
Named Entity Recognition (NER) tilbyr en flott måte å forstå en gitt tekstinformasjon og identifisere spesifikke enheter eller tagger i den for ulike applikasjoner.
Fra å kategorisere folks navn til å angi datoer, organisasjoner, steder og mer, gjør NER sin egen vei for en bedre forståelse av språk.
Mange organisasjoner håndterer et stort datavolum i form av innhold, personlig informasjon, tilbakemeldinger fra kunder, produktdetaljer og mye mer.
Når du trenger informasjon umiddelbart, må du utføre søkeoperasjoner for å få resultatet, noe som kan ta mye tid, energi og ressurser, spesielt når du arbeider med store datavolumer.
For å gi organisasjoner en effektiv løsning for søkeoperasjoner og finne de riktige dataene, er NER et utmerket alternativ.
I denne artikkelen vil jeg diskutere NER i detalj, dets matematiske konsept, dets forskjellige bruksområder og andre viktige punkter.
La oss begynne!
Innholdsfortegnelse
Hva er navngitt enhetsgjenkjenning?
Named Entity Recognition (NER) er en metode for Natural Language Processing (NLP) som kan identifisere og klassifisere enheter innenfor tekstlige, ustrukturerte data.
Disse enhetene inneholder et bredt spekter av informasjon, for eksempel organisasjoner, lokasjoner, navn på enkeltpersoner, numeriske verdier, datoer og mer. Det gir maskiner mulighet til å trekke ut de ovennevnte enhetene, noe som gjør det til et nyttig verktøy for applikasjoner som oversettelse, svare på spørsmål, etc., på tvers av flere bransjer.
 Kilde: Skaler
Kilde: Skaler
Så, NER søker å lokalisere og kategorisere de forskjellige enhetene i en ustrukturert tekst i forhåndsdefinerte grupper som organisasjoner, medisinske koder, mengder, personnavn, prosenter, pengeverdier, tidsuttrykk og mer.
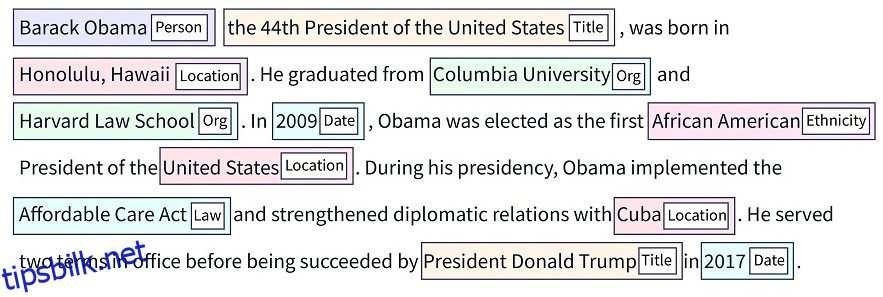
La oss forstå dette med et eksempel:
[William] kjøpte eiendom av [Z1 Corp.] i [2023]. Her er blokkene enhetene identifisert av NER. De er klassifisert som:
- William – Navnet på en person
- Z1 Corp. – Organisasjon
- 2003 – Tid
NER brukes i flere felt av AI, inkludert dyp læring, maskinlæring (ML) og nevrale nettverk. Det er en kritisk komponent i NLP-systemer, for eksempel sentimentanalyseverktøy, søkemotorer og chatbots. I tillegg kan den brukes i økonomi, kundestøtte, høyere utdanning, helsevesen, menneskelige ressurser og sosiale medier.
Enkelt sagt, NER identifiserer, klassifiserer og trekker ut den essensielle informasjonen fra den ustrukturerte teksten uten noen menneskelig analyse. Den kan trekke ut nøkkelinformasjon raskt fra det tilgjengelige settet med store data.
Videre leverer NER viktig innsikt til organisasjonen din om produktene, markedstrender, kunder og konkurranse. For eksempel bruker helseinstitusjoner NER til å trekke ut viktige medisinske data fra pasientjournaler. Mange selskaper bruker det til å identifisere om de er nevnt i noen publikasjoner.
Nøkkelbegreper: NER

Det er viktig å kjenne til de grunnleggende konseptene som er involvert i NER. La oss diskutere noen nøkkelbegreper knyttet til NER for å bli kjent med.
- Navngitt enhet: Ethvert ord som refererer til et sted, organisasjon, person eller annen enhet.
- Korpus: En samling av ulike tekster som brukes til å analysere språk og trene NER-modeller.
- POS-tagging: En prosess der teksten merkes i henhold til tilsvarende tale, for eksempel adjektiver, verb og substantiv.
- Chunking: Det er en prosess som brukes til å gruppere ord i forskjellige meningsfulle fraser basert på den syntaktiske strukturen og orddelen.
