

Llama 2 er en åpen kildekode stor språkmodell (LLM) utviklet av Meta. Det er en kompetent åpen kildekode stor språkmodell, uten tvil bedre enn noen lukkede modeller som GPT-3.5 og PaLM 2. Den består av tre forhåndstrente og finjusterte generative tekstmodellstørrelser, inkludert 7 milliarder, 13 milliarder og 70 milliarder parametermodeller.
Du vil utforske Llama 2s samtaleevner ved å bygge en chatbot ved å bruke Streamlit og Llama 2.
Innholdsfortegnelse
Forstå Llama 2: Funksjoner og fordeler
Hvor forskjellig er Llama 2 fra forgjengerens store språkmodell, Llama 1?
- Større modellstørrelse: Modellen er større, med opptil 70 milliarder parametere. Dette gjør det mulig å lære mer intrikate assosiasjoner mellom ord og setninger.
- Forbedrede samtaleevner: Reinforcement Learning from Human Feedback (RLHF) forbedrer samtaleapplikasjonsevner. Dette gjør at modellen kan generere menneskelignende innhold selv i kronglete interaksjoner.
- Raskere inferens: Den introduserer en ny metode som kalles grouped-query oppmerksomhet for å akselerere inferens. Dette resulterer i dens evne til å bygge mer nyttige applikasjoner som chatbots og virtuelle assistenter.
- Mer effektiv: Den er mer minne- og beregningsressurseffektiv enn forgjengeren.
- Åpen kildekode og ikke-kommersiell lisens: Den er åpen kildekode. Forskere og utviklere kan bruke og endre Llama 2 uten begrensninger.
Llama 2 overgår forgjengeren betydelig på alle måter. Disse egenskapene gjør det til et potent verktøy for mange applikasjoner, for eksempel chatbots, virtuelle assistenter og naturlig språkforståelse.
Sette opp et strømbelyst miljø for Chatbot-utvikling
