen som heter sample. Eksempelfilen har innholdet fra filen file.txt; for å lære hvordan du fikser parsefeil, må filen leses fullstendig.
- Innholdet i filen skrives ut for å analysere dataene manuelt for å finne ut metadataene til verdiene. Her brukes print()-funksjonen til å skrive ut innholdet i eksempelfilen.
- De nødvendige datapakkene for å analysere teksten importeres til koden og et navn gis til klassen for videre koding. Her importeres regulære uttrykk og pandaer.
- De regulære uttrykkene som kreves for koden er definert i filen ved å inkludere regex-mønsteret og regex-funksjonen. Dette lar tekstobjektet eller korpuset ta koden for dataanalyse.
- For å vite hvordan du analyserer tekst, kan du referere til eksempelkoden gitt her. Compile()-funksjonen brukes til å kompilere strengen fra gruppen stringname1 til filfilnavnet. Funksjonen for å se etter samsvar i regex brukes av kommandoen ief_parse_line(line),
- Linjeparser for koden skrives ved å bruke def_parse_file(filepath), der den definerte funksjonen sjekker for alle regex-treffene i den spesifiserte funksjonen. Her søker regex search()-metoden etter nøkkelen rx i filfilnavnet og returnerer nøkkelen og samsvaret til det første samsvarende regex. Ethvert problem med trinnet kan føre til en feil i parse tekst x.
- Det neste trinnet er å skrive en filparser ved å bruke filparserfunksjonen, som er def_parse_file(filbane). En tom liste opprettes for å samle inn dataene til koden, som data = []samsvaret sjekkes på hver linje etter samsvar = _parse_line(line), og de eksakte verdidataene returneres basert på datatypen.
- For å trekke ut tall og verdi for tabellen, brukes kommandoen line.strip().split(«,»). Kommandoen rad{} brukes til å lage en ordbok med dataraden. Data.append(row)-kommandoen brukes til å forstå dataene og analysere dem til et tabellformat.
Kommandoen data = pd.DataFrame(data) brukes til å lage en pandas DataFrame fra dict-verdiene. Alternativt kan du bruke følgende kommandoer for det respektive formålet som angitt nedenfor.
-
data.sett_indeks([‘string’, ‘integer’]inplace=True) for å angi indeksen til tabellen.
-
data = data.groupby(level=data.index.names).first() for å konsolidere og fjerne nans.
-
data = data.apply(pd.to_numeric, errors=’ignore») for å oppgradere poengsum fra flytende til heltallsverdi.