- Trenings- og testdata: Dette er prosessen som brukes til å trene en modell med merkede data og evaluere ytelsen til det første settet på et annet sett med data.
Bruk av NER i NLP

NER har flere applikasjoner i NLP, for eksempel sentimentanalyse, anbefalingssystemer, svar på spørsmål, informasjonsutvinning og mer.
- Sentimentanalyse: NER brukes til å oppdage følelsen uttrykt i en setning eller paragraf mot en bestemt navngitt enhet, som et produkt eller en tjeneste. Disse dataene brukes til å forbedre kundeopplevelsen og identifisere forbedringsområdene.
- Anbefalingssystemer: NER brukes til å identifisere brukernes preferanser og interesser basert på de navngitte enhetene nevnt i online-interaksjonene eller søkene. Disse dataene brukes til å forbedre brukerforbedringer ved å gi personlige anbefalinger.
- Spørsmålssvar: NER brukes til å oppdage visse enheter fra en tekst, som videre brukes til å svare på en spørring eller et spesifikt spørsmål. Dette brukes vanligvis for virtuelle assistenter og chatbots.
- Informasjonsutvinning: NER brukes til å trekke ut viktig informasjon fra et større sett med ustrukturert tekst. Dette inkluderer innlegg på sosiale medier, anmeldelser på nettet, nyhetsartikler og mer. Disse dataene brukes til å generere verdifull innsikt og ta datadrevne beslutninger.
Matematiske begreper: NER
NER-prosessen inkluderer forskjellige matematiske konsepter, som maskinlæring, dyp læring, sannsynlighetsteori og mer. Her er noen matematiske teknikker:
- Skjulte Markov-modeller: Skjulte Markov-modeller eller HMM-er er en statistisk tilnærming for sekvensering av klassifiseringsoppgaver, for eksempel NER. Det innebærer å representere en sekvens av ord i teksten som forskjellige tilstander, der hver stat representerer en bestemt navngitt enhet. Ved å analysere sannsynlighetene kan du identifisere de navngitte enhetene fra teksten.
- Dyplæring: Dyplæringsteknikker som nevrale nettverk brukes i NER-oppgaver. Dette lar deg identifisere og kategorisere navngitte enheter effektivt og nøyaktig.
- Betingede tilfeldige felt: Disse kommer under en grafisk modell som brukes i sekvensmerkingsoppgaver. De tilbyr betinget sannsynlighetsmodellering av hver tag som inneholder ordsekvensen. Dette lar deg identifisere de navngitte enhetene i en tekst.
Hvordan fungerer NER?
 Kilde: ACS-publikasjoner
Kilde: ACS-publikasjoner
Named Entity Recognition (NER) fungerer som et uttrekk av informasjon. Dens funksjon er delt inn i forskjellige nøkkeltrinn:
#1. Forbehandle teksten
I det første trinnet innebærer NER utarbeidelse av tekstinformasjon for analyse. Det involverer vanligvis oppgaver som tokenisering. Her delte teksten seg først opp i tokens før NER begynte å identifisere enheter.
For eksempel kan «Bill Gates grunnla Microsoft» deles inn i forskjellige tokens som «Bill», «Gates», «grunnlagt» og «Microsoft».
#2. Identifiser enheter
Potensielle navngitte enheter kan oppdages ved å bruke statistiske metoder eller språklige regler. Dette trinnet involverer mønstergjenkjenning, for eksempel spesifikke formater (datoer), eller bruk av store bokstaver i navn («Bill Gates»). Når forbehandlingsfunksjonen er fullført, skanner NER-algoritmer teksten for å identifisere ord i sekvensene som tilsvarer enhetene.
#3. Klassifiser enheter
Etter at NER har identifisert enhetene, kategoriserer den disse anerkjente enhetene i typer, klasser eller grupper. De vanlige kategoriene er organisasjon, dato, sted, person og mer. Dette oppnås ved hjelp av maskinlæringsmodeller som er trent på merkede data.
For eksempel vil «Bill Gates» bli anerkjent som en «person» og «Microsoft» som en «organisasjon».
#4. Kontekstuell analyse
NER stopper aldri ved å gjenkjenne og klassifisere enheter. Den vurderer ofte konteksten for å øke nøyaktigheten. Dette trinnet vurderer konteksten der enhetene vises, og gir nøyaktig kategorisering.
For eksempel «Bill Gates grunnla Microsoft». Her lar konteksten systemene identifisere «Bill» som navnet på en person og ikke regningen for en betaling.
#5. Etterbehandling
Etter innledende identifikasjon og kategorisering er etterbehandling nødvendig for å avgrense de endelige resultatene. Dette innebærer å løse tvetydigheter, bruke kunnskapsbaser, slå sammen multi-token-enheter og mer for å forbedre enhetsdata.