For å begynne å bygge applikasjonen din, må du sette opp et utviklingsmiljø. Dette er for å isolere prosjektet fra de eksisterende prosjektene på maskinen din.
Først, start med å lage et virtuelt miljø ved å bruke Pipenv-biblioteket som følger:
pipenv shell
Installer deretter de nødvendige bibliotekene for å bygge chatboten.
pipenv install streamlit replicate
Streamlit: Det er et åpen kildekode-nettapprammeverk som gjengir maskinlærings- og datavitenskapsapplikasjoner raskt.
Repliker: Det er en skyplattform som gir tilgang til store maskinlæringsmodeller med åpen kildekode for distribusjon.
Få ditt Llama 2 API-token fra replikat
For å få en replikert tokennøkkel, må du først registrere en konto på Gjenskape ved å bruke din GitHub-konto.
Når du har åpnet dashbordet, naviger til Utforsk-knappen og søk etter Llama 2-chat for å se llama-2–70b-chat-modellen.
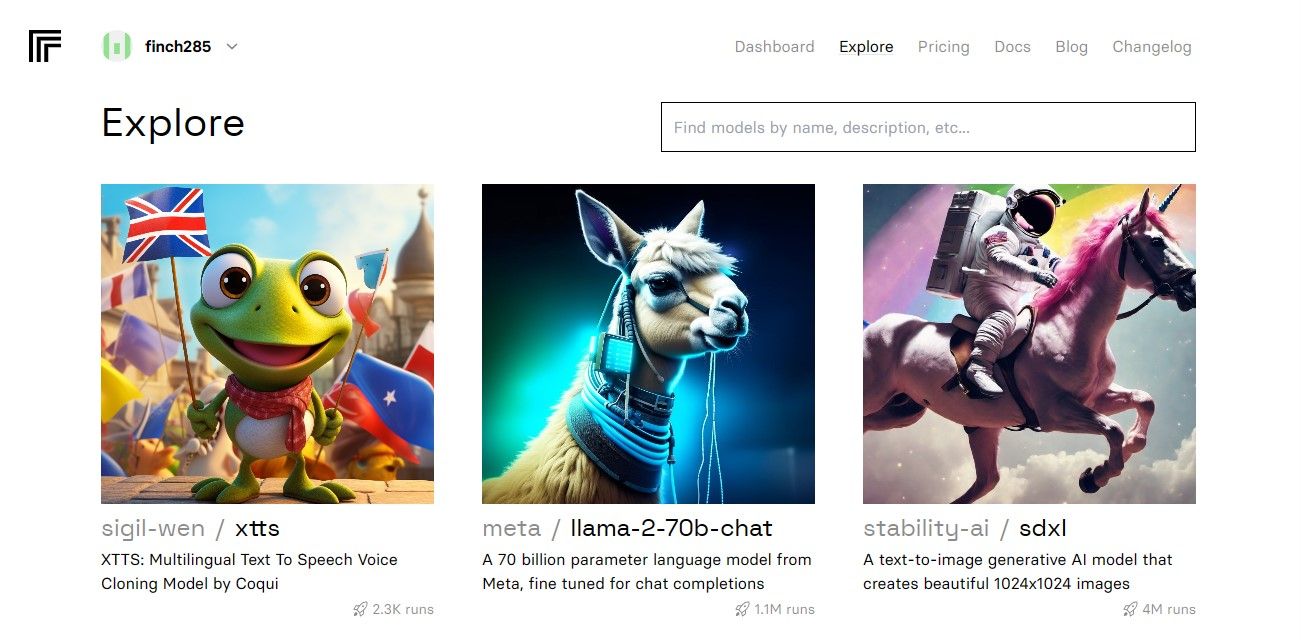
Klikk på llama-2–70b-chat-modellen for å se Llama 2 API-endepunktene. Klikk på API-knappen på llama-2–70b-chat-modellens navigasjonslinje. På høyre side av siden klikker du på Python-knappen. Dette vil gi deg tilgang til API-tokenet for Python-applikasjoner.
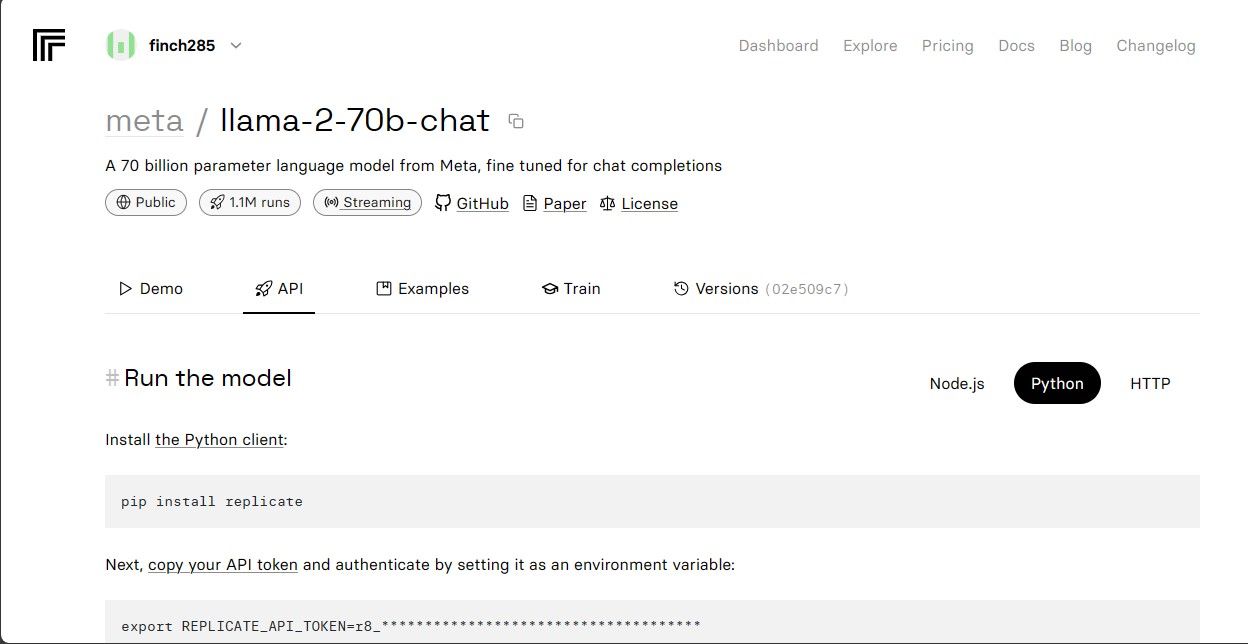
Kopier REPLICATE_API_TOKEN og oppbevar den trygt for fremtidig bruk.
Bygge Chatbot
Først oppretter du en Python-fil kalt llama_chatbot.py og en env-fil (.env). Du vil skrive koden din i llama_chatbot.py og lagre de hemmelige nøklene og API-tokenene dine i .env-filen.
På filen llama_chatbot.py importerer du bibliotekene som følger.
import streamlit as st
import os
import replicate
Deretter setter du de globale variablene for llama-2–70b-chat-modellen.