Det siste trinnet for å vite hvordan man analyserer tekst er å teste parseren ved å bruke if-setningen ved å tilordne verdiene til en variabel data og skrive den ut ved å bruke print(data)-kommandoen.
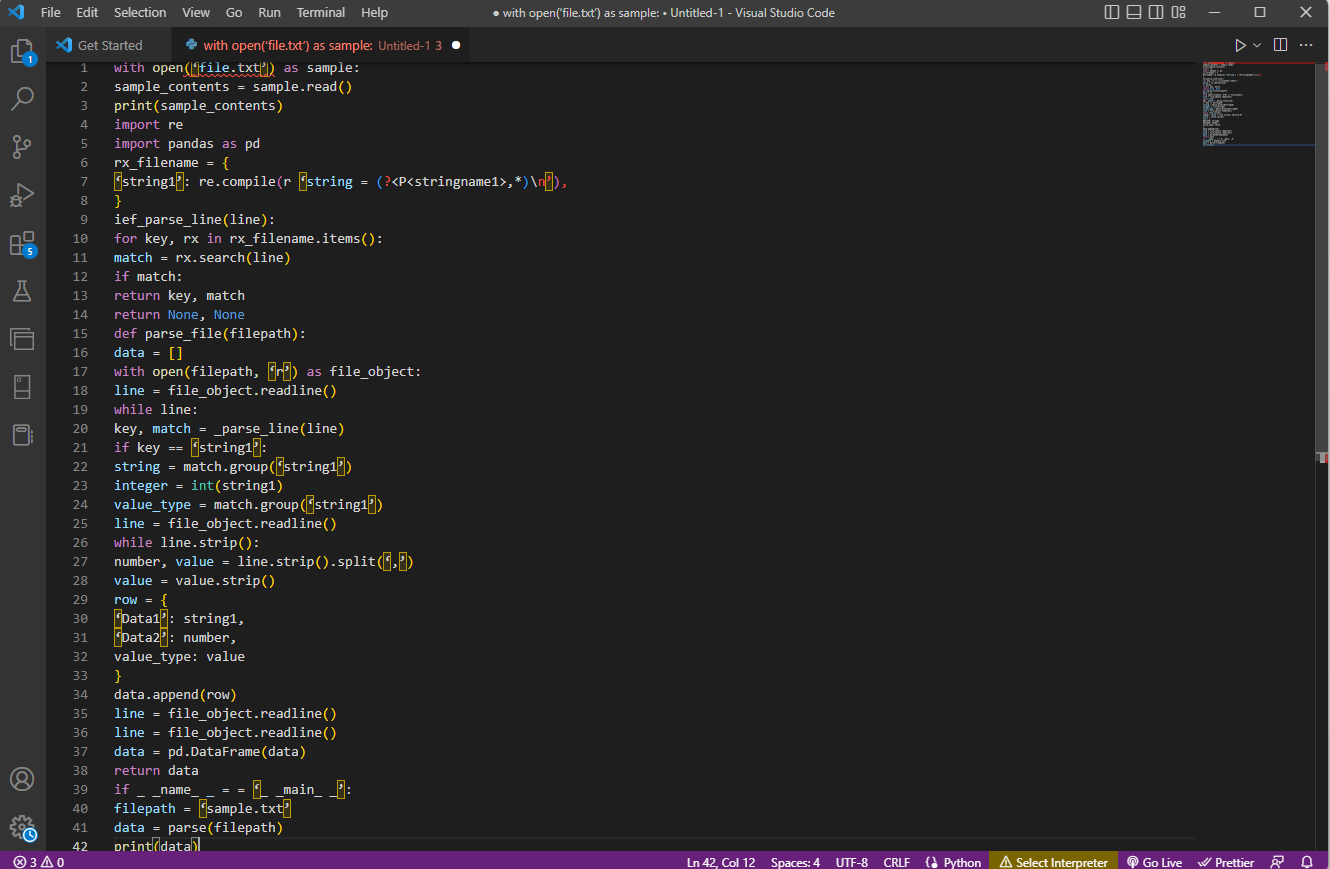
Eksempelkoden for forklaringen ovenfor er gitt her.
with open(‘file.txt’) as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
‘string1’: re.compile(r ‘string = (?<P<stringname1>,*)n’),
}
ief_parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, ‘r’) as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == ‘string1’:
string = match.group(‘string1’)
integer = int(string1)
value_type = match.group(‘string1’)
line = file_object.readline()
while line.strip():
number, value = line.strip().split(‘,’)
value = value.strip()
row = {
‘Data1’: string1,
‘Data2’: number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if _ _name_ _ = = ‘_ _main_ _’:
filepath = ‘sample.txt’
data = parse(filepath)
print(data)
Metode 2: Gjennom Word Tokenization
Prosessen med å konvertere en tekst eller et korpus til tokens eller mindre deler basert på visse regler kalles Tokenization. For å lære hvordan du fikser parsefeil, er det viktig å analysere ordtokeniseringskommandoene i koden. I likhet med regex, kan egne regler opprettes i denne metoden, og den hjelper i tekstforbehandlingsoppgaver som å kartlegge deler av tale. Også aktiviteter som å finne og matche vanlige ord, rense tekst og gjøre dataene klare for avanserte tekstanalyseteknikker som sentimentanalyse utføres i denne metoden. Hvis tokeniseringen er feil, kan det oppstå feil i parsetekst x.
Ntlk bibliotek
Prosessen tar hjelp av det populære språkverktøykassebiblioteket kalt nltk, som har et rikt sett med funksjoner for å utføre mange NLP-jobber. Disse kan lastes ned gjennom Pip- eller Pip-installasjonspakkene. For å vite hvordan du analyserer tekst, kan du bruke basispakken til Anaconda-distribusjonen som inkluderer biblioteket som standard.
Former for tokenisering
De vanlige formene for denne metoden er ordtokenisering og setningstokenisering. På grunn av symbolet på ordnivå, skriver førstnevnte bare ett ord én gang, mens sistnevnte skriver ut ordet på setningsnivå.
Prosess for å analysere tekst
- ntlk toolkit-biblioteket importeres og tokeniseringsskjemaene importeres fra biblioteket.
- En streng er gitt og kommandoene for å utføre tokeniseringen er gitt.
- Mens strengen skrives ut, vil utgangen være datamaskin er ordet.