Den fantastiske delen av NER er at den har evnen til å tolke og forstå ustrukturert tekst, som inneholder de nødvendige dataene for virksomheten din. Den mottar en viktig del av data fra nyhetsartikler, nettsider, forskningsartikler, innlegg på sosiale medier og mer.
Ved å gjenkjenne og kategorisere navngitte enheter, tilfører NER et ekstra lag med mening og struktur til tekstlandskapet.
Metoder for NER

De mest brukte metodene er følgende:
#1. Veiledet maskinlæringsbasert metode
Denne metoden bruker maskinlæringsmodeller som er trent på tekster som er forhåndsmerket av mennesker med navngitte enhetskategorier.
Denne tilnærmingen bruker algoritmer, inkludert maksimal entropi og betingede tilfeldige felt, for å få komplekse statistiske språkmodeller. Det er effektivt for å løse språklige betydninger sammen med andre kompleksiteter, men det trenger et stort volum treningsdata for å utføre operasjonen.
#2. Regelbaserte systemer
Denne metoden bruker forskjellige regler for å samle informasjon. Det inkluderer titler eller store bokstaver, for eksempel «Er». I denne metoden er mye menneskelig inngripen nødvendig for å gi innspill, overvåke og vri reglene. Denne metoden kan gå glipp av tekstvariasjonene som ikke er inkludert i opplæringsannoteringene. Det er derfor regelbaserte systemer ikke er i stand til å håndtere kompleksitet og maskinlæringsmodeller.
#3. Ordbokbaserte systemer
I denne metoden brukes en ordbok som inneholder en omfattende mengde synonymer og vokabularsamling for å identifisere og krysssjekke navngitte identiteter. Denne metoden har problemer med å kategorisere navngitte enheter som har forskjellige variasjoner i stavemåter.
Det er også mange andre nye NER-metoder. La oss diskutere dem også:
#4. Maskinlæringssystemer uten tilsyn
Disse ML-systemene bruker maskinlæringsmodeller som ikke er forhåndstrent på tekstdataene. De uovervåkede læringsmodellene er mer i stand til å utføre komplekse jobber enn veiledede modeller.
#5. Bootstrapping-systemer
Bootstrapping-systemer er også kjent som selvovervåkede systemer som kategoriserer de navngitte enhetene avhengig av grammatiske egenskaper, inkludert deler av talemerker, store bokstaver og andre forhåndstrente kategorier.
Et menneske justerer deretter bootstrap-systemet ved å merke systemets spådommer som feil eller korrekte og legge til de riktige i det nye treningssettet.
#6. Nevrale nettverkssystemer
Den bygger Named Entity Recognition-modellen ved å bruke toveis arkitekturlæringsmodeller (toveis koderepresentasjoner fra transformatorer), nevrale nettverk og kodingsteknikker. Denne metoden minimerer menneskelig interaksjon.
#7. Statistiske systemer
Denne metoden bruker sannsynlighetsmodeller som er trent på tekstlige sammenhenger og mønstre. Det hjelper enkelt å forutsi navngitte enheter fra nye tekstbaserte data.
#8. Semantiske rollemerkingssystemer
Dette systemet forhåndsbehandler en Named Entity Recognition-modell ved å bruke de semantiske læringsteknikkene som lærer forholdet mellom kategoriene og konteksten.
#9. Hybride systemer
Denne metoden er interessant som bruker aspekter av flere tilnærminger på en kombinert måte.
Fordeler med NER
NER-modeller gir mange fordeler.
- NER automatiserer datautvinningsprosessen for et stort datavolum.
- Den brukes i alle bransjer for å trekke ut nøkkelinformasjon fra en ustrukturert tekst.
- Dette kan spare deg og dine ansatte for tid til å utføre datautvinningsoppgaver.
- Det kan forbedre nøyaktigheten til NLP-prosesser og -oppgaver.
- Det sikrer datasikkerhet ved å være vert for tilpassede NER-modeller, og eliminerer behovet for å dele sensitiv informasjon med tredjepartsleverandører.
- Den tar imot nye enhetstyper og terminologier etter hvert som domenet utvikler seg.
Utfordringer til NER
- Tvetydighet: Mange ord som brukes i teksten kan være villedende. For eksempel refererer ordet «Amazon» til et selskap, en elv og en skog. Det kan differensieres av en bestemt kontekst. Dermed gjør dette enhetsgjenkjenning litt vanskeligere.
- Kontekstavhengighet: Ord avledet fra konteksten rundt har forskjellig betydning; for eksempel refererer «Eple» i en teknologibasert tekst til selskapet, mens det i omgivelsene refererer til frukt. Det er ikke vanskelig å gjenkjenne en nøyaktig enhet.