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default="")
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default="")
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default="")
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default="")
På .env-filen legger du til repliker-tokenet og modellendepunkter i følgende format:
REPLICATE_API_TOKEN='Paste_Your_Replicate_Token'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'
Lim inn replikeringstokenet ditt og lagre .env-filen.
Utforming av chatbotens samtaleflyt
Lag en forhåndsmelding for å starte Llama 2-modellen avhengig av hvilken oppgave du vil at den skal gjøre. I dette tilfellet vil du at modellen skal fungere som assistent.
PRE_PROMPT = "You are a helpful assistant. You do not respond as " \
"'User' or pretend to be 'User'." \
" You only respond once as Assistant."
Sett opp sidekonfigurasjonen for chatboten din som følger:
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)
Skriv en funksjon som initialiserer og setter opp sesjonstilstandsvariabler.
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPTdef setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'Choose a LLaMA2 model:', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)
Funksjonen setter de essensielle variablene som chat_dialogue, pre_prompt, llm, top_p, max_seq_len og temperatur i økttilstanden. Den håndterer også valget av Llama 2-modellen basert på brukerens valg.
Skriv en funksjon for å gjengi sidefeltinnholdet i Streamlit-appen.
def render_sidebar():
st.sidebar.header("LLaMA2 Chatbot")
st.session_state['temperature'] = st.sidebar.slider('Temperature:',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P:', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('Max Sequence Length:',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'Prompt before the chat starts. Edit here if desired:',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt + "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPT
Funksjonen viser overskriften og innstillingsvariablene til Llama 2 chatbot for justeringer.
Skriv funksjonen som gjengir chatloggen i hovedinnholdsområdet til Streamlit-appen.
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])
Funksjonen itererer gjennom chat_dialogue lagret i sesjonstilstanden, og viser hver melding med den tilsvarende rollen (bruker eller assistent).
Håndter brukerens innspill ved hjelp av funksjonen nedenfor.
def handle_user_input():
user_input = st.chat_input(
"Type your question here to talk to LLaMA2"
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)
Denne funksjonen gir brukeren et inndatafelt der de kan legge inn meldinger og spørsmål. Meldingen legges til chat_dialogue i økttilstanden med brukerrollen når brukeren sender meldingen.
Skriv en funksjon som genererer svar fra Llama 2-modellen og viser dem i chatteområdet.
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "User" if dict_message["role"] == "user" else "Assistant"
string_dialogue += f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue + "Assistant: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response += item
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})
Funksjonen oppretter en samtaleloggstreng som inkluderer både bruker- og assistentmeldinger før den kaller opp debounce_replicate_run-funksjonen for å få assistentens svar. Den endrer kontinuerlig responsen i brukergrensesnittet for å gi en chat-opplevelse i sanntid.
Skriv hovedfunksjonen som er ansvarlig for å gjengi hele Streamlit-appen.
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()
Den kaller alle de definerte funksjonene for å sette opp sesjonstilstanden, gjengi sidefeltet, chattehistorikk, håndtere brukerinndata og generere assistentsvar i en logisk rekkefølge.
Skriv en funksjon for å starte render_app-funksjonen og start applikasjonen når skriptet er utført.
def main():
render_app()if __name__ == "__main__":
main()
Nå skal søknaden din være klar for utførelse.
Håndtering av API-forespørsler
Lag en utils.py-fil i prosjektkatalogen din og legg til funksjonen nedenfor:
import replicate
import time
last_call_time = 0
debounce_interval = 2def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("last call time: ", last_call_time)current_time = time.time()
elapsed_time = current_time - last_call_timeif elapsed_time < debounce_interval:
print("Debouncing")
return "Hello! Your requests are too fast. Please wait a few" \
" seconds before sending another request."last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt + "Assistant: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return output
Funksjonen utfører en debounce-mekanisme for å forhindre hyppige og overdrevne API-spørringer fra en brukers input.