- Når det gjelder ordtokenisering eller word_tokenize(), skrives hvert av ordene i setningen ut individuelt innenfor » og er atskilt med komma. Utdata for kommandoen vil være «datamaskinen», «er», «det», «ordet», «.»
- I tilfelle av setningstokenisering eller sent_tokenize(), plasseres de individuelle setningene innenfor » og ordrepetisjon er tillatt. Utdata for kommandoen vil være «datamaskin er ordet.»
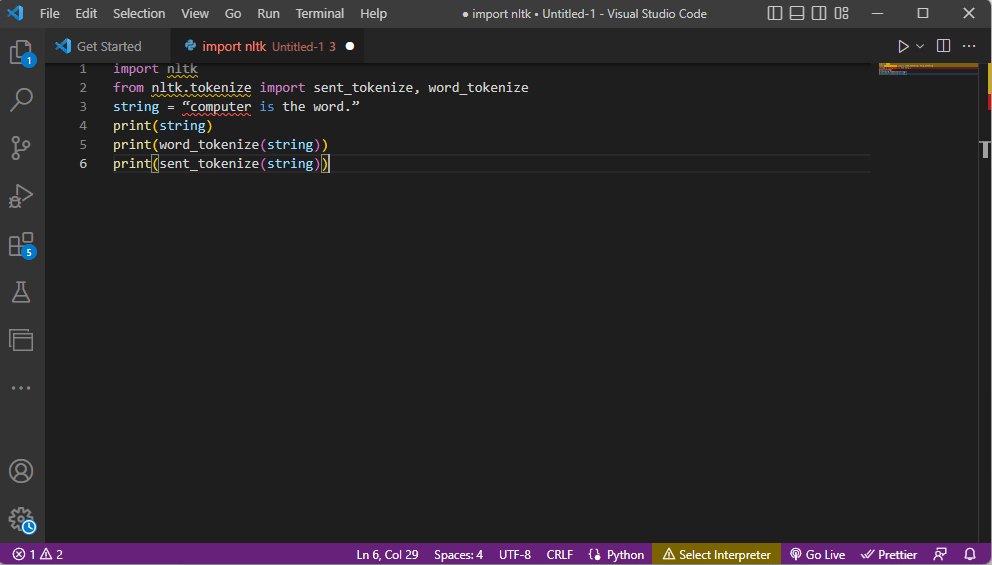
Koden som forklarer trinnene for tokenisering ovenfor, er gitt her.
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = “computer is the word.” print(string) print(word_tokenize(string)) print(sent_tokenize(string))
Metode 3: Gjennom DocParser Class
I likhet med DataFrame Class, kan Class DocParser brukes til å analysere teksten i koden. Klassen lar deg kalle parse-funksjonen med filbanen.
Prosess for å analysere tekst
For å vite hvordan du analyserer tekst ved å bruke DocParser-klassen, følg instruksjonene nedenfor.
- Get_format(filnavn)-funksjonen brukes til å trekke ut filtypen, returnere den til en angitt variabel for funksjonen og sende den til neste funksjon. For eksempel vil p1 = get_format(filnavn) trekke ut filtypen til filnavn, sette den til variabelen p1 og sende den til neste funksjon.
- En logisk struktur med andre funksjoner er konstruert ved å bruke if-elif-else-setningene og funksjonene.
- Hvis filtypen er gyldig og strukturen er logisk, brukes get_parser-funksjonen til å analysere dataene i filbanen og returnere strengobjektet til brukeren.
Merk: For å vite hvordan du fikser parsefeil, må denne funksjonen implementeres riktig.
- Parsingen av dataverdiene gjøres med filtypen til filen. Den konkrete implementeringen av klassen, som er parse_txt eller parse_docx, brukes til å generere strengobjekter fra delene av den gitte filtypen.
- Parsingen kan gjøres for filer med andre lesbare utvidelser som parse_pdf, parse_html og parse_pptx.
- Dataverdiene og grensesnittet kan importeres til applikasjoner med importsetninger og instansiere et DocParser-objekt. Dette kan gjøres ved å analysere filer på Python-språket, for eksempel parse_file.py. Denne operasjonen må gjøres nøye for å unngå feil i parse tekst x.
Metode 4: Gjennom Parse Text Tool
Tekstverktøyet Parse brukes til å trekke ut spesifikke data fra variabler og tilordne dem til andre variabler. Dette er uavhengig av andre verktøy som brukes i en oppgave, og BPA-plattformverktøyet brukes til å konsumere og sende ut variabler. Bruk lenken som er gitt her for å få tilgang til Parse Text Tool online og bruk svarene gitt tidligere om hvordan du analyserer tekst.
