
Apache Parquet gir flere fordeler for datalagring og gjenfinning sammenlignet med tradisjonelle metoder som CSV.
Parkettformat er designet for raskere databehandling av komplekse typer. I denne artikkelen snakker vi om hvordan Parkett-formatet passer for dagens stadig voksende databehov.
Før vi graver i detaljene i Parquet-format, la oss forstå hva CSV-data er og utfordringene det utgjør for datalagring.
Innholdsfortegnelse
Hva er CSV-lagring?
Vi har alle hørt mye om CSV (Comma Separated Values) – en av de vanligste måtene å organisere og formatere data på. CSV-datalagring er radbasert. CSV-filer lagres med filtypen .csv. Vi kan lagre og åpne CSV-data ved hjelp av Excel, Google Sheets eller et hvilket som helst tekstredigeringsprogram. Dataene er lett synlige når filen er åpnet.
Vel, det er ikke bra – definitivt ikke for et databaseformat.
Videre, ettersom datavolumet vokser, blir det vanskelig å spørre, administrere og hente.
Her er et eksempel på data som er lagret i en .CSV-fil:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions
Hvis vi ser det i Excel, kan vi se en rad-kolonne struktur som nedenfor:
Utfordringer med CSV-lagring
Radbaserte lagringer som CSV er egnet for opprettelse, oppdatering og sletting.
Hva med Read in CRUD, da?
Se for deg en million rader i .csv-filen ovenfor. Det vil ta rimelig tid å åpne filen og søke etter dataene du leter etter. Ikke så kult. De fleste skyleverandører som AWS tar betalt for selskaper basert på mengden data som er skannet eller lagret – igjen, CSV-filer bruker mye plass.
CSV-lagring har ikke et eksklusivt alternativ til å lagre metadata, noe som gjør dataskanning til en kjedelig oppgave.
Så, hva er den kostnadseffektive og optimale løsningen for å utføre alle CRUD-operasjonene? La oss utforske.
Hva er Parkett datalagring?
Parkett er et åpen kildekode-lagringsformat for å lagre data. Det er mye brukt i Hadoop- og Spark-økosystemer. Parkettfiler lagres som .parquet-utvidelse.
Parkett er et svært strukturert format. Den kan også brukes til å optimalisere komplekse rådata som finnes i bulk i datainnsjøer. Dette kan redusere spørretiden betydelig.
Parkett gjør datalagring effektiv og gjenfinning raskere på grunn av en blanding av rad- og søylebaserte (hybrid) lagringsformater. I dette formatet er dataene partisjonert horisontalt så vel som vertikalt. Parkettformat eliminerer også parsing-overhead i stor grad.
Formatet begrenser det totale antallet I/O-operasjoner og til syvende og sist kostnadene.
Parkett lagrer også metadataene, som lagrer informasjon om data som dataskjema, antall verdier, plassering av kolonner, min verdi, maks verdi antall radgrupper, type koding osv. Metadataene lagres på ulike nivåer i filen , noe som gjør datatilgang raskere.
I radbasert tilgang som CSV, tar datahenting tid ettersom spørringen må navigere gjennom hver rad og hente de spesielle kolonneverdiene. Med Parkettoppbevaring kan alle de nødvendige søylene nås samtidig.
Oppsummert,
- Parkett er basert på søylestrukturen for datalagring
- Det er et optimalisert dataformat for å lagre komplekse data i bulk i lagringssystemer
- Parkettformat inkluderer ulike metoder for datakomprimering og koding
- Det reduserer dataskanningstid og spørretid betydelig og tar mindre diskplass sammenlignet med andre lagringsformater som CSV
- Minimerer antall IO-operasjoner, reduserer kostnadene for lagring og utførelse av spørringer
- Inkluderer metadata som gjør det lettere å finne data
- Gir åpen kildekode-støtte
Dataformat for parkett
Før vi går inn på et eksempel, la oss forstå hvordan data lagres i Parkett-formatet mer detaljert:
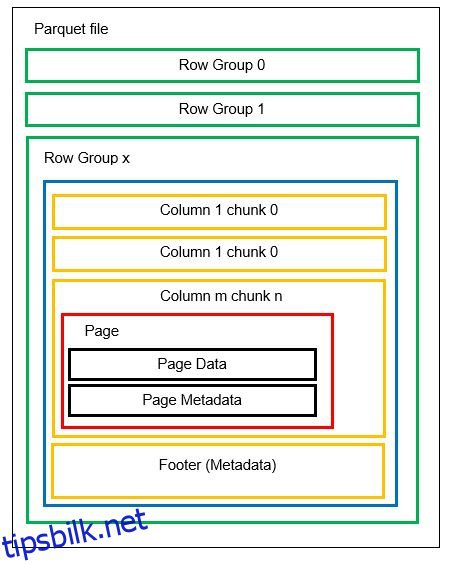
Vi kan ha flere horisontale partisjoner kjent som radgrupper i én fil. Innenfor hver radgruppe brukes vertikal partisjonering. Kolonnene er delt opp i flere kolonnebiter. Dataene lagres som sider inne i kolonneklumpene. Hver side inneholder de kodede dataverdiene og metadataene. Som vi nevnte tidligere, lagres metadata for hele filen også i bunnteksten til filen på radgruppenivå.