Deretter importerer du debounce response-funksjonen til filen llama_chatbot.py som følger:
from utils import debounce_replicate_run
Kjør applikasjonen nå:
streamlit run llama_chatbot.py
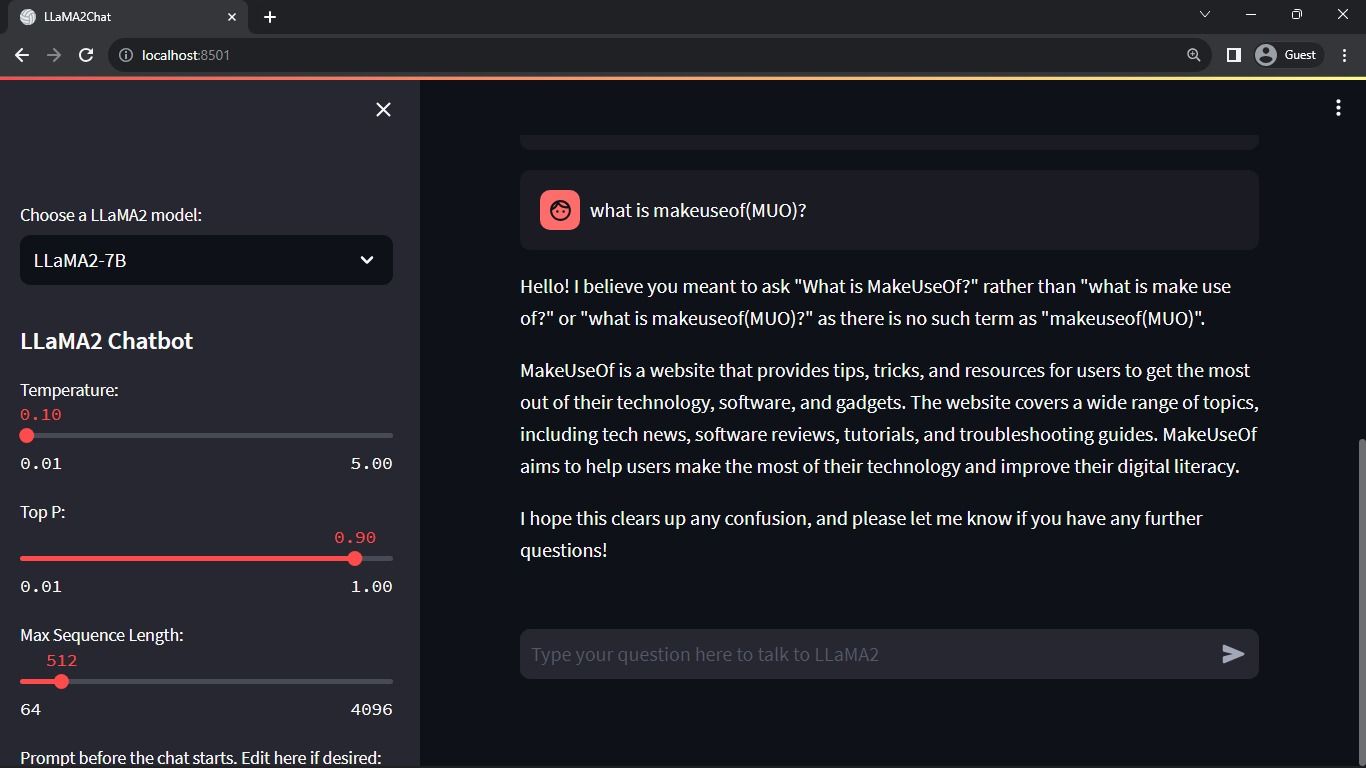
Forventet utgang:
Utgangen viser en samtale mellom modellen og et menneske.
Virkelige applikasjoner av Streamlit og Llama 2 Chatbots
Noen virkelige eksempler på Llama 2-applikasjoner inkluderer:
- Chatbots: Bruken gjelder for å lage menneskelig respons chatbots som kan holde sanntidssamtaler om flere emner.
- Virtuelle assistenter: Bruken gjelder for å lage virtuelle assistenter som forstår og svarer på spørsmål på menneskelig språk.
- Språkoversettelse: Bruken gjelder for språkoversettelsesoppgaver.
- Tekstoppsummering: Bruken kan brukes til å oppsummere store tekster til korte tekster for enkel forståelse.
- Forskning: Du kan bruke Llama 2 til forskningsformål ved å svare på spørsmål på tvers av en rekke emner.
Fremtiden til AI
Med lukkede modeller som GPT-3.5 og GPT-4 er det ganske vanskelig for små aktører å bygge noe av substans ved hjelp av LLM-er siden tilgang til GPT-modellens API kan være ganske dyrt.
Å åpne opp avanserte store språkmodeller som Llama 2 for utviklerfellesskapet er bare begynnelsen på en ny æra av AI. Det vil føre til mer kreativ og innovativ implementering av modellene i virkelige applikasjoner, noe som fører til et akselerert kappløp mot å oppnå kunstig superintelligens (ASI).