- Datasparsomhet: For ML-baserte NER-metoder er tilgjengeligheten av merkede data avgjørende. Å trekke ut slike data, spesielt for spesialiserte domener eller mindre vanlige språk, kan imidlertid være utfordrende.
- Språkvariasjoner: Menneskelige språk har forskjellige former avhengig av deres dialekter, regionale forskjeller og slang. Derfor er det vanskelig å trekke ut den fremmedspråklige teksten.
- Modellgeneralisering: NER-modellene kan utmerke seg ved å klassifisere enheter i et enkelt domene, men kan forvirre generalisering i et annet domene. Så NER-modeller kan oppføre seg forskjellig på tvers av forskjellige domener.
Disse utfordringene kan løses hvis du kombinerer avanserte algoritmer, språklig ekspertise og kvalitetsdata. Siden NER utvikler seg, må forsknings- og utviklingsteam foredle ulike teknikker for å takle disse utfordringene.
Brukstilfeller av NER
#1. Kategorisering av innhold

Publiserings- og nyhetshus genererer et stort volum av nettinnhold. Så det er avgjørende å administrere dem effektivt for å få mest mulig ut av en artikkel eller en nyhet.
Named Entity Recognition skanner hele innholdet automatisk og trekker ut data som organisasjoner, steder og personnavn som brukes i innholdet. Å kjenne de nødvendige kodene for hver artikkel hjelper deg med å kategorisere artikler i det definerte hierarkiet, og forbedre innholdsleveringen.
#2. Søkealgoritmer
Anta at du har en intern søkealgoritme for nettutgiveren din som inneholder millioner av artikler. For hvert søk ender den interne søkealgoritmen opp med å samle alle ordene fra disse artiklene. Dette er en tidkrevende prosess.
Nå, hvis du bruker NER for din online utgiver, vil den enkelt hente de essensielle enhetene fra alle artiklene og lagre dem separat. Dette vil fremskynde søkeprosessen.
#3. Innholdsanbefalinger
Automatisering av anbefalingsprosessen er et stort bruksområde for NER. Anbefalingssystemer veileder i oppdagelse av nye ideer og innhold.
Netflix er det beste eksemplet på dette. Det er et bevis på at å bygge et effektivt anbefalingssystem hjelper deg å bli mer avhengighetsskapende og engasjerende.
For nyhetsutgivere jobber NER effektivt med å anbefale lignende artikler. Dette kan gjøres ved å samle tagger fra en spesifikk artikkel og anbefale annet innhold som har lignende enheter.
#4. Kundeservice

For hver organisasjon er kundestøtte en viktig ting. Det er derfor det er flere måter å gjøre funksjonen til kundetilbakemeldinger smidig. NER er en av dem. La oss forstå dette med et eksempel.
Anta at en kunde gir tilbakemelding «Ansatte i Adidas outlet-butikk i San Diego mangler finere detaljer om sportssko.» Her trekker NER ut merkelappene «San Diego» (sted) og «sportssko» (produkt).
Dermed brukes NER til å klassifisere hver klage og sende den til den respektive avdelingen i organisasjonen for å håndtere problemet. Du kan utvikle en database bestående av tilbakemeldinger som er kategorisert i ulike avdelinger og analysere hver tilbakemelding.
#5. Forskningsartikler
En nettpublikasjon eller et tidsskriftnettsted inneholder mange vitenskapelige artikler og forskningsartikler. Du kan finne hundrevis av artikler som ligner lignende emner med små endringer. Så det kan være en komplisert oppgave å organisere alle disse dataene på en strukturert måte.
For å hoppe over den lange prosessen, kan du skille disse papirene basert på de relevante kodene.
For eksempel er det tusenvis av artikler om maskinlæring. For å finne den som nevnte bruken av konvolusjonelle nevrale nettverk (CNN), må du sette enheter på dem. Dette vil hjelpe deg å finne artikkelen raskt i henhold til dine krav.
Konklusjon
NLP-teknikken, Named Entity Recognition (NER), hjelper til med å identifisere navngitte enheter i en ustrukturert tekst og kategorisere disse enhetene i forhåndsdefinerte grupper som lokasjoner, personnavn, produkter og mer.
Hovedmålet til NER er å samle strukturert informasjon fra en ustrukturert tekst og representere den i et lesbart format. Det involverer ulike modeller og prosesser og gir mange fordeler for fagfolk og bedrifter. Den brukes også til forskjellige applikasjoner bortsett fra NLP.
Jeg håper du forstår forklaringen ovenfor om denne teknikken for å kunne implementere dette i din virksomhet og få relevant, verdifull informasjon i tide.
Du kan også utforske noen beste NLP-kurs for å lære naturlig språkbehandling