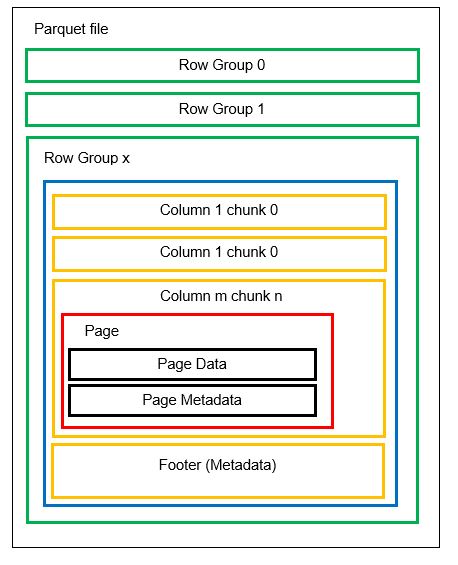
Siden dataene er delt inn i kolonnebiter, er det også enkelt å legge til nye data ved å kode de nye verdiene inn i en ny del og fil. Metadataene oppdateres deretter for de berørte filene og radgruppene. Dermed kan vi si at Parkett er et fleksibelt format.
Parkett støtter naturlig komprimering av data ved hjelp av sidekomprimering og ordbokkodingsteknikker. La oss se et enkelt eksempel på ordbokkomprimering:
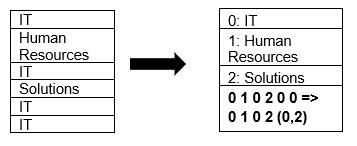
Merk at i eksemplet ovenfor ser vi IT-divisjonen 4 ganger. Så mens du lagrer i ordboken, koder formatet dataene med en annen lett å lagre verdi (0,1,2…) sammen med antall ganger de gjentas kontinuerlig – IT, IT endres til 0,2 for å lagre mer plass. Å søke etter komprimerte data tar kortere tid.
Head-to-head sammenligning
Nå som vi har en god idé om hvordan CSV- og Parkett-formatene ser ut, er det på tide med litt statistikk for å sammenligne begge formatene:
CSV
Parkett
Radbasert lagringsformat.
En hybrid av radbaserte og kolonnebaserte lagringsformater.
Det bruker mye plass siden ingen standard komprimeringsalternativ er tilgjengelig. For eksempel vil en 1TB-fil oppta samme plass når den lagres på Amazon S3 eller en annen sky.
Komprimerer data under lagring, og bruker dermed mindre plass. En 1 TB fil lagret i Parkett-format vil kun ta opp 130 GB plass.
Kjøretiden for spørringen er treg på grunn av det radbaserte søket. For hver kolonne må hver rad med data hentes.
Spørretiden er omtrent 34 ganger raskere på grunn av kolonnebasert lagring og tilstedeværelse av metadata.
Flere data må skannes per spørring.
Omtrent 99 % mindre data skannes for utførelse av spørringen, og optimaliserer dermed ytelsen.
De fleste lagringsenheter lader basert på lagringsplassen, så CSV-format betyr høye lagringskostnader.
Mindre lagringskostnader da data lagres i komprimert, kodet format.
Filskjema må enten utledes (som fører til feil) eller leveres (kjedelig).
Filskjemaet er lagret i metadataene.
Formatet passer for enkle datatyper.
Parkett er egnet selv for komplekse typer som nestede skjemaer, matriser, ordbøker.
Konklusjon 👩💻
Vi har sett gjennom eksempler at Parkett er mer effektivt enn CSV når det gjelder kostnader, fleksibilitet og ytelse. Det er en effektiv mekanisme for å lagre og hente data, spesielt når hele verden beveger seg mot skylagring og plassoptimalisering. Alle store plattformer som Azure, AWS og BigQuery støtter parkettformat.