Metode 5: Gjennom TextFieldParser (Visual Basic)
TextFieldParser brukte objekter til å analysere og behandle svært store filer som er strukturert og avgrenset. Bredden og kolonnen med tekst som loggfiler eller eldre databaseinformasjon kan brukes i denne metoden. Parsemetoden ligner på å iterere koden over en tekstfil og brukes hovedsakelig til å trekke ut tekstfelt som ligner på strengmanipuleringsmetoder. Dette gjøres for å tokenisere avgrensede strenger og felt med forskjellige bredder ved å bruke det definerte skilletegnet som komma eller tabulatormellomrom.
Funksjoner for å analysere tekst
Følgende funksjoner kan brukes til å analysere teksten i denne metoden.
- For å definere et skilletegn, brukes SetDelimiters. Kommandoen testReader.SetDelimiters (vbTab) brukes for eksempel til å angi tabulatorplass som skilletegn.
- For å sette en feltbredde til en positiv heltallsverdi til en fast feltbredde for tekstfiler, kan du bruke kommandoen testReader.SetFieldWidths (integer).
- For å teste felttypen til teksten, kan du bruke følgende kommando testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth.
Metoder for å finne MatchObject
Det er to grunnleggende metoder for å finne MatchObject i koden eller den analyserte teksten.
- Den første metoden er å definere formatet og gå gjennom filen ved å bruke ReadFields-metoden. Denne metoden vil hjelpe til med å behandle hver linje i koden.
- PeekChars-metoden brukes til å sjekke hvert felt individuelt før du leser det, definere flere formater og reagere.
I begge tilfeller, hvis et felt ikke samsvarer med det spesifiserte formatet mens du utfører parsing eller finner hvordan du analyserer tekst, returneres et MalformedLineException-unntak.
Proff-tips: Hvordan analysere tekst gjennom MS Excel
Som en siste og enkel metode for å analysere teksten, kan du bruke MS Excel app som en parser for å lage tabulator- og kommadelte filer. Dette vil hjelpe med å krysssjekke med det analyserte resultatet og hjelpe til med å finne hvordan du kan fikse parsefeil.
1. Velg dataverdiene i kildefilen og trykk Ctrl + C-tastene samtidig for å kopiere filen.
2. Åpne Excel-appen ved å bruke søkefeltet i Windows.
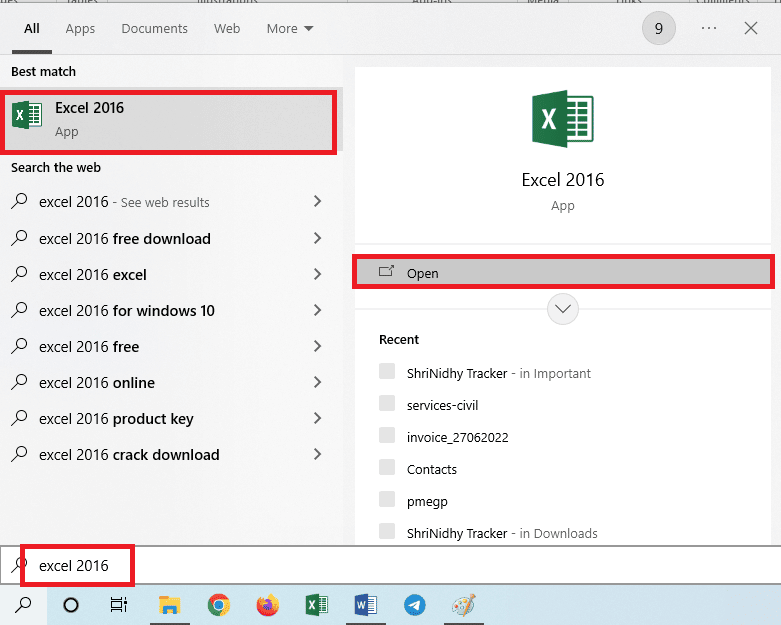
3. Klikk på A1-cellen og trykk på Ctrl + V-tastene samtidig for å lime inn den kopierte teksten.
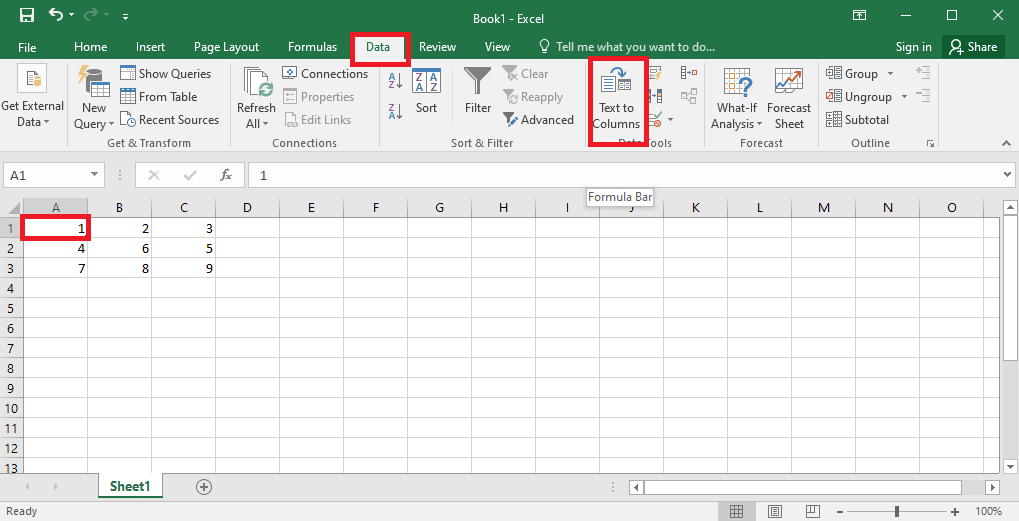
4. Velg A1-cellen, naviger til kategorien Data, og klikk på alternativet Tekst til kolonner i delen Dataverktøy.
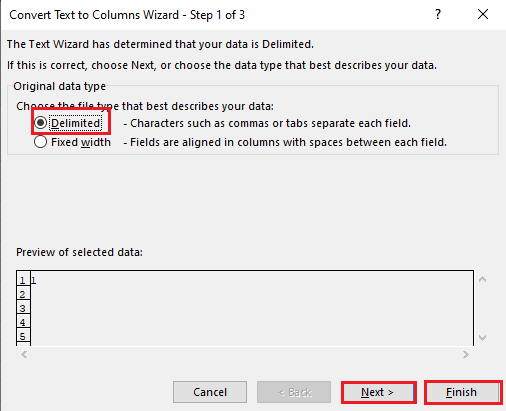
5A. Velg alternativet Delimited hvis et komma eller tabulator mellomrom brukes som skilletegn, og klikk på Neste og Fullfør-knappene.
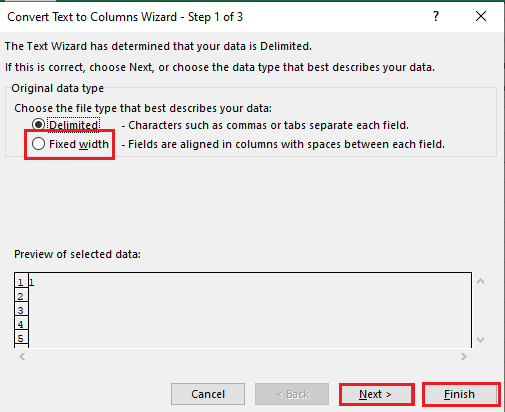
5B. Velg alternativet Fast bredde, tilordne en verdi for skilletegn, og klikk på Neste og Fullfør-knappene.
Hvordan fikse parsefeil
Feil i parse tekst x kan oppstå på Android-enheter som, Parse Error: Det var et problem med å analysere pakken. Dette skjer vanligvis når appen ikke klarer å installere fra Google Play-butikken eller mens du kjører en tredjepartsapp.
Feilteksten x kan oppstå hvis listen over tegnvektorer er loopet og andre funksjoner danner en lineær modell for beregning av dataverdiene. Feilmeldingen er Error in parse(text = x, keep.source = FALSE):
Du kan lese artikkelen om hvordan du fikser parsefeil på Android for å lære årsakene og metodene for å fikse feilen.
Bortsett fra løsningene i veiledningen, kan du prøve følgende rettelser.
- Laste ned .apk-filen på nytt eller gjenopprette navnet på filen.
- Gjenopprette endringer i Androidmanifest.xml-filen, hvis du har programmeringskunnskaper på ekspertnivå.
***
Artikkelen hjelper deg med å lære hvordan du analyserer tekst og lærer hvordan du fikser parsefeil. Fortell oss hvilken metode som hjalp til med å fikse feil i parse tekst x og hvilken metode for parsing som er foretrukket. Del dine forslag og spørsmål i kommentarfeltet nedenfor.